Модели машинного обучения и их интерпретация#
Материалы для самостоятельного изучения Деревья решений (Decision Trees) и Ансамблевые методы: Градиентный бустинг, случайные леса, бэггинг, метод голосования, стекинг, Как интерпретировать предсказания моделей в SHAP
Что такое SHAP#
SHAP (SHapley Additive exPlanations) — это теоретико-игровой подход к объяснению результатов работы любой модели машинного обучения. Он связывает оптимальное распределение кредитов с локальными объяснениями, используя классические значения Шепли из теории игр и связанные с ними расширения.
В библиотеке SHAP для оценки важности фичей рассчитываются значения Шэпли (по имени американского математика и названа библиотека).
Для оценки важности фичи происходит оценка предсказаний модели с и без данной фичи.
SHAP можно установить из PyPI
pip install shap
Пример загрузки пользовательской древовидной модели в SHAP#
В этом разделе показано, как передать пользовательскую древовидную модель в SHAP для объяснения.
import graphviz
import numpy as np
import scipy
import sklearn
import shap
Простая регрессионная древовидная модель#
Здесь мы определяем простое дерево регрессии, а затем загружаем его в SHAP как пользовательскую модель.
X, y = shap.datasets.adult()
orig_model = sklearn.tree.DecisionTreeRegressor(max_depth=2)
orig_model.fit(X, y)
dot_data = sklearn.tree.export_graphviz(orig_model, out_file=None, filled=True, rounded=True, special_characters=True)
graph = graphviz.Source(dot_data)
graph
Дополнительную информацию о том, что именно означают эти атрибуты, можно найти в документации scikit-learn
# Извлекаем массивы, описывающие структуру дерева
children_left = orig_model.tree_.children_left
children_right = orig_model.tree_.children_right
children_default = children_right.copy() # в scikit-learn отсутствует обработка пропущенных значений, поэтому используем правое поддерево по умолчанию
features = orig_model.tree_.feature
thresholds = orig_model.tree_.threshold
values = orig_model.tree_.value.reshape(orig_model.tree_.value.shape[0], 1)
node_sample_weight = orig_model.tree_.weighted_n_node_samples
print(" children_left", children_left) # отрицательное значение означает, что узел является листом
print(" children_right", children_right)
print(" children_default", children_default)
print(" features", features)
print(" thresholds", thresholds.round(3)) # значение -2 указывает, что узел является листом
print(" values", values.round(3))
print("node_sample_weight", node_sample_weight)
# Определение пользовательской модели дерева в виде словаря
tree_dict = {
"children_left": children_left, # индексы левых дочерних узлов
"children_right": children_right, # индексы правых дочерних узлов
"children_default": children_default, # индексы дочерних узлов по умолчанию (в sklearn равны правым, так как отсутствуют пропущенные значения)
"features": features, # индекс признака, по которому происходит разбиение в каждом узле
"thresholds": thresholds, # пороговое значение для разбиения
"values": values, # значения, предсказываемые в узлах (например, средние значения по классам)
"node_sample_weight": node_sample_weight, # количество (взвешенных) объектов, попавших в каждый узел
}
# Представление модели в виде словаря, содержащего одно дерево
model = {"trees": [tree_dict]}
explainer = shap.TreeExplainer(model)
# Убедимся, что интерпретатор SHAP (модель TreeEnsemble) выдаёт те же предсказания,
# что и исходная модель
assert np.abs(explainer.model.predict(X) - orig_model.predict(X)).max() < 1e-4
# Убедимся, что сумма SHAP-значений даёт точное значение прогноза модели
# (свойство локальной точности: сумма вкладов признаков плюс базовое значение равна предсказанию)
assert np.abs(explainer.expected_value + explainer.shap_values(X).sum(1) - orig_model.predict(X)).max()
Объяснение потери древовидной модели#
Интерпретация функции потерь модели может оказаться весьма полезной как для отладки, так и для мониторинга качества обучения.
В этом блокноте приводится простой пример того, как работает такой подход.
Обратите внимание: объяснение функции потерь требует передачи истинных меток (
labels) и поддерживается только при использовании параметраfeature_perturbation="independent"вTreeExplainer.
Полное описание метода будет представлено позже, вместе с более подробным примером.
import numpy as np
import xgboost
import shap
Обучение классификатор XGBoost#
X, y = shap.datasets.adult()
model = xgboost.XGBClassifier()
model.fit(X, y)
model_loss = -np.log(model.predict_proba(X)[:, 1]) * y + -np.log(model.predict_proba(X)[:, 0]) * (1 - y)
model_loss[:10]
Объясние логарифмической потери модели с помощью TreeExplainer#
Обратите внимание:
expected_valueдля функции потерь модели зависит от значения метки (label),
поэтому вместо одного числового значения это теперь функция, возвращающая значение в зависимости от конкретной метки.
explainer = shap.TreeExplainer(model, X, feature_perturbation="interventional", model_output="log_loss")
explainer.shap_values(X.iloc[:10, :], y[:10]).sum(1) + np.array([explainer.expected_value(v) for v in y[:10]])
Вывод
array([8.43887488e-04, 2.47898585e-01, 1.17997435e-02, 7.11527711e-02,
6.41849874e-01, 1.76084475e+00, 5.70285151e-03, 8.60033255e-01,
4.78233521e-04, 6.43796897e-03])
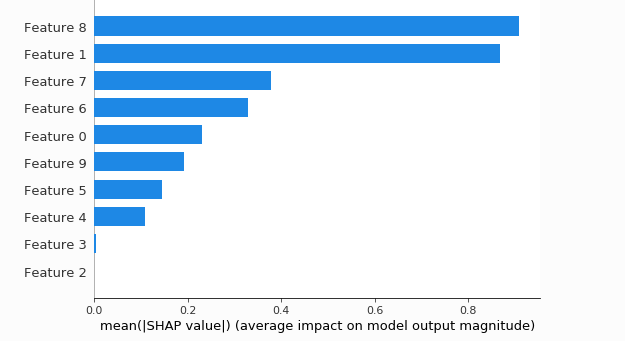
Сводная гистограмма показывает общую значимость каждого признака#
shap_values = shap.TreeExplainer(model).shap_values(X_test)
shap_interaction_values = shap.TreeExplainer(model).shap_interaction_values(X_test)
shap.summary_plot(shap_values, X_test, plot_type="bar")
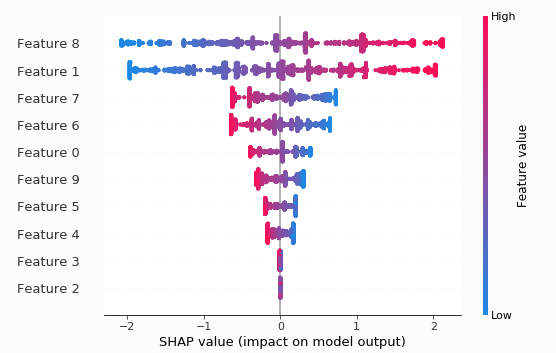
Сводный график показывает глобальную значимость каждой характеристики и распределение величин эффекта#
Сводный график показывает глобальную значимость каждой характеристики и распределение величин эффекта
shap.summary_plot(shap_values, X_test)
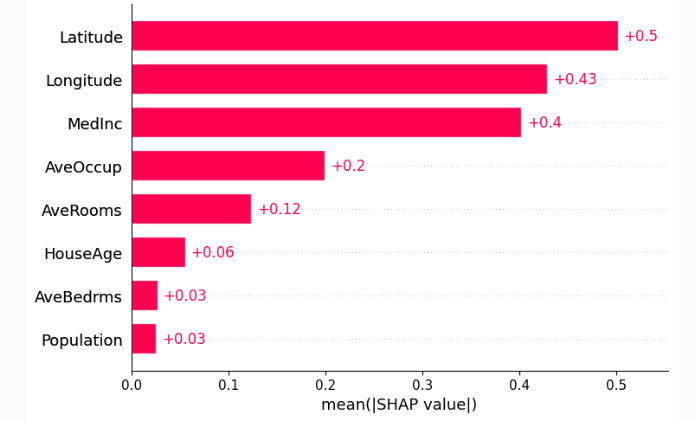
Еще несколько примеров визуализации#
Код из примера на главной странице с использованием XGBoost.
import xgboost
import shap
# Загрузка данных по ценам на жильё в Калифорнии
X, y = shap.datasets.california()
# Обучение модели XGBoost на этих данных
model = xgboost.XGBRegressor().fit(X, y)
# Построение интерпретатора SHAP для модели
# (тот же синтаксис работает для моделей LightGBM, CatBoost, scikit-learn, HuggingFace, Spark и др.)
explainer = shap.Explainer(model)
# Расчёт SHAP-значений для всех объектов в выборке
shap_values = explainer(X)
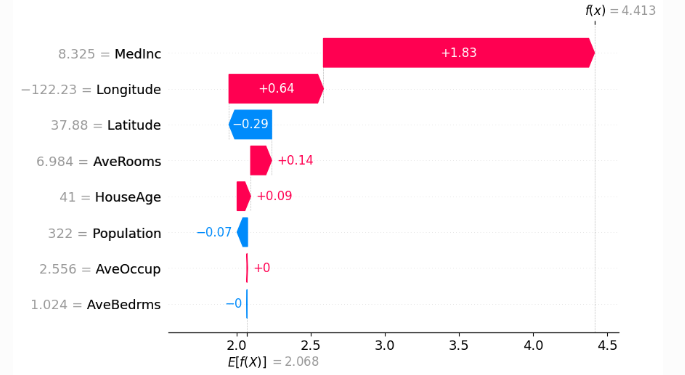
# Визуализация объяснения для первого объекта (waterfall-график)
shap.plots.waterfall(shap_values[0])
shap.plots.initjs()
# визуализируем объяснение первого прогноза
shap.plots.force(shap_values[0])

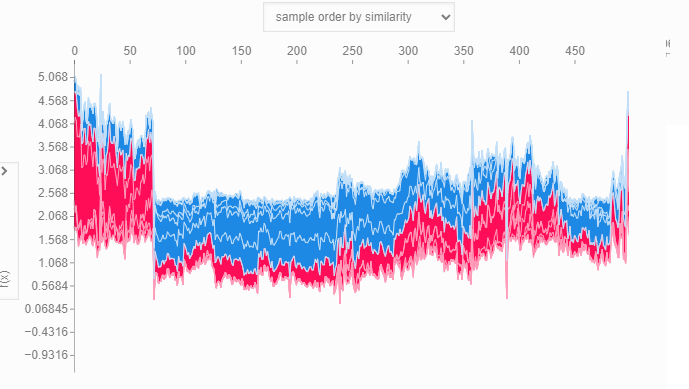
# визуализируем все прогнозы по обучающей выборке
shap.plots.force(shap_values[:500])
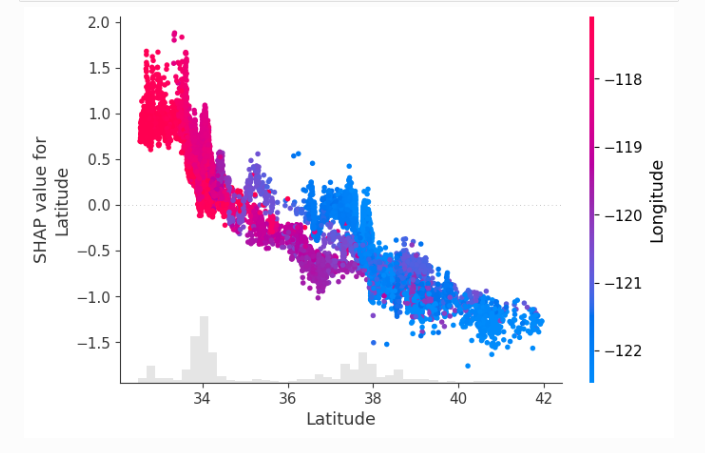
# создаём точечную диаграмму зависимости, чтобы показать влияние одного признака на весь набор данных
shap.plots.scatter(shap_values[:, "Latitude"], color=shap_values)
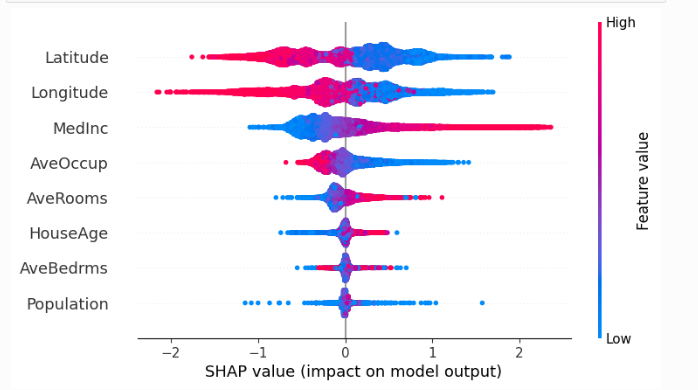
#суммируем влияние всех признаков
shap.plots.beeswarm(shap_values)
shap.plots.bar(shap_values)