Pandas - Руководство к использованию#
Тестовый набор данных, если вы не собрали свой
Какие данные обрабатывает pandas?#
Note
Pandas - самая популярная библиотека для работы с таблицами в python. pandas — сторонняя библиотека, а значит требует дополнительной установки в общем случае, но входит в дистрибутив anaconda.
import pandas as pd
Чтобы загрузить пакет pandas и начать с ним работать, импортируйте его. Сообщество согласовало псевдоним pd для pandas, поэтому загрузка pandas как pd считается стандартной практикой для всей документации pandas.
Представление таблицы данных pandas#
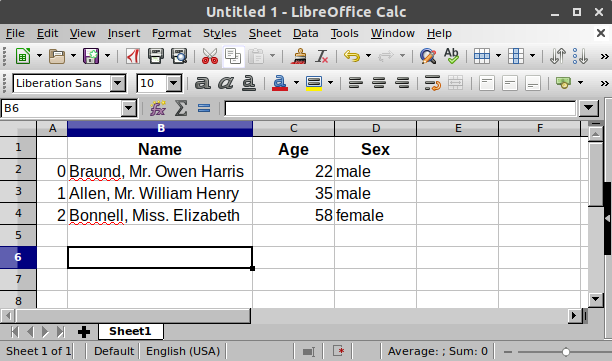
Я хочу сохранить данные пассажиров Титаника. Для ряда пассажиров мне известны данные об именах (characters), возрасте (integers) и поле (male/female).

df = pd.DataFrame(
{
"Name": [
"Braund, Mr. Owen Harris",
"Allen, Mr. William Henry",
"Bonnell, Miss. Elizabeth",
],
"Age": [22, 35, 58],
"Sex": ["male", "male", "female"],
}
)
df
# Name Age Sex
# Braund, Mr. Owen Harris 22 male
# Allen, Mr. William Henry 35 male
# Bonnell, Miss. Elizabeth 58 female
Чтобы вручную сохранить данные в таблице, создайте DataFrame. При использовании словаря списков Python ключи словаря будут использоваться как заголовки столбцов, а значения в каждом списке — как столбцы DataFrame.
Класс DataFrame — это двумерная структура данных, которая может хранить в столбцах данные разных типов, включая символы, целые числа, значения с плавающей запятой, категориальные данные и так далее. Это похоже на электронную таблицу Excel, таблицу SQL или data.frame в R.
-
В таблице три столбца, каждый из которых имеет метку. Метки столбцов соответственно
Name,AgeиSex. -
Столбец
Nameсостоит из текстовых данных, где каждое значение представляет собой строку, столбецAgeпредставляет собой числа, а столбецSexпредставляет собой текстовые данные.
В программном обеспечении для работы с электронными таблицами табличное представление наших данных будет выглядеть очень похоже:
Каждый столбец в DataFrame представляет собой Series#

Меня интересует работа с данными только в столбце Age.
df["Age"]
# 0 22
# 1 35
# 2 58
# Name: Age, dtype: int64
При выборе одного столбца pandas DataFrame результатом будет Series. Чтобы выбрать столбец, используйте метку столбца в квадратных скобках [].
Tip
Если вы знакомы со словарями Python, выбор одного столбца очень похож на выбор значений словаря на основе ключа.
Вы также можете создать Series с нуля:
ages = pd.Series([22, 35, 58], name="Age")
ages
# Out[6]:
# 0 22
# 1 35
# 2 58
# Name: Age, dtype: int64
У
Series в pandas нет меток столбцов, так как это всего лишь один столбец DataFrame. Метки строк в Series есть.
Действия над DataFrame или Series#
Я хочу знать максимальный возраст пассажиров
Мы можем сделать это в DataFrame, выбрав столбец Age и применив max():
df["Age"].max()
# 58
Или к Series:
ages.max()
# Out[8]: 58
Как показано на примере метода max(), вы можете делать что-либо с DataFrame или Series. pandas предоставляет множество функций, каждая из которых представляет собой метод, который вы можете применить к DataFrame или Series. Поскольку методы являются функциями, не забывайте использовать круглые скобки ().
Меня интересуют некоторые основные статистические показатели числовых данных моей таблицы
df.describe()
Метод describe() обеспечивает краткий обзор числовых данных в DataFrame. Поскольку столбцы Name и Sex являются текстовыми данными, они по умолчанию не учитываются методом describe().
Question
Проверьте дополнительные параметры describe в разделе руководства пользователя об обобщениях с помощью describe.
Запомните
ЗАПОМНИТЕ
Импорт пакета: import pandas as pd.
Таблица данных в pandas хранится как DataFrame.
Каждый столбец в DataFrame представляет собой Series
Вы можете применять методы к DataFrame или Series.
Как читать и записывать табличные данные?#
import pandas as pd
Данные, использованные в этом уроке:
В этом руководстве используется набор данных Titanic, сохраненный в формате CSV. Данные состоят из следующих столбцов:
PassengerId: Идентификатор каждого пассажира.Survived: Имеет значения 0 и 1. 0 для не выживших и 1 для выживших.Pclass: Существует 3 класса: класс 1, класс 2 и класс 3.Name: Имя пассажира.Sex: Пол пассажира.Age: Возраст пассажира.SibSp: Указание на то, что у пассажира есть братья, сестры и супруг.Parch: Пассажир один или с семьей.Ticket: Номер билета пассажира.Fare: Указание тарифа.Cabin: Каюта пассажира.Embarked: Категория причала.

Я хочу проанализировать данные о пассажирах Титаника, доступные в виде CSV-файла.
titanic = pd.read_csv("data/titanic.csv")
pandas предоставляет функцию read_csv() для чтения данных, хранящихся в виде CSV-файла, в DataFrame. pandas поддерживает множество различных форматов файлов или источников данных из коробки (csv, excel, sql, json, parquet и так далее), каждый из них имеет префикс read_*.
Всегда проверяйте данные после их чтения. При отображении DataFrame по умолчанию будут отображаться первые и последние 5 строк:
titanic
# PassengerId Survived Pclass ... Fare Cabin Embarked
# 0 1 0 3 ... 7.2500 NaN S
# 1 2 1 1 ... 71.2833 C85 C
# 2 3 1 3 ... 7.9250 NaN S
# 3 4 1 1 ... 53.1000 C123 S
# 4 5 0 3 ... 8.0500 NaN S
# .. ... ... ... ... ... ... ...
# 886 887 0 2 ... 13.0000 NaN S
# 887 888 1 1 ... 30.0000 B42 S
# 888 889 0 3 ... 23.4500 NaN S
# 889 890 1 1 ... 30.0000 C148 C
# 890 891 0 3 ... 7.7500 NaN Q
# [891 rows x 12 columns]
Я хочу увидеть первые 8 строк DataFrame.
titanic.head(8)
Чтобы просмотреть первые N строк DataFrame, используйте метод head() с требуемым количеством строк (в данном случае 8) в качестве аргумента.
Note
Интересуют последние N строк, а не первые? Используйте метод tail(). Например, titanic.tail(10) вернет последние 10 строк DataFrame.
Проверить, как pandas интерпретирует каждый из типов данных столбца, можно, запросив атрибут pandas dtypes:
titanic.dtypes
# Out[5]:
# PassengerId int64
# Survived int64
# Pclass int64
# Name object
# Sex object
# Age float64
# SibSp int64
# Parch int64
# Ticket object
# Fare float64
# Cabin object
# Embarked object
# dtype: object
Для каждого столбца указывается используемый тип данных. Типы данных в этом DataFrame: целые числа (int64), числа с плавающей запятой (float64) и строки (object).
При запросе dtypes скобки не используются! dtypes является атрибутом DataFrame и Series. Атрибуты DataFrame или Series не нуждаются в скобках. Атрибуты представляют собой характеристику DataFrame и Series, тогда как метод (который требует скобок) делает что-то с DataFrame или Series, как представлено в первом уроке.
Мой коллега запросил данные Титаника в виде электронной таблицы.
titanic.to_excel("titanic.xlsx", sheet_name="passengers", index=False)
В то время как функции read_* используются для чтения данных в pandas, методы to_* используются для хранения данных. Метод to_excel() сохраняет данные в виде файла Excel. В приведенном здесь примере sheet_name имеет значение passengers, а не предусмотренное по умолчанию Sheet1. При установке index=False в электронной таблице не сохраняются метки индексов строк.
Эквивалентная функция чтения read_excel() перезагрузит данные в DataFrame:
titanic = pd.read_excel("titanic.xlsx", sheet_name="passengers")
titanic.head()
Меня интересует техническая сводка DataFrame
titanic.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 891 entries, 0 to 890
# Data columns (total 12 columns):
# Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 PassengerId 891 non-null int64
# 1 Survived 891 non-null int64
# 2 Pclass 891 non-null int64
# 3 Name 891 non-null object
# 4 Sex 891 non-null object
# 5 Age 714 non-null float64
# 6 SibSp 891 non-null int64
# 7 Parch 891 non-null int64
# 8 Ticket 891 non-null object
# 9 Fare 891 non-null float64
# 10 Cabin 204 non-null object
# 11 Embarked 889 non-null object
# dtypes: float64(2), int64(5), object(5)
# memory usage: 83.7+ KB
Метод info() предоставляет техническую информацию о DataFrame, так что давайте объясним результаты более подробно:
Это действительно DataFrame.
- Имеется 891 запись, то есть 891 строка.
- Каждая строка имеет метку строки
(index)со значениями в диапазоне от 0 до 890. - В таблице 12 столбцов. Большинство столбцов имеют значения в каждой из строк (все 891 значения не
non-null). В некоторых столбцах значения отсутствуют, количествоnon-nullменее 891. - Столбцы
Name,Sex,CabinиEmbarkedсостоят из текстовых данных (строки, илиobject). Другие столбцы представляют собой числовые данные, некоторые из них представляют собой целые числа (integer), некоторые — вещественные числа (float). - Типы данных (символы, целые числа и так далее) в разных столбцах суммируются путем перечисления dtypes.
Также указывается приблизительный объем оперативной памяти, используемой для хранения DataFrame.
ЗАПОМНИТЕ
Получение данных в pandas из файлов разных форматов или источников данных поддерживается функциями read_.
Экспорт данных из pandas осуществляется разными методами to_.
Методы head/tail/info и атрибут dtypes удобны для первой проверки.
Как выбрать подмножество из DataFrame?#

Меня интересует возраст пассажиров Титаника.
ages = titanic["Age"]
ages.head()
# 0 22.0
# 1 38.0
# 2 26.0
# 3 35.0
# 4 35.0
# Name: Age, dtype: float64
Чтобы выбрать один столбец, используйте квадратные скобки [] с именем интересующего столбца.
Каждый столбец в DataFrame является Series. Поскольку выбран один столбец, возвращаемый объект представляет собой Series. Мы можем убедиться в этом, проверив тип вывода:
type(titanic["Age"])
#pandas.core.series.Series
И посмотрите на shape вывода:
titanic["Age"].shape
# (891,)
DataFrame.shape — это атрибут Series и DataFrame (вспомните урок по чтению и записи: круглые скобки для атрибутов не используются), содержащий количество строк и столбцов: (nrows, ncolumns). Series в pandas одномерна, так что возвращается только количество строк.
Меня интересует возраст и пол пассажиров Титаника.
age_sex = titanic[["Age", "Sex"]]
age_sex.head()
# Age Sex
# 0 22.0 male
# 1 38.0 female
# 2 26.0 female
# 3 35.0 female
# 4 35.0 male
Чтобы выбрать несколько столбцов, используйте список имен столбцов в квадратных скобках [].
Примечание
Внутренние квадратные скобки определяют список Python с именами столбцов, тогда как внешние скобки (мы будем называть их «скобки выбора») используются для выбора данных из DataFrame, как показано в предыдущем примере.
Возвращаемый тип данных — это DataFrame:
type(titanic[["Age", "Sex"]])
# pandas.core.frame.DataFrame
titanic[["Age", "Sex"]].shape
# (891, 2)
Выборка вернула DataFrame с 891 строкой и 2 столбцами. Помните, что DataFrame двумерный объект, где одно измерение — это строки, а другое — столбцы.
Как отфильтровать определенные строки из DataFrame?#

Меня интересуют пассажиры старше 35 лет.
above_35 = titanic[titanic["Age"] > 35]
above_35.head()
# Out[13]:
# PassengerId Survived Pclass Name ... Ticket Fare Cabin Embarked
# 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... ... PC 17599 71.2833 C85 C
# 6 7 0 1 McCarthy, Mr. Timothy J ... 17463 51.8625 E46 S
# 11 12 1 1 Bonnell, Miss. Elizabeth ... 113783 26.5500 C103 S
# 13 14 0 3 Andersson, Mr. Anders Johan ... 347082 31.2750 NaN S
# 15 16 1 2 Hewlett, Mrs. (Mary D Kingcome) ... 248706 16.0000 NaN S
# [5 rows x 12 columns]
Чтобы выбрать строки на основе условия, поместите условие в скобки выбора [].
Условие titanic["Age"] > 35 внутри скобок выбора проверяет, для каких строк столбец Age имеет значение больше 35:
titanic["Age"] > 35
# Out[14]:
# 0 False
# 1 True
# 2 False
# 3 False
# 4 False
# ...
# 886 False
# 887 False
# 888 False
# 889 False
# 890 False
# Name: Age, Length: 891, dtype: bool
На самом деле результатом выполнения условия (>, но возможны и ==, !=, <,<= и прочие) является Series со значениями True либо False и с тем же количеством строк, что и в исходном DataFrame. Такую Series с булевыми значениями можно использовать для фильтрации DataFrame, помещая Series между скобками выбора []. Из DataFrame будут выбраны только те строки, для которых установлено значение True.
Мы уже знаем, что оригинальный DataFrame Титаника состоит из 891 строки. Давайте посмотрим на количество строк, которые удовлетворяют условию, проверив атрибут shape результирующего DataFrame above_35:
above_35.shape
# (217, 12)
Меня интересуют пассажиры Титаника из салонов 2 и 3 класса.
class_23 = titanic[titanic["Pclass"].isin([2, 3])]
class_23.head()
# PassengerId Survived Pclass Name ... Ticket Fare Cabin Embarked
# 0 1 0 3 Braund, Mr. Owen Harris ... A/5 21171 7.2500 NaN S
# 2 3 1 3 Heikkinen, Miss. Laina ... STON/O2. 3101282 7.9250 NaN S
# 4 5 0 3 Allen, Mr. William Henry ... 373450 8.0500 NaN S
# 5 6 0 3 Moran, Mr. James ... 330877 8.4583 NaN Q
# 7 8 0 3 Palsson, Master. Gosta Leonard ... 349909 21.0750 NaN S
# [5 rows x 12 columns]
Подобно условному выражению, описанному выше, условная функция isin() возвращает True для каждой строки, значения которой находятся в предоставленном списке. Чтобы отфильтровать строки на основе такой функции, используйте условную функцию внутри скобок выбора []. В этом случае условие titanic["Pclass"].isin([2, 3]) внутри скобок выбора проверяет, для каких строк столбец Pclass имеет значение 2 или 3.
Вышеприведенный пример эквивалентен фильтрации по строкам, для которых класс равен 2 или 3, и объединению двух выражений оператором | (или):
class_23 = titanic[(titanic["Pclass"] == 2) | (titanic["Pclass"] == 3)]
class_23.head()
# PassengerId Survived Pclass Name ... Ticket Fare Cabin Embarked
# 0 1 0 3 Braund, Mr. Owen Harris ... A/5 21171 7.2500 NaN S
# 2 3 1 3 Heikkinen, Miss. Laina ... STON/O2. 3101282 7.9250 NaN S
# 4 5 0 3 Allen, Mr. William Henry ... 373450 8.0500 NaN S
# 5 6 0 3 Moran, Mr. James ... 330877 8.4583 NaN Q
# 7 8 0 3 Palsson, Master. Gosta Leonard ... 349909 21.0750 NaN S
# [5 rows x 12 columns]
Примечание
При объединении нескольких условных операторов каждое условие должно быть заключено в круглые скобки (). Более того, вы не можете использовать or или and, а должны использовать | в качестве оператора или и & в качестве оператора и.
Question
См. специальный раздел в руководстве пользователя о булевом индексировании или о функции isin.
Я хочу работать с данными о пассажирах, возраст которых известен.
age_no_na = titanic[titanic["Age"].notna()]
age_no_na.head()
# PassengerId Survived Pclass ... Fare Cabin Embarked
# 0 1 0 3 ... 7.2500 NaN S
# 1 2 1 1 ... 71.2833 C85 C
# 2 3 1 3 ... 7.9250 NaN S
# 3 4 1 1 ... 53.1000 C123 S
# 4 5 0 3 ... 8.0500 NaN S
# [5 rows x 12 columns]
Условная функция notna() возвращает True для каждой строки, значения которой не являются Null. Таким образом, ее можно комбинировать со скобками выбора [] для фильтрации таблицы данных.
Вы можете спросить, что же поменялось, ведь значения первых 5 строк все те же. Один из способов проверить — посмотреть, изменилась ли форма:
age_no_na.shape
# (714, 12)
Question
Дополнительные специальные функции для отсутствующих значений см. в разделе руководства пользователя об обработке отсутствующих данных.
Как выбрать определенные строки и столбцы из DataFrame?#

Меня интересуют имена пассажиров старше 35 лет.
adult_names = titanic.loc[titanic["Age"] > 35, "Name"]
adult_names.head()
# 1 Cumings, Mrs. John Bradley (Florence Briggs Th...
# 6 McCarthy, Mr. Timothy J
# 11 Bonnell, Miss. Elizabeth
# 13 Andersson, Mr. Anders Johan
# 15 Hewlett, Mrs. (Mary D Kingcome)
# Name: Name, dtype: object
В этом случае подмножество как строк, так и столбцов создается за один раз, и простого использования скобок выбора [] уже недостаточно. Перед скобками нужны операторы loc и iloc. При использовании loc и iloc строки, которые вам нужны, указываются до запятой, а столбцы — после.
При использовании имен столбцов, меток строк или условия используйте оператор loc перед скобками выбора []. И до, и после запятой вы можете использовать одну метку, список меток, срез меток, условие или двоеточие. Использование двоеточия указывает, что вы хотите выбрать все строки или столбцы.
Меня интересуют строки с 10 по 25 и столбцы с 3 по 5.
titanic.iloc[9:25, 2:5]
# Pclass Name Sex
# 9 2 Nasser, Mrs. Nicholas (Adele Achem) female
# 10 3 Sandstrom, Miss. Marguerite Rut female
# 11 1 Bonnell, Miss. Elizabeth female
# 12 3 Saundercock, Mr. William Henry male
# 13 3 Andersson, Mr. Anders Johan male
# .. ... ... ...
# 20 2 Fynney, Mr. Joseph J male
# 21 2 Beesley, Mr. Lawrence male
# 22 3 McGowan, Miss. Anna "Annie" female
# 23 1 Sloper, Mr. William Thompson male
# 24 3 Palsson, Miss. Torborg Danira female
# [16 rows x 3 columns]
Опять же, подмножество как строк, так и столбцов создается за один раз, и простого использования скобок выбора [] уже недостаточно. Если вас особенно интересуют определенные строки или столбцы в зависимости от их положения (порядкового номера) в таблице, используйте оператор iloc.
При выборе определенных строк или столбцов с помощью loc или iloc выбранным данным могут быть присвоены новые значения. Например, присвоим имя anonymous первым 3 элементам третьего столбца:
titanic.iloc[0:3, 3] = "anonymous"
titanic.head()
# PassengerId Survived Pclass ... Fare Cabin Embarked
# 0 1 0 3 ... 7.2500 NaN S
# 1 2 1 1 ... 71.2833 C85 C
# 2 3 1 3 ... 7.9250 NaN S
# 3 4 1 1 ... 53.1000 C123 S
# 4 5 0 3 ... 8.0500 NaN S
# [5 rows x 12 columns]
Question
Больше информации об использовании loc и iloc вы найдете в разделе руководства пользователя о различных вариантах индексации.
Запомните
При выборе подмножества данных используются квадратные скобки выбора [].
Внутри скобок выбора вы можете использовать одну метку столбца или строки, список меток столбца или строки, срез меток, условное выражение или двоеточие.
Выбирайте определенные строки и/или столбцы с помощью loc, указывая имена строк и столбцов.
Выбирайте определенные строки и/или столбцы с помощью iloc, указывая порядковый номер в таблице.
Можно присваивать новые значения выборке на основе loc и iloc.
Как создавать диаграммы в pandas?#
В этом руководстве мы рассмотрим, как создавать визуализации данных из датасета Titanic с использованием библиотеки pandas и matplotlib. Датасет titanic.csv содержит информацию о пассажирах Титаника, включая такие столбцы, как PassengerId, Survived, Pclass, Name, Sex, Age, SibSp, Parch, Ticket, Fare, Cabin и Embarked. Мы будем использовать числовые столбцы Age (возраст) и Fare (стоимость билета) для примеров, а также продемонстрируем, как можно настроить и сохранить графики.
import pandas as pd
import matplotlib.pyplot as plt
Примечание: В датасете есть пропущенные значения (например, в столбце Age). Для некоторых визуализаций может потребоваться предварительная обработка данных, например, заполнение пропусков.

Для быстрого просмотра распределения числовых данных можно использовать метод .plot():
titanic[["Age", "Fare"]].plot()
plt.show()
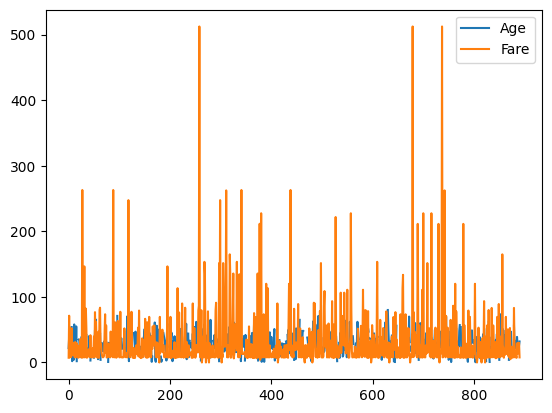
По умолчанию pandas создает линейный график для каждого числового столбца.
Примечание: Линейный график может быть не самым подходящим для этого датасета, так как данные не являются временным рядом.
Построение гистограммы для возраста пассажиров#
Чтобы визуализировать распределение возраста пассажиров, используем гистограмму:
titanic["Age"].plot.hist(bins=20, edgecolor='black')
plt.xlabel("Возраст")
plt.title("Распределение возраста пассажиров")
plt.show()
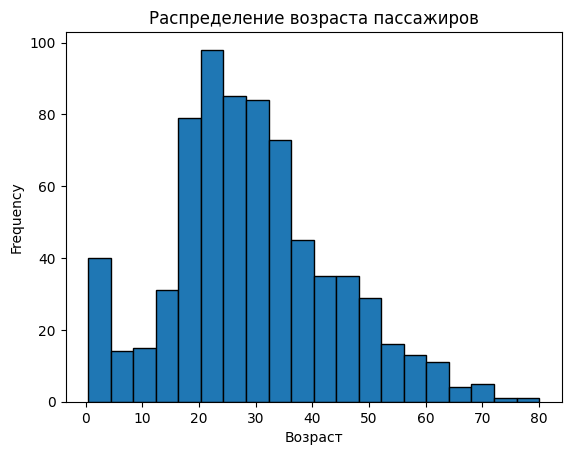
Гистограмма показывает, как распределены возраста пассажиров. Параметр bins=20 задает количество интервалов, а edgecolor='black' улучшает читаемость графика за счет установки цвета границ.
Диаграмма рассеивания: визуалзация стоимости билета и возраста#
Для визуального сравнения возраста и стоимости билета используем точечную диаграмму (scatter plot):
titanic.plot.scatter(x="Age", y="Fare", alpha=0.5)
plt.xlabel("Возраст")
plt.ylabel("Стоимость билета")
plt.title("Стоимость билета vs Возраст пассажиров")
plt.show()
Точечная диаграмма показывает взаимосвязь между возрастом и стоимостью билета. Параметр alpha=0.5 делает точки полупрозрачными, чтобы лучше видеть области с высокой плотностью.
Обзор доступных методов построения графиков#
Чтобы узнать, какие типы диаграмм поддерживает pandas, можно вывести список методов объекта plot:
available_methods = [method_name for method_name in dir(titanic.plot) if not method_name.startswith("_")]
print(available_methods)
## ['area', 'bar', 'barh', 'box', 'density', 'hexbin', 'hist', 'kde', 'line', 'pie', 'scatter']
Question
Примените визуализацию pie для параметра sex
Примечание: В средах, таких как Jupyter Notebook, вы можете использовать клавишу Tab после titanic.plot. для автодополнения и просмотра доступных методов.
Построение диаграммы размаха (Box Plot)#
Диаграмма размаха (box plot) полезна для анализа распределения и выбросов в числовых столбцах:
titanic[["Age", "Fare"]].plot.box()
plt.title("Диаграмма размаха для возраста и стоимости билета")
plt.show()
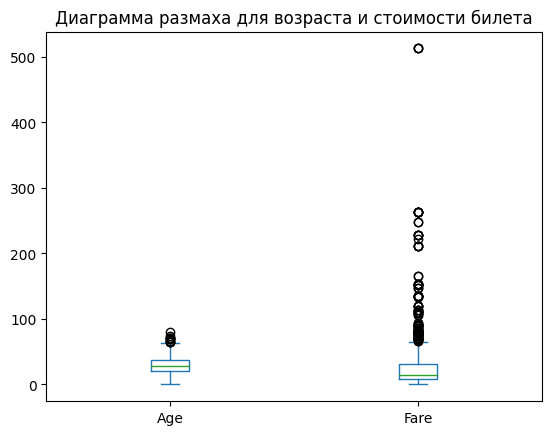
Диаграмма размаха показывает медиану, квартили и возможные выбросы для Age и Fare. Например, видно, что в столбце Fare есть значительные выбросы (очень дорогие билеты).
Построение отдельных субдиаграмм#
Для создания отдельных графиков для каждого столбца используем параметр subplots=True:
titanic[["Age", "Fare"]].plot.area(figsize=(12, 4), subplots=True)
plt.suptitle("Область графиков для возраста и стоимости билета")
plt.show()
Два отдельных графика области для Age и Fare.
Настройка и сохранение диаграммы#
fig, axs = plt.subplots(figsize=(12, 4))
titanic["Fare"].plot.hist(bins=30, ax=axs, edgecolor='black')
axs.set_xlabel("Стоимость билета")
axs.set_ylabel("Количество пассажиров")
axs.set_title("Распределение стоимости билетов")
fig.savefig("titanic_fare_distribution.png")
plt.show()
Запомните
Методы .plot.* применимы как к Series, так и к DataFrame.
По умолчанию каждый из столбцов отображается как отдельный элемент (линейный график, диаграмма размаха и так далее).
Любая диаграмма, созданная pandas, является объектом Matplotlib.
Как создать новые столбцы, производные от существующих#
В некоторых ситуациях вам можетт понадобится сформировать новый признак на основе существующих. Такой метод называется "инженирией признаков" (feature engineering).
В этом примере покажу, как извлечь обращения ('Mr', 'Mrs', 'Miss', 'Master', 'Other') из столбца с именами в DataFrame и создать новый столбец с этими обращениями, следуя вашим инструкциям. Предположим, у нас есть DataFrame с колонкой 'Name', содержащей имена с обращениями
# Функция для извлечения обращения
def extract_title(name):
titles = ['Mr', 'Mrs', 'Miss', 'Master']
for title in titles:
if title in name:
return title
return 'Other'
# Создание нового столбца 'Title' с извлеченными обращениями
df['Title'] = df['Name'].apply(extract_title)
# Вывод результата
print(df)
- Извлечение обращений:
- Используется функция extract_title, которая проверяет наличие обращений ('Mr', 'Mrs', 'Miss', 'Master') в строке имени.
- Если ни одно из указанных обращений не найдено, возвращается 'Other'.
- Функция применяется к столбцу 'Name' с помощью apply.
- Создание нового столбца:
- Новый столбец 'Title' создается с помощью df['Title'], как указано в ваших инструкциях.
- Операция выполняется поэлементно, без перебора строк.
Примечания:
- Если в данных есть другие обращения (например, 'Dr', 'Prof'), они будут классифицированы как 'Other'.
- Если нужно переименовать столбцы или индексы, можно использовать df.rename(columns={'old_name': 'new_name'}) для столбцов или df.rename(index={0: 'new_index'}) для строк, как указано в ваших инструкциях.
- Если у вас есть конкретный DataFrame или дополнительные условия (например, другой формат имен), уточните, и я адаптирую решение.
Давайте оценим, действительно ли наш признак более скоррелирован с целевым знаечнием
# Создание таблицы сопряженности между Title и Survived
pivot_table = pd.crosstab(df['Title'], df['Survived'], normalize='index')
# Визуализация тепловой карты
plt.figure(figsize=(8, 6))
sns.heatmap(pivot_table, annot=True, cmap='YlGnBu', fmt='.2f')
plt.title('Корреляция между титулом и выживаемостью')
plt.xlabel('Выживание (0 = Погиб, 1 = Выжил)')
plt.ylabel('Титул')
plt.show()
Используется pd.crosstab с параметром normalize='index', чтобы получить доли выживания для каждого титула (в процентах относительно общего числа пассажиров с данным титулом).
Например, для титула Mrs в столбце Survived=1 будет доля выживших женщин с этим титулом.
Note
Создавайте новый столбец, записывая результат в DataFrame с новым именем столбца между квадратными скобками [].
Операции выполняются поэлементно, не нужно перебирать строки.
Используйте rename со словарем или функцией, чтобы переименовать метки строк или имена столбцов.
Как рассчитать сводную статистику?#

Каков средний возраст пассажиров Титаника?
titanic["Age"].mean()
К столбцам с числовыми данными можно применять различные статистические операции. По умолчанию исключаются отсутствующие данные и обрабатываются только строки.

Каков средний возраст и стоимость билета пассажиров Титаника?
titanic[["Age", "Fare"]].median()
Note
Статистические показатели, применяемые к нескольким столбцам DataFrame (выбор двух столбцов возвращает DataFrame, см. параграф по подмножеству данных), вычисляются для каждого столбца с числовыми значениями.
Сводная статистика может быть рассчитана для нескольких столбцов одновременно. Помните функцию describe из начала?
titanic[["Age", "Fare"]].describe()
Вместо предопределенного набора статистических показателей можно задать собственную комбинацию для нескольких столбцов с помощью метода DataFrame.agg():
titanic.agg(
{
"Age": ["min", "max", "median", "skew"],
"Fare": ["min", "max", "median", "mean"],
}
)
Tip
Подробная информация об описательной статистике представлена в разделе руководства пользователя об описательной статистике.
Сводная статистика, сгруппированная по категориям#

Каков средний возраст мужчин в сравнении с женщинами среди пассажиров Титаника?
titanic[["Sex", "Age"]].groupby("Sex").mean()
Поскольку нас интересует средний возраст для каждого пола, сначала делается выборка по этим двум столбцам:
titanic[["Sex", "Age"]]. Затем метод groupby() применяется к столбцу Sex для создания групп по категориям. Наконец рассчитывается и возвращается средний возраст для каждого пола.
Вычисление некоторого показателя (например, mean — средний возраст) для каждой категории в столбце (например, мужчина/женщина в столбце Sex) — это распространенный подход. Для поддержки этого типа операций используется метод groupby. В целом это соответствует более общему подходу «разделить-применить-объединить»:
- Разделить данные на группы.
- Применить функцию к каждой группе независимо.
- Объединить результаты в структуру данных.
В pandas шаги применения и объединения обычно выполняются вместе.
В предыдущем примере мы сначала явно выбрали 2 столбца. Если этого не сделать, метод mean применяется к каждому столбцу, содержащему числовые данные:
titanic.groupby("Sex").mean()
# PassengerId Survived Pclass Age SibSp Parch Fare
# Sex
# female 431.028662 0.742038 2.159236 27.915709 0.694268 0.649682 44.479818
# male 454.147314 0.188908 2.389948 30.726645 0.429809 0.235702 25.523893
Нет особого смысла получать среднее значение Pclass. если нас интересует только средний возраст для каждого пола. Выбор столбцов (как обычно, с помощью квадратных скобок [] ) поддерживается и для сгруппированных данных:
titanic.groupby("Sex")["Age"].mean()
#Sex
#female 27.915709
#male 30.726645
#Name: Age, dtype: float64

Tip
Столбец Pclass содержит числовые данные, но на самом деле представляет 3 категории (или факторы) с метками ‘1’, ‘2’ и ‘3’. соответственно. Подсчитывать статистику по ним особого смысла нет. Поэтому pandas предоставляет тип данных Categorical для обработки таких данных. Более подробная информация представлена в разделе руководства пользователя о категориальных данных.
Какова средняя стоимость билета для каждой из комбинаций пола и класса обслуживания?
titanic.groupby(["Sex", "Pclass"])["Fare"].mean()
# Sex Pclass
# female 1 106.125798
# 2 21.970121
# 3 16.118810
# male 1 67.226127
# 2 19.741782
# 3 12.661633
# Name: Fare, dtype: float64
Группировка может выполняться по нескольким столбцам одновременно. Передайте имена столбцов в виде списка методу groupby().
Подсчет количества записей по категориям#

Каково количество пассажиров в каютах каждого класса?
titanic["Pclass"].value_counts()
Метод value_counts() подсчитывает количество записей для каждой категории в столбце.
Метод представляет собой сокращение, так как на самом деле это операция группировки в сочетании с подсчетом количества записей в каждой группе:
titanic.groupby("Pclass")["Pclass"].count()
Note
Как size, так и count можно использовать в сочетании с groupby. В то время как size включает значения NaN и просто выдает количество строк (размер таблицы), count исключает пропущенные значения. Используйте аргумент dropna метода value_counts, чтобы включить или исключить значения NaN.
Запомните
Сводную статистику можно рассчитать для целых столбцов или строк.
Сила подхода «разделить-применить-объединить» обеспечивается методом groupby.
value_counts — это удобное сокращение для подсчета количества записей в каждой категории.
Задание для самоконтроля#
Question
Визуализируйте в виде pie-chart долю выживших пассажиров среди мужчин и женщин.
Расчитайте также процент выживших пассажиров от общего числа.
При помощи аналига box-plot установите закономерность в разбросе по возрастам.
Попробуйте проанализировать следующие графики:
import matplotlib.pyplot as plt
import seaborn as sns
# Создадим гистограммы тарифов среди выживших и погибших пассажиров
plt.figure(figsize=(10, 6))
sns.histplot(train_data[train_data['Survived'] == 1]['Fare'], kde=True, color='g', label='Выжившие')
sns.histplot(train_data[train_data['Survived'] == 0]['Fare'], kde=True, color='r', label='Погибшие')
plt.xlabel('Тариф (Fare)')
plt.ylabel('Частота')
plt.title('Распределение тарифов среди выживших и погибших пассажиров')
plt.legend()
plt.show()
# Создадим гистограммы возрастов для мужчин и женщин
plt.figure(figsize=(10, 6))
plt.hist(train_data[train_data['Sex'] == 'male']['Age'].dropna(), bins=20, edgecolor='k', label='Мужчины', alpha=0.7)
plt.hist(train_data[train_data['Sex'] == 'female']['Age'].dropna(), bins=20, edgecolor='k', label='Женщины', alpha=0.7)
plt.xlabel('Возраст')
plt.ylabel('Частота')
plt.title('Распределение возрастов среди мужчин и женщин')
plt.legend()
plt.show()
# Создадим разбиение возрастов по 10 лет
age_bins = range(0, 91, 10) # Возраста 0-10, 10-20, и т. д.
# Создадим категорию "AgeGroup" для каждого пассажира на основе его возраста
train_data['AgeGroup'] = pd.cut(train_data['Age'], bins=age_bins)
# Посчитаем количество выживших в каждой возрастной группе
survival_counts = train_data[train_data['Survived'] == 1]['AgeGroup'].value_counts().sort_index()
# Создадим столбчатую диаграмму
plt.figure(figsize=(10, 6))
survival_counts.plot(kind='bar', color='green')
plt.xlabel('Возрастная группа')
plt.ylabel('Количество выживших')
plt.title('Количество выживших с разбиением по возрасту')
plt.xticks(rotation=45)
plt.show()
Как изменять структуру таблиц?#
Я хочу отсортировать данные Титаника по возрасту пассажиров.
titanic.sort_values(by="Age").head()
# PassengerId Survived Pclass Name Sex ... Parch Ticket Fare Cabin Embarked
# 803 804 1 3 Thomas, Master. Assad Alexander male ... 1 2625 8.5167 NaN C
# 755 756 1 2 Hamalainen, Master. Viljo male ... 1 250649 14.5000 NaN S
# 644 645 1 3 Baclini, Miss. Eugenie female ... 1 2666 19.2583 NaN C
# 469 470 1 3 Baclini, Miss. Helene Barbara female ... 1 2666 19.2583 NaN C
# 78 79 1 2 Caldwell, Master. Alden Gates male ... 2 248738 29.0000 NaN S
# [5 rows x 12 columns]
Я хочу отсортировать данные Титаника по классу салона и возрасту в порядке убывания.
titanic.sort_values(by=['Pclass', 'Age'], ascending=False).head()
# PassengerId Survived Pclass Name Sex ... Parch Ticket Fare Cabin Embarked
# 851 852 0 3 Svensson, Mr. Johan male ... 0 347060 7.7750 NaN S
# 116 117 0 3 Connors, Mr. Patrick male ... 0 370369 7.7500 NaN Q
# 280 281 0 3 Duane, Mr. Frank male ... 0 336439 7.7500 NaN Q
# 483 484 1 3 Turkula, Mrs. (Hedwig) female ... 0 4134 9.5875 NaN S
# 326 327 0 3 Nysveen, Mr. Johan Hansen male ... 0 345364 6.2375 NaN S
# [5 rows x 12 columns]
Как работать с текстовыми данными?#
Сделать все символы в имени строчными.
titanic["Name"].str.lower()
Чтобы преобразовать все строки в столбце Name в нижний регистр, выберите столбец Name (см. параграф по подмножествам), добавьте метод доступа str и примените метод lower. Таким образом, каждая из строк в Name поэлементно преобразуется в нижний регистр.
Создать новый столбец Surname с фамилиями пассажиров, удалив часть перед запятой.
titanic["Name"].str.split(",")
# 0 [Braund, Mr. Owen Harris]
# 1 [Cumings, Mrs. John Bradley (Florence Briggs ...
# 2 [Heikkinen, Miss. Laina]
# 3 [Futrelle, Mrs. Jacques Heath (Lily May Peel)]
# 4 [Allen, Mr. William Henry]
# ...
# 886 [Montvila, Rev. Juozas]
# 887 [Graham, Miss. Margaret Edith]
# 888 [Johnston, Miss. Catherine Helen "Carrie"]
# 889 [Behr, Mr. Karl Howell]
# 890 [Dooley, Mr. Patrick]
# Name: Name, Length: 891, dtype: object
При использовании метода
Series.str.split() каждое из значений возвращается в виде списка из 2 элементов. Первый элемент — это часть до запятой, а второй элемент — это часть после запятой.
titanic["Surname"] = titanic["Name"].str.split(",").str.get(0)
titanic["Surname"]
# Out[7]:
# 0 Braund
# 1 Cumings
# 2 Heikkinen
# 3 Futrelle
# 4 Allen
# ...
# 886 Montvila
# 887 Graham
# 888 Johnston
# 889 Behr
# 890 Dooley
# Name: Surname, Length: 891, dtype: object
Поскольку нас интересует только первая часть, содержащая фамилию (элемент 0), мы снова можем использовать метод доступа str и применить Series.str.get(), чтобы извлечь соответствующую часть. Да, строковые функции можно даже объединять для выполнения нескольких функций за раз!
Note
Более подробная информация об извлечении частей строк доступна в разделе руководства пользователя о разделении и замене строк.
Среди всехх пассажиров давайте найдем графиню Ротес (Countess of Rothes)
titanic["Name"].str.contains("Countess")
# 0 False
# 1 False
# 2 False
...
# 889 False
# 890 False
# Name: Name, Length: 891, dtype: bool
titanic[titanic["Name"].str.contains("Countess")]
# PassengerId Survived Pclass Name ... Fare Cabin Embarked Surname
# 759 760 1 1 Rothes, the Countess. of (Lucy Noel Martha Dye... ... 86.5 B77 S Rothes
# [1 rows x 13 columns]
Строковый метод Series.str.contains() проверяет каждое из значений в столбце Name на наличие подстроки Countess (графиня), и возвращает для каждого из значений True (в имени есть подстрока Countess) или False (в имени нет подстроки Countess). Этот вывод можно использовать для подвыборки данных с использованием условного (логического) индексирования, введенного в параграфе о подмножествах. Поскольку на Титанике была только одна графиня, в результате мы получили один ряд.
Note
Доступны и более мощные методы извлечения строк, так как Series.str.contains()и Series.str.extract() принимают регулярные выражения, но это выходит за рамки данного руководства.
Более подробная информация об извлечении частей строк доступна в разделе руководства пользователя о сопоставлении и извлечении строк.
У кого из пассажиров Титаника самое длинное имя?
titanic["Name"].str.len()
Чтобы получить самое длинное имя, мы сначала должны получить длину каждого из имен в столбце Name. Функция Series.str.len() применяется к каждому из имен по отдельности, поэлементно.
titanic["Name"].str.len().idxmax()
Далее нам нужно получить тот ряд (предпочтительно его индексную метку), где длина имени наибольшая. Метод
idxmax() делает именно это. Это не строковый метод, он применяется к целым числам, поэтому str не используется.
titanic.loc[titanic["Name"].str.len().idxmax(), "Name"]
Основываясь на индексном имени строки (307) и столбца (Name), мы можем сделать выборку с помощью оператора loc, представленного в параграфе о подмножествах.
В столбце «Sex» заменить значения «male» на «M», а «female» на «F».
titanic["Sex_short"] = titanic["Sex"].replace({"male": "M", "female": "F"})
Series.replace(), не являясь строковым методом, предоставляет удобный способ использования маппингов или словарей для перевода определенных значений. Для маппинга {from : to} нужен словарь.
Warning
Существует также строковый метод Series.str.replace() для замены набора символов. Однако при маппинге нескольких значений это будет выглядеть так:
titanic["Sex_short"] = titanic["Sex"].str.replace("female", "F")
titanic["Sex_short"] = titanic["Sex_short"].str.replace("male", "M")
Это громоздко и приводит к ошибкам. Просто подумайте (или попробуйте сами), что произойдет, если эти два выражения применить в обратном порядке!
ЗАПОМНИТЕ
Строковые методы доступны с использованием метода доступа str.
Строковые методы работают поэлементно, их можно использовать для условного индексирования.
replace — это удобный метод для преобразования значений в соответствии с заданным словарем.