Pandas - моделирование признаков#
Тестовый набор данных, если вы не собрали свой
Прежде чем начать, необходимо выполнить все импорты, как вы уже делали в предыдущем уроке,
а также использовать магию IPython, чтобы графики отображались внутри Jupyter Notebook,
и задать стиль визуализации.
Затем можно загрузить данные и сохранить целевую переменную из обучающей выборки в надёжном месте.
После этого объедините обучающую и тестовую выборки (за исключением столбца 'Survived' из df_train)
и сохраните результат в переменную data.
Помните, что вы делаете это для того, чтобы любые операции предварительной обработки,
которые вы применяете к данным, одинаково затрагивали как обучающую, так и тестовую выборки!
Наконец, используйте метод .info(), чтобы получить общее представление о данных.
# Импорт библиотек
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import re
import numpy as np
from sklearn import tree
from sklearn.model_selection import GridSearchCV
# Отображение графиков внутри Jupyter Notebook и установка стиля визуализации
%matplotlib inline
sns.set()
# Импорт данных
df_train = pd.read_csv('data/train.csv')
df_test = pd.read_csv('data/test.csv')
# Сохранение целевой переменной обучающей выборки в отдельное место
survived_train = df_train.Survived
# Объединение обучающей и тестовой выборок (кроме столбца 'Survived' из df_train)
data = pd.concat([df_train.drop(['Survived'], axis=1), df_test])
# Просмотр общей информации о данных
data.info()
## Вывод
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1309 entries, 0 to 417
Data columns (total 11 columns):
PassengerId 1309 non-null int64
Pclass 1309 non-null int64
Name 1309 non-null object
Sex 1309 non-null object
Age 1046 non-null float64
SibSp 1309 non-null int64
Parch 1309 non-null int64
Ticket 1309 non-null object
Fare 1308 non-null float64
Cabin 295 non-null object
Embarked 1307 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 122.7+ KB
Зачем вообще заниматься созданием признаков?
Вы выполняете создание признаков, чтобы извлечь из данных больше информации и тем самым повысить качество построения моделей.
Заголовки пассажиров Титаника#
Давайте посмотрим, о чём идёт речь, на примере. Посмотрим на столбец 'Name' с помощью метода .tail(), который позволяет увидеть последние пять строк ваших данных:
data.Name.tail()
## Вывод
413 Spector, Mr. Woolf
414 Oliva y Ocana, Dona. Fermina
415 Saether, Mr. Simon Sivertsen
416 Ware, Mr. Frederick
417 Peter, Master. Michael J
Name: Name, dtype: object
Вдруг вы замечаете, что появляются разные титулы! Иными словами, этот столбец содержит строки или текст, в которых есть титулы, такие как «Mr», «Master» и «Dona».
Эти титулы, конечно, дают информацию о социальном статусе, профессии и так далее, что в конечном итоге может рассказать вам что-то важное о выживании.
На первый взгляд может показаться сложной задачей отделить имена от титулов, но не волнуйтесь! Помните, что вы легко можете использовать регулярные выражения, чтобы извлечь титул и сохранить его в новом столбце 'Title':
# Извлечение титула из имени, сохранение в новый столбец и построение столбчатой диаграммы
data['Title'] = data.Name.apply(lambda x: re.search(' ([A-Z][a-z]+)\.', x).group(1))
sns.countplot(x='Title', data=data)
plt.xticks(rotation=45)
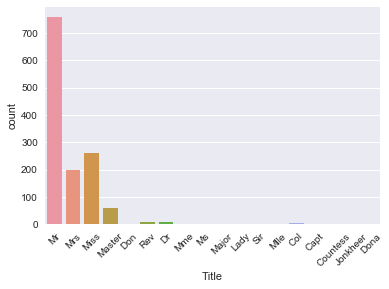
Обратите внимание, что этот новый столбец 'Title' — фактически новый признак в вашем наборе данных!
Совет: чтобы узнать больше о регулярных выражениях, пройдите в раздел по регулярным выражениям на Python
На графике видно, что есть несколько различных титулов, при этом многие встречаются редко. Поэтому имеет смысл сгруппировать их в меньшее количество категорий.
Например, вероятно, стоит заменить 'Mlle' и 'Ms' на 'Miss', а 'Mme' — на 'Mrs', так как это французские титулы, а желательно, чтобы все данные были на одном языке. Далее можно взять несколько титулов, которые сложно сразу классифицировать, и объединить их в категорию 'Special'.
Совет: поэкспериментируйте с этим, чтобы посмотреть, как это повлияет на работу вашего алгоритма!
Далее вы строите столбчатую диаграмму результата с помощью метода .countplot():
data['Title'] = data['Title'].replace({'Mlle':'Miss', 'Mme':'Mrs', 'Ms':'Miss'})
data['Title'] = data['Title'].replace(['Don', 'Dona', 'Rev', 'Dr',
'Major', 'Lady', 'Sir', 'Col', 'Capt', 'Countess', 'Jonkheer'],'Special')
sns.countplot(x='Title', data=data)
plt.xticks(rotation=45)
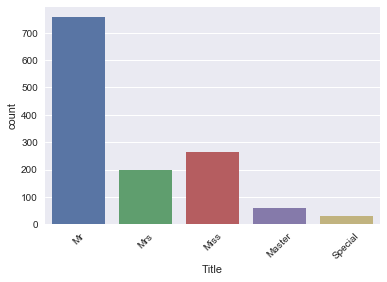
Вот как выглядит ваш недавно созданный признак 'Title'!
Теперь убедитесь, что у вас есть столбец 'Title' и снова посмотрите на данные с помощью метода .tail():
data.tail()
| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Title |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 413 | 3 | Spector, Mr. Woolf | male | NaN | 0 | 0 | A.5. 3236 | 8.0500 | NaN | S | Mr |
| 414 | 1 | Oliva y Ocana, Dona. Fermina | female | 39.0 | 0 | 0 | PC 17758 | 108.9000 | C105 | C | Special |
| 415 | 3 | Saether, Mr. Simon Sivertsen | male | 38.5 | 0 | 0 | SOTON/O.Q. 3101262 | 7.2500 | NaN | S | Mr |
| 416 | 3 | Ware, Mr. Frederick | male | NaN | 0 | 0 | 359309 | 8.0500 | NaN | S | Mr |
| 417 | 3 | Peter, Master. Michael J | male | NaN | 1 | 1 | 2668 | 22.3583 | NaN | C | Master |
Каюты пассажиров#
Когда вы загрузили данные и посмотрели их, вы заметили, что в столбце 'Cabin' присутствует множество пропущенных значений (NaN).
Можно предположить, что эти NaN означают отсутствие каюты у пассажира, что может нести информацию о выживании. Поэтому давайте создадим новый столбец 'Has_Cabin', который будет кодировать эту информацию — есть ли у пассажира каюта или нет.
Обратите внимание, что в приведённом ниже коде используется метод .isnull(), который возвращает True, если у пассажира нет каюты, и False — если каюта есть. Однако, поскольку мы хотим сохранить в столбце 'Has_Cabin' значение True, когда каюта есть, результат нужно инвертировать. Для этого используется оператор тильда ~.
# Была ли у пассажира каюта?
data['Has_Cabin'] = ~data.Cabin.isnull()
# Просмотр первых строк данных
data.head()
| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Title | Has_Cabin |
|-------------|--------|----------------------------------------------|--------|------|-------|-------|-------------------|---------|-------|----------|-------|-----------|
| 0 | 1 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | Mr | False |
| 1 | 2 | Cumings, Mrs. John Bradley (Florence Briggs Th...) | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | Mrs | True |
| 2 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | Miss | False |
| 3 | 4 | Futrelle, Mrs. Jacques Heath (Lily May Peel)| female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | Mrs | True |
| 4 | 5 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | Mr | False |
Теперь нужно удалить несколько столбцов, которые не содержат полезной информации (или мы не знаем, как с ними работать). В данном случае это столбцы ['Cabin', 'Name', 'PassengerId', 'Ticket'], потому что:
- Информацию о наличии каюты вы уже выделили в новом столбце
'Has_Cabin'; - Извлекли титулы из столбца
'Name'; - Столбцы
'PassengerId'и'Ticket'скорее всего не дадут дополнительной информации о выживании пассажиров Титаника.
Подсказка: в столбце 'Cabin' может содержаться больше информации, но в этом уроке мы считаем, что её там нет.
Чтобы удалить эти столбцы из DataFrame data, используйте метод .drop() с аргументом inplace=True:
# Удаляем столбцы и смотрим первые строки
data.drop(['Cabin', 'Name', 'PassengerId', 'Ticket'], axis=1, inplace=True)
data.head()
| Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | Title | Has_Cabin |
|---|---|---|---|---|---|---|---|---|
| 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Mr | False |
| 1 | female | 38.0 | 1 | 0 | 71.2833 | C | Mrs | True |
| 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Miss | False |
| 1 | female | 35.0 | 1 | 0 | 53.1000 | S | Mrs | True |
| 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Mr | False |
Поздравляем! Вы успешно создали новые признаки, такие как 'Title' и 'Has_Cabin', и удалили из DataFrame те признаки, которые не несут полезной информации для вашей модели машинного обучения.
Далее нужно обработать пропущенные значения, разбить числовые данные на интервалы (биннинг) и снова преобразовать все признаки в числовые с помощью метода .get_dummies(). В конце вы построите итоговую модель для этого урока.
Посмотрите, как всё это делается в следующих разделах!
Обработка пропущенных значений#
После всех изменений в вашем исходном DataFrame полезно проверить, остались ли пропущенные значения, используя метод .info():
data.info()
## Вывод
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1309 entries, 0 to 417
Data columns (total 9 columns):
Pclass 1309 non-null int64
Sex 1309 non-null object
Age 1046 non-null float64
SibSp 1309 non-null int64
Parch 1309 non-null int64
Fare 1308 non-null float64
Embarked 1307 non-null object
Title 1309 non-null object
Has_Cabin 1309 non-null bool
dtypes: bool(1), float64(2), int64(3), object(3)
memory usage: 133.3+ KB
Результат выполнения предыдущей команды показывает, что в столбцах 'Age', 'Fare' и 'Embarked' есть пропущенные значения.
Обратите внимание, что это легко заметить, сравнив общее число записей (1309) с количеством ненулевых значений в каждом столбце, которое выводит .info(). Например, в 'Age' — 1046 ненулевых значений, значит, пропущено 263 значения. В 'Fare' отсутствует только одно значение, а в 'Embarked' — два.
Как и в предыдущем уроке, вы заполните пропуски с помощью метода .fillna().
Обратите внимание, что для заполнения столбцов 'Age' и 'Fare' используется медиана, поскольку она лучше справляется с выбросами. Альтернативно можно использовать среднее (сумма всех значений, делённая на их количество) или моду — наиболее часто встречающееся значение.
Пропущенные значения в столбце 'Embarked' заполняются значением 'S' (Southampton), так как это наиболее частое значение в данном столбце.
Совет: вы можете перепроверить это, проведя дополнительный разведочный анализ данных (Exploratory Data Analysis).
# Заполнение пропущенных значений в столбцах Age, Fare, Embarked
data['Age'] = data.Age.fillna(data.Age.median())
data['Fare'] = data.Fare.fillna(data.Fare.median())
data['Embarked'] = data['Embarked'].fillna('S')
data.info()
## Вывод
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1309 entries, 0 to 417
Data columns (total 9 columns):
Pclass 1309 non-null int64
Sex 1309 non-null object
Age 1309 non-null float64
SibSp 1309 non-null int64
Parch 1309 non-null int64
Fare 1309 non-null float64
Embarked 1309 non-null object
Title 1309 non-null object
Has_Cabin 1309 non-null bool
dtypes: bool(1), float64(2), int64(3), object(3)
memory usage: 133.3+ KB
data.head()
| Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | Title | Has_Cabin |
|---|---|---|---|---|---|---|---|---|
| 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Mr | False |
| 1 | female | 38.0 | 1 | 0 | 71.2833 | C | Mrs | True |
| 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Miss | False |
| 1 | female | 35.0 | 1 | 0 | 53.1000 | S | Mrs | True |
| 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Mr | False |
Дискретизация числовых данных#
Далее вы хотите разбить числовые данные на интервалы, так как у вас есть разброс значений возраста и стоимости билета. Однако в этих числах могут быть колебания, которые не отражают закономерностей в данных, а скорее являются шумом. Поэтому вы поместите людей, возраст или стоимость билета которых попадает в определённый диапазон, в одну категорию — интервал (бин).
Для этого используйте функцию pandas qcut(), которая разбивает числовые данные на квантили:
data['CatAge'] = pd.qcut(data.Age, q=4, labels=False )
data['CatFare']= pd.qcut(data.Fare, q=4, labels=False)
data.head()
После биннинга числовых данных создаются новые категориальные признаки, которые можно обозначить, например, как CatAge и CatFare. В этих столбцах содержатся номера интервалов, к которым относятся значения возраста и стоимости билета.
Вот пример данных с добавленными бинами:
| Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | Title | Has_Cabin | CatAge | CatFare |
|---|---|---|---|---|---|---|---|---|---|---|
| 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Mr | False | 0 | 0 |
| 1 | female | 38.0 | 1 | 0 | 71.2833 | C | Mrs | True | 3 | 3 |
| 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Miss | False | 1 | 1 |
| 1 | female | 35.0 | 1 | 0 | 53.1000 | S | Mrs | True | 2 | 3 |
| 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Mr | False | 2 | 1 |
Обратите внимание, что в функцию qcut() вы передаете данные в виде серии — data.Age и data.Fare, затем указываете количество квантилей — q=4. Аргумент labels=False задает числовое кодирование для бинов.
Теперь, когда у вас есть бины с этой информацией, можно смело удалить исходные столбцы Age и Fare.
Не забудьте посмотреть первые пять строк вашего DataFrame!
data = data.drop(['Age', 'Fare'], axis=1)
data.head()
| Pclass | Sex | SibSp | Parch | Embarked | Title | Has_Cabin | CatAge | CatFare |
|---|---|---|---|---|---|---|---|---|
| 3 | male | 1 | 0 | S | Mr | False | 0 | 0 |
| 1 | female | 1 | 0 | C | Mrs | True | 3 | 3 |
| 3 | female | 0 | 0 | S | Miss | False | 1 | 1 |
| 1 | female | 1 | 0 | S | Mrs | True | 2 | 3 |
| 3 | male | 0 | 0 | S | Mr | False | 2 | 1 |
Количество членов семьи на борту#
Следующее, что можно сделать — создать новый столбец, который показывает количество членов семьи, находившихся на борту Титаника. В этом уроке мы не будем использовать эту переменную, чтобы посмотреть, как модель работает без неё. Но если хотите проверить, как модель будет работать с этим столбцом, выполните следующий код:
# Создание столбца с количеством членов семьи на борту
data['Fam_Size'] = data.Parch + data.SibSp
Пока что удалим столбцы
'SibSp' и 'Parch' из DataFrame
data = data.drop(['SibSp', 'Parch'], axis=1)
data.head()
| Pclass | Sex | Embarked | Title | Has_Cabin | CatAge | CatFare |
|---|---|---|---|---|---|---|
| 3 | male | S | Mr | False | 0 | 0 |
| 1 | female | C | Mrs | True | 3 | 3 |
| 3 | female | S | Miss | False | 1 | 1 |
| 1 | female | S | Mrs | True | 2 | 3 |
| 3 | male | S | Mr | False | 2 | 1 |
Преобразование строковых переменных в числовые#
Теперь, когда вы создали дополнительные признаки, такие как 'Title' и 'Has_Cabin', обработали пропущенные значения и разбили числовые данные на категории, пришло время преобразовать все переменные в числовые. Это необходимо, потому что модели машинного обучения обычно принимают на вход числовые данные.
Как и раньше, для этого используйте метод .get_dummies():
# Преобразование в бинарные переменные
data_dum = pd.get_dummies(data, drop_first=True)
data_dum.head()
| Pclass | Has_Cabin | CatAge | CatFare | Sex_male | Embarked_Q | Embarked_S | Title_Miss | Title_Mr | Title_Mrs | Title_Special |
|---|---|---|---|---|---|---|---|---|---|---|
| 3 | False | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 |
| 1 | True | 3 | 3 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 3 | False | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 |
| 1 | True | 2 | 3 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
| 3 | False | 2 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 |
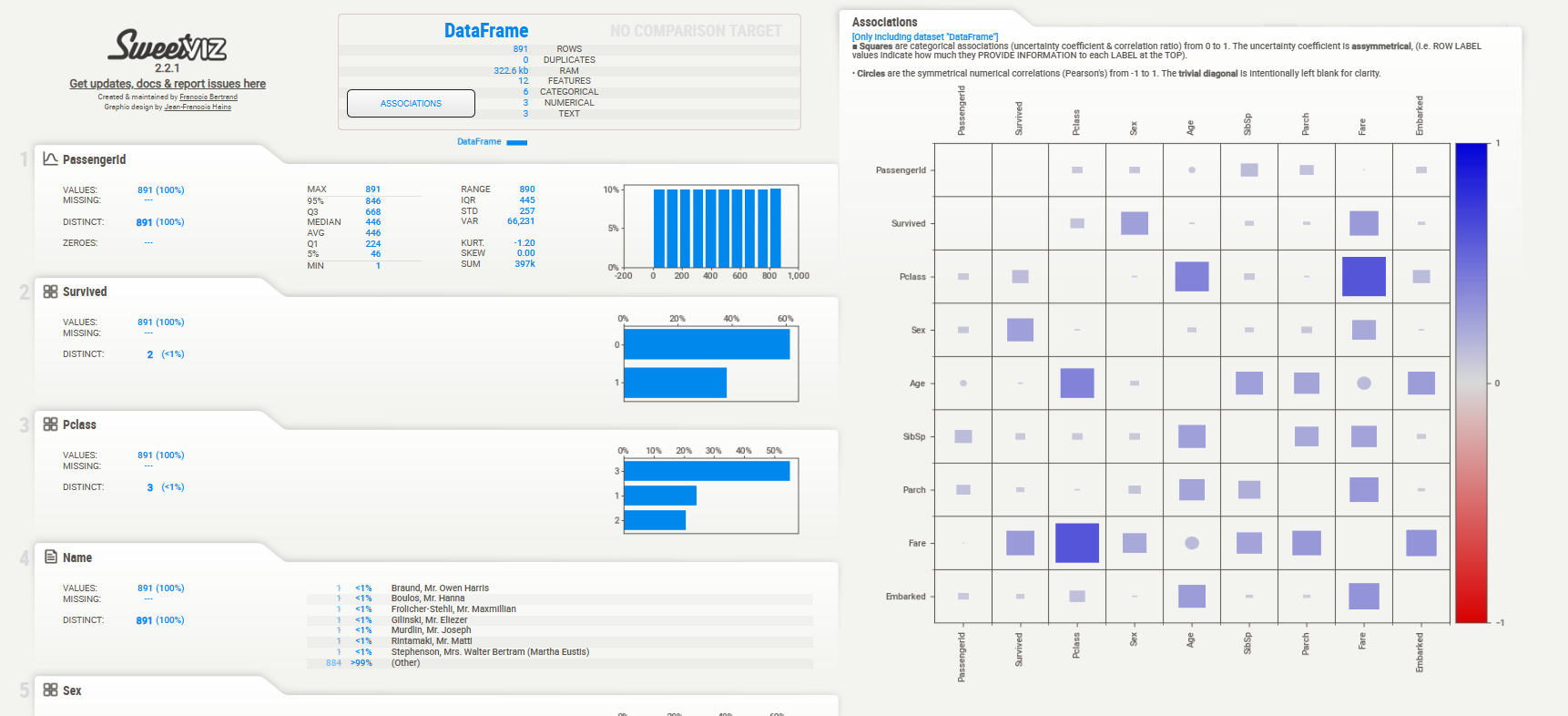
Средства визуализации. Дополнение.#
Sweetviz — это библиотека для анализа и визуализации данных на основе pandas DataFrame. Она позволяет быстро создавать красивые и информативные интерактивные отчёты, которые помогают понять структуру данных, выявить аномалии и сравнить разные наборы данных.
Основные возможности Sweetviz:
- Автоматический анализ статистики каждого столбца (числовые, категориальные данные).
- Визуализация распределения значений, пропусков и уникальных данных.
- Сравнение двух наборов данных (например, тренировочного и тестового) с визуализацией различий.
- Генерация интерактивного HTML-отчёта с графиками и сводной информацией.
Использование его крайне просто. Ниже придставлен код.
import sweetviz as sv
import pandas as pd
df = pd.read_csv('your_data.csv')
report = sv.analyze(df)
report.show_html('report.html')