Основы Парсинга#
Введение: Парсинг в Data Science#
В современной работе с данными парсинг играет ключевую роль на самых ранних этапах анализа. Под парсингом (от англ. parsing) обычно понимается процесс извлечения структурированной информации из неструктурированных или слабо структурированных источников — веб-страниц, текстовых документов, логов, HTML, XML или JSON-файлов.

Для специалистов в области Data Science парсинг становится необходимым инструментом, когда данные не представлены в удобных табличных форматах. Например, чтобы собрать информацию о товарах с интернет-магазина, отзывы пользователей с форумов, актуальные курсы валют, статьи с новостных сайтов или данные из API — нужно сначала "снять" данные с ресурса, затем извлечь из них полезные фрагменты и привести к структуре, пригодной для анализа.
Парсинг тесно связан с такими задачами, как:
- Web scraping — автоматизированный сбор данных с веб-сайтов;
- Обработка естественного языка (NLP) — выделение именованных сущностей, ключевых слов, предложений;
- Очистка данных — удаление мусора, перевод форматов, стандартизация;
Без эффективного парсинга доступ к данным остаётся ограниченным, а значит, невозможен и сам анализ. Поэтому умение извлекать данные из текстов — важный навык каждого data scientist, наравне с визуализацией, статистикой и машинным обучением.
Регулярные выражения#
Регулярное выражение — это мощный, гибкий и эффективный инструмент для сопоставления текста на основе заранее определённого шаблона.
То есть регулярные выражения позволяют найти строки или наборы строк в тексте, используя специализированный синтаксис,
с помощью которого описывается шаблон для поиска.
Универсальные шаблоны регулярных выражений напоминают миниатюрный язык программирования,
который предназначен для описания и разбора текста.
Почему регулярные выражения?#

Регулярные выражения (RegEx) — мощный инструмент для обработки и анализа текста. Рассмотрим несколько сценариев их применения в Python:
Data Mining: регулярное выражение — лучший инструмент для интеллектуального анализа данных. Оно эффективно идентифицирует текст (строку, подстроку) в большом объёме текста, проверяя его по заранее заданному шаблону. Некоторые распространённые сценарии — определение адреса электронной почты, URL-адреса или телефона из большого текста.
Data Validation (Проверка данных): регулярное выражение может идеально подойти для таких задач, как проверка данных. Оно может включать в себя широкий спектр процессов проверки путём определения различных наборов шаблонов. Вот несколько примеров: проверка номеров телефонов, электронной почты и т.д.
Модуль Re (import re) — операции с регулярными выражениями#
Python имеет встроенный пакет с именем re, который можно использовать для работы с регулярными выражениями.
Этот модуль предоставляет операции сопоставления регулярных выражений в Python, аналогичные тем, которые имеются в Perl. Основная функция модуля re — предложить поиск, в котором используются регулярное выражение и строка. Он либо возвращает первое совпадение, либо ничего.
Если возникает ошибка при компиляции или использовании регулярного выражения, модуль re вызывает исключение re.error.
Команда для импорта модуля re:
import re
Краткое описание синтаксиса RegEx на примере с Email#
Для того, чтобы кратко познакомиться с Regular Expression, рассмотрим два примера и описание некоторых компонентов регулярного выражения.
Пример регулярного выражения для проверки email с пометкой каждого компонента:
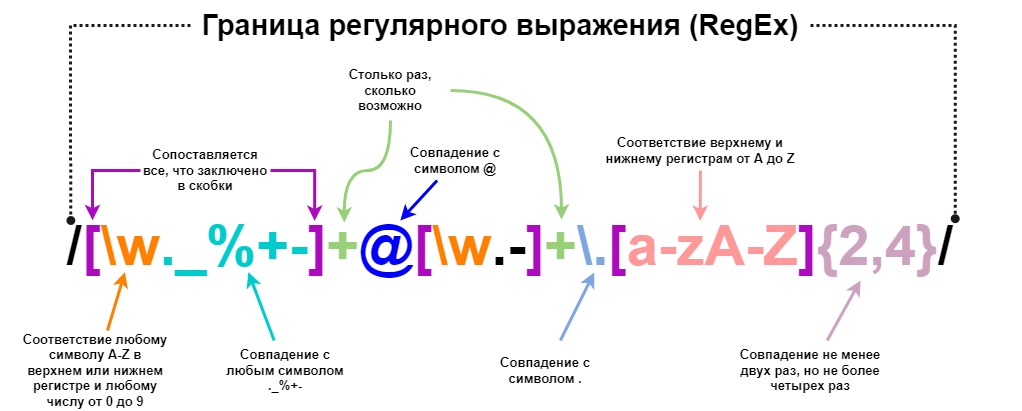
Еще один пример с почтой:

Описание некоторых общих компонентов регулярных выражений:#
-
Символ
+в регулярном выражении означает «сопоставить предыдущий символ один или несколько раз».
Например,ab+cсоответствует «abc», «abbc», «abbbc», но не соответствует «ac».
Знак плюс, используемый в регулярном выражении, называется Клини плюс в честь математика Стивена Клини (1909–1994), который ввёл эту концепцию. -
Символ
*в регулярном выражении означает «сопоставить предыдущий символ ноль или более раз».
Например,ab*cсоответствует «abc», «abbc», «abbbc» и «ac». Это называется звездой Клини. -
Знак вопроса
?указывает на 0 или 1 вхождение предыдущего элемента.
Например,colou?rсоответствует как «color», так и «colour». -
Точка
.соответствует любому одиночному символу (кроме символа новой строки).
Например,a.cсоответствует «abc», «adc», «aec» и т.д.
Если мы хотим сопоставить несколько символов перед буквой «c», используем звёздочку*следующим образом:
a.*c— и это будет соответствовать «a bdefgh c». -
[a-z]— очень полезно, так как определяет диапазон возможных значений — относится ко всем строчным буквам алфавита отaдоz.
Аналогично можно использовать диапазоны для заглавных букв и цифр:[A-Z]и[0-9]. -
Символ
^соответствует начальной позиции любой строки. -
Выражение
[^b]atсоответствует всем строкам, заканчивающимся на.at, кроме «bat».
При использовании^внутри квадратных скобок следующая буква исключается из диапазона. -
Выражение
^[hc]atсоответствует «hat» и «cat», но только в начале строки. -
Обратный слеш
\экранирует символы.
Например, чтобы точка воспринималась буквально, её нужно экранировать:\.
Это нужно, чтобы регулярное выражение не считало точку частью квантификаторов, как определено выше, а искало именно символ точки в шаблоне.
Работа с модулем Re. Import re#
Регулярные выражения — это, по сути, крошечный узкоспециализированный язык программирования, встроенный в Python и доступный через модуль re.
Используя этот небольшой язык, вы указываете правила для набора возможных строк, которые хотите сопоставить:
- этот набор может содержать английские предложения,
- или адреса электронной почты,
- или команды TeX,
- и т.д.
Затем можно задать вопросы типа:
- «Соответствует ли эта строка шаблону?»
- «Есть ли где-нибудь в этой строке совпадение с шаблоном?»
Модель re также используется для изменения строки или её разделения различными способами.
Шаблоны регулярных выражений компилируются в серию байт-кодов, которые затем выполняются механизмом сопоставления, написанным на C, определённым образом для создания байт-кода, который работает быстрее.
Язык регулярных выражений относительно мал и ограничен, поэтому не все задачи обработки строк можно решить с помощью регулярных выражений. Есть задачи, которые можно решить регулярными выражениями, но выражения получаются очень сложными. В таких случаях лучше написать код на Python: он будет медленнее, чем сложное регулярное выражение, но зато более понятным.
Вводный пример RegEx на Python#
Когда вы импортировали re модуль, вы можете начать использовать регулярные выражения:
Пример — Проверим строку, что она начинается с ‘The’ и заканчивается ‘Spain’:
import re
#Проверьте, начинается ли строка с «The» и заканчивается ли она на «Spain»:
txt = "The rain in Spain"
x = re.search("^The.*Spain$", txt)
if x:
print("Есть совпадение")
else:
print("Нет совпадения")
Функции RegEx#
Регулярные выражения компилируются в объекты шаблонов, которые имеют методы для различных операций, таких как поиск совпадений с шаблоном или выполнение подстановки строк.
Модуль re предоставляет набор функций и методов для поиска и обработки строк по шаблону:
| Функция / Метод | Описание |
|---|---|
findall() |
Возвращает список всех совпадений в строке |
search() |
Возвращает объект Match, если где-либо в строке найдено совпадение |
split() |
Разделяет строку по совпадениям и возвращает список полученных частей |
sub() |
Заменяет одно или несколько совпадений заданной строкой |
subn() |
То же, что и sub(), но возвращает кортеж (новая строка, количество замен) |
match() |
Ищет совпадение с начала строки |
finditer() |
Ищет все совпадения, возвращая итератор объектов Match |
compile() |
Компилирует регулярное выражение в объект шаблона для последующего многократного использования |
fullmatch() |
Проверяет, что вся строка целиком соответствует шаблону |
flags |
Флаги, которые можно передавать в функции для изменения поведения регулярных выражений |
Metacharacters (Метасимволы)#
Метасимволы — это символы со специальным значением:
| Метасимвол | Описание |
|---|---|
[…] |
Набор символов |
[^…] |
Отрицательный класс символов. Соответствует любому символу, не заключенному в скобки |
\ |
Специальная последовательность или экранирование специальных символов |
. |
Любой символ, кроме символа новой строки |
^ |
Начало строки |
$ |
Конец строки |
* |
Ноль или более повторений предыдущего символа |
+ |
Одно или более повторений предыдущего символа |
? |
Ноль или одно вхождение предыдущего символа |
{} |
Ровно указанное количество повторений |
{n,m} |
От n до m повторений предыдущего символа |
| |
Чередование, соответствует одному из вариантов по обе стороны от | |
() |
Захват и группировка символов |
(xyz) |
Группа символов, соответствует последовательности xyz |
Special Sequences RegEx (Специальные последовательности)#
Специальная последовательность — это когда за символом следует один из символов в списке ниже, которая имеет особое значение:
| Character | Описание |
|---|---|
\A |
Совпадение, если указанные символы находятся в начале строки |
\b |
Совпадение, если указанные символы находятся в начале или в конце слова |
\B |
Совпадение, если указанные символы присутствуют, но НЕ в начале или в конце слова |
\d |
Совпадение, если строка содержит цифры (числа от 0 до 9) |
\D |
Совпадение, если строка НЕ содержит цифр |
\s |
Совпадение, если строка содержит символ пробела |
\S |
Совпадение, если строка НЕ содержит символов пробела |
\w |
Совпадение, если строка содержит символы слова (a–z, A–Z, 0–9, _) |
\W |
Совпадение, если строка НЕ содержит символов слова |
\Z |
Совпадение, если указанные символы находятся в конце строки |
Sets (Наборы)#
Set (Набор) — это набор символов внутри пары квадратных скобок [] со специальным значением:
| Set | Описание |
|---|---|
[arn] |
Совпадение с одним из указанных символов (a, r или n) |
[a-n] |
Совпадение с любым символом нижнего регистра от a до n |
[^arn] |
Совпадение с любым символом, кроме a, r и n |
[0123] |
Совпадение с любой из указанных цифр (0, 1, 2 или 3) |
[0-9] |
Совпадение с любой цифрой от 0 до 9 |
[0-5][0-9] |
Совпадение с любым двузначным числом от 00 до 59 |
[a-zA-Z] |
Совпадение с любым символом от a до z или от A до Z |
[+] |
В наборе символов + * . |
Символ — бэкслеш в Python RegEx#
Регулярные выражения используют символ обратной косой черты (‘\’) для обозначения специальных форм или для разрешения использования специальных символов без обращения к их особому значению. Это противоречит тому, что Python использует тот же символ для той же цели в строковых литералах.
Допустим, вы хотите написать RE, который соответствует строке \section, которая может быть найдена в файле. Чтобы понять, что писать в программном коде, начните с нужной строки для сопоставления. Затем вы должны экранировать обратную косую черту и другие метасимволы, предваряя их обратной косой чертой, в результате чего получится строка \\section.
Результирующая строка, которую необходимо передать, re.compile() должна быть \\section. Однако, чтобы выразить это как строковый литерал Python, обе обратные косые черты должны быть снова экранированы.
| Символы | Этап |
|---|---|
| \section | Текстовая строка для сопоставления |
| \section | Экранированная обратная косая черта для re.compile() |
| "\\section" | Экранированные символы обратной косой черты для строкового литерала |
Решение состоит в том, чтобы использовать для регулярных выражений нотацию необработанных строк Python. Обратная косая черта не обрабатывается каким-либо особым образом в строковом литерале с префиксом ‘r’:
r"\\section"
Регулярные выражения часто записываются в коде Python с использованием этой записи необработанных строк:
| Regular String | Raw String |
|---|---|
| "ab*" | r"ab*" |
| "\\section" | r"\section" |
| "\w+\s+\1" | r"\w+\s+\1" |
Функция findall()#
Функция findall() возвращает список, содержащий все совпадения.
Модуль findall() используется для поиска «всех» вхождений, соответствующих заданному шаблону. Напротив, модуль search() вернет только первое вхождение, соответствующее указанному шаблону. findall() перебирает все строки файла и возвращает все непересекающиеся совпадения шаблона за один шаг.
re.findall(pattern, string, flags=0)
Примеры использования:
import re
pattern = 'Привет'
string = 'Привет, как твои дела? Привет, нормально, учу регулярные выражения.'
result = re.findall(pattern, string)
print(result)
# В данном примере будет выведено ['Привет', 'Привет']
Функция search()#
Функция search() будет искать шаблон регулярного выражения и возвращать первое вхождение. В отличие от Python match(), он проверяет все строки входной строки. Функция Python search() возвращает объект соответствия, когда шаблон найден, и «ноль», если шаблон не найден
re.search(pattern, string, flags=0)
Примеры использования:
import re
pattern = 'Привет'
string = 'Привет, как твои дела? Привет, нормально, учу регулярные выражения.'
result = re.search(pattern, string)
print(result)
# В данном примере будет выведено <re.Match object; span=(0, 6), match='Привет'>
Вернётся то же самое, что и при re.match, но если строка будет такой:
import re
pattern = 'Привет'
string = 'Как твои дела? Привет, нормально, учу регулярные выражения.'
result = re.search(pattern, string)
print(result)
# В данном примере будет выведено <re.Match object; span=(15, 21), match='Привет'>
Функция split()#
Функция split() работает аналогично методу split в строках, но в функции re.split` можно использовать регулярные выражения, а значит, разделять строку на части по более сложным условиям.
re.split(pattern, string, maxsplit=0, flags=0)
Примеры использования:
import re
pattern = 'Привет'
string = 'Привет, как твои дела? Привет, нормально, учу регулярные выражения.'
result = re.split(pattern, string)
print(result)
# В данном примере будет выведено ['', ', как твои дела? ', ', нормально, учу регулярные выражения.']
Функция sub()#
Функция re.sub работает аналогично методу replace в строках. Но в функции re.sub можно использовать регулярные выражения, а значит, делать замены по более сложным условиям.
re.sub(pattern, repl, string, count=0, flags=0)
Примеры использования:
import re
pattern = 'Привет'
replace = 'Пока'
string = 'Привет, как твои дела? Привет, нормально, учу регулярные выражения.'
result = re.sub(pattern, replace, string)
print(result)
# В данном примере будет выведено Пока, как твои дела? Пока, нормально, учу регулярные выражения.
Функция subn()#
Функция subn() аналогична sub(), но возвращает новую строку и количество произведенных замен.
re.subn(pattern, repl, string, count=0, flags=0)
Примеры использования:
import re
pattern = 'Привет'
replace = 'Пока'
string = 'Привет, как твои дела? Привет, нормально, учу регулярные выражения.'
result = re.subn(pattern, replace, string)
print(result)
# Выведет ('Пока, как твои дела? Пока, нормально, учу регулярные выражения.', 2)
Функция match()#
Функция re.match() re в Python будет искать шаблон регулярного выражения только в начале строки. Функция match() возвращает объект соответствия, если часть начала строки подпадает под шаблон, иначе функция вернет None.
re.match(pattern, string, flags=0)
Примеры использования:
import re
pattern = 'Привет'
string = 'Привет, как твои дела? Привет, нормально, учу регулярные выражения.'
result = re.match(pattern, string)
print(result)
# В данном примере будет выведено <re.Match object; span=(0, 6), match='Привет'>
Warning
Обратите внимание, что re.match ищет ПЕРВОЕ совпадение В НАЧАЛЕ СТРОКИ. В примере выше re.match находит только первое вхождение pattern в string.
Если строка будет такая:
import re
pattern = 'Привет'
string = 'Как твои дела? Привет, нормально, учу регулярные выражения.'
result = re.match(pattern, string)
print(result)
# В данном примере будет выведено None
Функция fullmatch()#
Функция re.fullmatch() вернет объект сопоставления, если вся исходная строка соответствует шаблону Regular Expression.
re.fullmatch(pattern, string, flags=0)
Question
Предолжите свой пример использования!
Функция compile()#
В Python есть возможность заранее скомпилировать регулярное выражение, а затем использовать его. Это особенно полезно в тех случаях, когда регулярное выражение много используется в скрипте.
Использование компилированного выражения может ускорить обработку, и, как правило, такой вариант удобней использовать, так как в программе разделяется создание регулярного выражения и его использование. Кроме того, при использовании функции re.compile создается объект RegexObject, у которого есть несколько дополнительных возможностей, которых нет в объекте MatchObject.
re.compile(pattern, flags=0)
Question
Предолжите свой пример использования!
Функция finditer()#
Метод finditer() используется для поиска всех непересекающихся совпадений в шаблоне и возвращает итератор с объектами Match (finditer возвращает итератор даже в том случае, когда совпадение не найдено). Функция finditer отлично подходит для обработки тех команд, вывод которых отображается столбцами.
re.finditer(pattern, string, flags=0)
Примеры использования:
import re
pattern = 'Привет'
string = 'Привет, как твои дела? Привет, нормально, учу регулярные выражения.'
result = re.finditer(pattern, string, 0)
for i in result:
print(i)
# В данном примере будет выведено:
#<re.Match object; span=(0, 6), match='Привет'>
#<re.Match object; span=(23, 29), match='Привет'>
Match Object#
Match Object — это объект, содержащий информацию о поиске и результате.
Объект Match имеет свойства и методы, используемые для получения информации о поиске и результате:
.span()возвращает кортеж, содержащий начальную и конечную позиции совпадения..stringвозвращает строку, переданную в функцию,.group()возвращает часть строки, в которой произошло совпадение
Полезные материалы по теме#
-
https://regex101.com/ — интерактивная консоль регулярных выражений, которая позволяет отлаживать выражения в режиме реального времени. Это означает, что вы можете создавать свои выражения и одновременно видеть, как они влияют на набор данных на одном экране. Инструмент был создан Фирасом Дибом при участии многих других разработчиков. Это крупнейший сервис тестирования регулярных выражений в мире.
-
http://www.pyregex.com/ — онлайн-тестер регулярных выражений для проверки правильности регулярных выражений в подмножестве регулярных выражений языка Python.
-
https://pythex.org/ — Pythex — редактор регулярных выражений для Python в реальном времени, быстрый способ проверить свои регулярные выражения.
Полный список шаблонов регулярных выражений#
| Шаблон | Соответствие |
|---|---|
| \n | Новая строка |
| . | Любой символ, кроме символа новой строки. Если flag=re.DOTALL — любой символ. |
| \s | Любой символ пробела, табуляции или новой строки. |
| \S | Любой символ, кроме пробела, табуляции или новой строки. |
| \d | Любая цифра. Эквивалентно [0-9] |
| \D | Любой символ, кроме цифр. Эквивалентно [^0-9] |
| \w | Любая буква, цифра или _. |
| \W | Любой символ, кроме букв, цифр и _. |
| \b | Символ между символом, совпадающим с \w, и символом, не совпадающим с \w в любом порядке. |
| \B | Символ между двумя символами, совпадающими с \w или \W. |
| \A | Начало всего текста |
| \Z | Конец всего текста |
| ^ | Начало всего текста или начало строки, если flag=re.MULTILINE |
| $ | Конец всего текста или конец строки, если flag=re.MULTILINE |
| \r | Carriage return или CR, символ Юникода U+2185. |
| \t | Tab символ |
| \0 | Null, символ Юникода U+2400. |
| \v | Вертикальный пробел в Юникоде |
| \xYY | 8-битный символ с заданным шестнадцатеричным значением. Таблица юникода. Например, \x2A находит символ *. |
| \ddd | 8-битный символ с заданным восьмеричным значением. Таблица UTF-8 |
| [\b] | Символ backspace или BS. В скобках, так как \b уже занят другим спецсимволом. |
| \f | Символ разрыва страницы |
Проверь себя#
Наберите 10 баллов при помощи следующего тренажера:
Парсинг на Python#
Процесс создания своего парсера может показаться достаточно сложным и запутанным для новичков, особенно если нужно писать программу с чистого листа. Ситуацию меняет наличие готовых профильных библиотек, таких как Beautiful Soup — библиотека на Python, языке, который идеально подходит для новичков.
Важно:
Несмотря на название, Beautiful Soup не имеет отношения к приготовлению супа. Это инструмент для парсинга, который помогает пройти инструкцию шаг за шагом. Поехали!
Beautiful Soup#
Beautiful Soup — библиотека для Python, созданная для ускорения написания собственных утилит парсинга web-страниц. Она преобразует HTML-код в структуру, похожую на индексированный словарь.
Разработчики ставили задачу упростить жизнь программистам, ведь задачи парсинга встречаются в самых разных технических проектах — это не только сбор информации о конкурентах или автоматизация мультиаккаунтов.
Ключевые особенности Beautiful Soup:
- Простые методы и идиомы для навигации, поиска и изменения дерева синтаксического анализа.
- Быстрое преобразование документов в Unicode и UTF-8.
- Совместимость с популярными парсерами: lxml и html5lib (переключение через параметры в коде).
Ещё важно знать:
- Первый релиз — в 2004 году, библиотека активно развивается и обновляется до сих пор.
- Распространяется по лицензии MIT, поэтому подходит даже для коммерческих приложений.
- Создание комплексных парсеров занимает минуты вместо часов или дней.
- Требует минимального количества собственного кода.
- Поддерживает извлечение данных из HTML и XML.
- Может интегрироваться с headless-браузерами, принимая от них готовый HTML для анализа.
- Автор — Леонард Ричардсон, python-разработчик и писатель-фантаст.
Как работает Beautiful Soup?#
Библиотека превращает сложный HTML-документ в дерево объектов Python четырёх типов:
Tag, NavigableString, BeautifulSoup и Comment.
К тегам можно применять методы и атрибуты, что значительно ускоряет обработку документа.
Например, можно быстро получить выборки вроде «все ссылки страницы» или «все цитаты». Также доступно перемещение по элементам на одном уровне — первый, второй, третий, последний и так далее.
Основные этапы веб-скрапинга с помощью Beautiful Soup#
Чтобы начать парсить сайты, вам нужно подготовить программную среду, то есть установить Python, затем саму библиотеку, а также ряд других компонентов, и только потом переходить к практической реализации – к написанию скриптов.
Давайте разобьём всё на шаги и пройдём по каждому подробнее.
Понимание основ структуры HTML#
HTML – это язык гипертекстовой разметки. По факту это набор специальных тегов и их параметров, которые предназначены для чтения браузером. Браузер на основе HTML-тегов отрисовывает итоговую версию страницы.
Простейший пример HTML-страницы:
<!DOCTYPE html>
<html>
<head>
<title>Это заголовок страницы, который отображается в результатах поисковой выдачи, а также при наведении курсора на вкладку браузера</title>
<meta charset="utf-8">
</head>
<body>
<h1>А это заголовок, который показывается в теле страницы</h1>
<p>
Это просто абзац, внутри может быть какой-то текст с описанием чего-то полезного…
</p>
<h2>Подзаголовок, пусть будет название списка «Типы прокси»:</h2>
<ul id="thebestlist">
<li>Резидентные прокси</li>
<li>Мобильные прокси</li>
<li>Общие прокси</li>
<li>Датацентровые прокси</li>
<li>Приватные прокси</li>
</ul>
</body>
</html>
Можете открыть любой текстовый редактор, скопировать в него весь код, приведённый выше, и сохранить в виде текстового файла в любом каталоге на компьютере. Обязательно смените расширение файла с .txt на .html.
Если открыть этот файл в браузере, то вы увидите подзаголовок и список разных типов прокси. Никакого лишнего кода не будет.
Теги <head>, <body>, <p>, <ul>, <li> и прочие нужны только для браузера. Большинство тегов имеет открывающий и закрывающий элемент:
<li>Содержимое тега</li>, где закрывающий тег содержит косую черту.
Но иногда тег может содержать только один элемент, например:
<img src="images/some-img.png" alt="Альтернативный текст">.
Внутри тегов могут использоваться стили и другие атрибуты. Пример:
<a href="https://site.name/index.html">Это ссылка</a> — здесь с помощью href передаётся URL-адрес страницы.
По аналогии работают стили, классы и идентификаторы:
<div class="container large-box">
<!-- Какой-то блок. Кстати, так в HTML записываются комментарии, они не показываются пользователям в браузере, но видны в коде -->
</div>
У нашего div-блока сразу два CSS-класса – «container» и «large-box». Обработчику CSS можно описать параметры декорирования блока с помощью специального синтаксиса.
Пример:
<style>
.container {
background-color: yellow;
font-size: 18px;
}
</style>
Стили можно описать прямо в HTML-коде, заключив между тегами <style>…</style>, а можно подключить в виде ссылки на файл, например:
<link rel="stylesheet" type="text/css" href="https://site.name/styles.css">.
Реже стили описываются прямо внутри тега (инлайн).
Если вы хотите погрузиться глубже в HTML, CSS и JavaScript, можно изучить официальные спецификации или пройти профильные курсы.
Наша сегодняшняя задача — дать понять, как работает парсер. Поэтому остановимся на том коде, который мы привели выше.
Выполнение HTTP-запросов и парсинг HTML с помощью Beautiful Soup#
Создайте папку для своих Python-скриптов. Пусть это будет «C:\My-first-parser».
Скопируйте содержимое HTML, которое мы привели во втором пункте, и сохраните в виде файла sample.html в папке с python-скриптами: C:\My-first-parser\sample.html. (Или воспользуйтесь файлом)
В том же каталоге создайте свой первый скрипт:
- Переместитесь в каталог C:\My-first-parser.
- Создайте текстовый файл. Пусть это будет true-code.txt.
- Смените расширение с .txt на .py. Должно получиться true-code.py.
- Откройте файл в текстовом редакторе и наполните его содержимым (будьте внимательны к пробелам в начале строк, Python их учитывает):
from bs4 import BeautifulSoup
with open('sample.html', 'r') as file:
content = file.read()
soup = BeautifulSoup(content, "html.parser")
for child in soup.descendants:
if child.name:
print(child.name)
- Сохраните файл.
- Запустите свой первый python-парсер (наберите в консоли): python C:\My-first-parser\true-code.py
Должно вывестись что-то похожее:
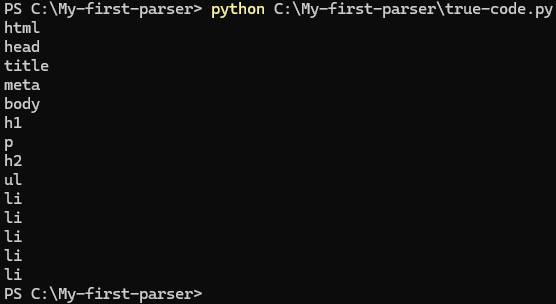
Примерно так видит ваш документ библиотека Beautiful Soup. Она проиндексировала все HTML-элементы и создала на их основе готовый массив. Зная синтаксис команд Beautiful Soup, очень легко делать выборку по такому массиву.
В примере мы считывали готовый файл. А вот так можно обратиться к реальному сайту:
import requests
from bs4 import BeautifulSoup
response = requests.get("https://news.ycombinator.com/")
if response.status_code == 200:
html_content = response.content
print(html_content)
else:
print(response)
soup = BeautifulSoup(html_content, "html.parser")
for child in soup.descendants:
if child.name:
print(child.name)
После исполнения такого скрипта в консоли сначала будет выведен весь HTML-код страницы, а затем последовательно названия всех HTML-элементов, уже после обработки библиотекой BeautifulSoup.
import requests
from bs4 import BeautifulSoup
Здесь мы импортируем библиотеки requests и bs4 (BeautifulSoup).
response = requests.get("https://news.ycombinator.com/")
Обращаемся к конкретной странице, «https://news.ycombinator.com/». Метод requests.get() заимствован из библиотеки requests. Он возвращает ответ севера.
Далее мы анализируем ответ сервера:
if response.status_code == 200:
Если код ответа 200 (это значит, что сервер работает и страница, к которой вы обращаетесь, существует), тогда мы извлекаем HTML-содержимое и наполняем переменную html_content.
html_content = response.content
Чтобы убедиться, что переменная наполнена, выводим её в консоль:
print(html_content)
Но ведь мы не использовали Beautiful Soup! Создаём переменную soup и обращаемся к методу BeautifulSoup(). Передаём ему наш HTML-контент и просим распарсить.
soup = BeautifulSoup(html_content, "html.parser")
Атрибут .descendants перебирает все дочерние теги внутри корневого тега <html> и получает массив. Нам остаётся только последовательно вывести имена найденных тегов, это делается в цикле for:
for child in soup.descendants:
if child.name:
print(child.name)
Навигация и извлечение данных#
Усложним задачу: выведем заголовок страницы, посчитаем все ссылки и спарсим только текст.
Скопируете код ниже и замените содержимое файла C:\My-first-parser\true-code.py.
import requests
from bs4 import BeautifulSoup
# Запрашиваем HTML-содержимое страницы и передаём его в переменную html_content, если код ответа сервера отличается от 200, то выводим только ответ
response = requests.get("https://news.ycombinator.com/")
if response.status_code == 200:
html_content = response.content
else:
print(response)
# Передаём HTML-содержимое на анализ в библиотеку BeautifulSoup
soup = BeautifulSoup(html_content, "html.parser")
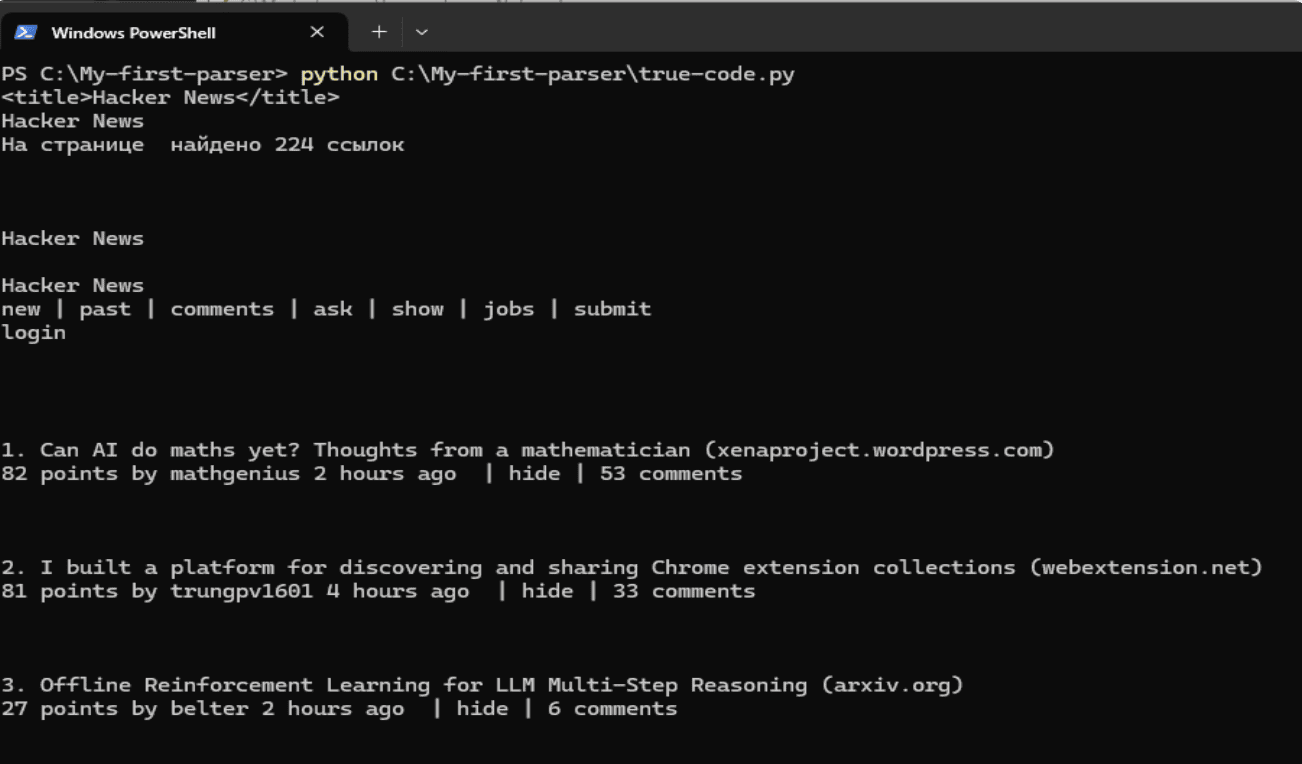
# Выводим весь тег title
print(soup.title)
# То же самое, но уже без тегов вокруг, только содержимое
print(soup.title.string)
# Ищем все ссылки, найденные на странице (по тегу <a>) и считаем их количество
all_links = len(soup.find_all("a"))
print(f"На странице найдено {all_links} ссылок")
# Весь текст со страницы
print(soup.get_text())
На выходе должно получиться что-то похожее:
Так как сайт может не работать или его содержимое может измениться, вернёмся к нашему HTML-файлу (чтобы результат был гарантированным).
Попробуем найти в нём список (тег ul) с идентификатором «thebestlist», а затем выведем все элементы списка (они имеют тег li).
Код скрипта:
from bs4 import BeautifulSoup
# Открываем наш HTML-файл и передаём содержимое в переменную htmlcontent
with open('sample.html', 'r') as file:
htmlcontent = file.read()
soup = BeautifulSoup(htmlcontent, "html.parser")
# Ищем тег ul с атрибутом id=thebestlist. Обратите внимание, если элементов будет несколько, будет выведен только первый. Так как у нас список только один, он будет "напечатан" весь, вместе с дочерними элементами
print(soup.find('ul', attrs={'id': 'thebestlist'}))
# А тут в цикле перебираем все найденные теги li (то есть элементы списка)
for tag in soup.find_all('li'):
print(tag.text)
А вот так выглядит вывод консоли (если вдруг, вы работаете в Windows с кириллицей, то проследите за тем, чтобы кодировка HTML-файла соответствовала штатной кодировке ОС, то есть ANSI):
Продвинутые методики работы с Beautiful Soup#
Самая сложная задача – парсинг динамических сайтов.
Такие сайты не имеют конечной HTML-структуры, точнее, содержат только её часть, в которой указываются ссылки на JS-скрипты. Всё содержимое выстраивается непосредственно в браузере – после исполнения JavaScript-кода.
Beautiful Soup не умеет исполнять JS, поэтому вам понадобится полноценный браузер, чтобы сначала отрендерить страницу, а потом передать библиотеке результирующий HTML-код.
Чтобы максимально усложнить задачу, выгрузим массив найденных элементов в CSV-файл (в понятном многим табличном формате).
Вот так может выглядеть интеграция анализатора Beautiful Soup с headless-браузерами и экспортом в файл:
Сначала установим Selenium (вместо него могут использоваться и другие веб-драйверы, например, Playwright или Puppeteer, это инструменты для тестирования сайтов).
pip install selenium
Ну и для работы с CSV установим Pandas
pip install pandas
Итоговый скрипт будет выглядеть так:
# Подключаем библиотеки
from selenium import webdriver
from bs4 import BeautifulSoup
import pandas as panda
# Открываем headless-браузер Хром
driver = webdriver.Chrome()
# Передаём браузеру адрес страницы и получаем контент
driver.get("http://quotes.toscrape.com/js/")
# Сохраняем результирующее содержимое в переменную js_content
js_content = driver.page_source
# Передаём содержимое на анализ внутри парсера BeautifulSoup
soup = BeautifulSoup(js_content, "html.parser")
# Ищем все теги span с классом text, наполним ими массив quotes
quotes = soup.find_all("span", class_="text")
# Передаём массив в библиотеку Pandas и пишем данные в файл quotes.csv, кодировка 'cp1251' нужна для нормального отображения кириллицы в Windows
df = panda.DataFrame({'Цитаты': quotes})
df.to_csv('quotes.csv', index=False, encoding='cp1251')
# На всякий случай дублируем вывод массива в консоли
print(quotes)
Согласитесь, это уже больше похоже на профессиональный подход. При этом объём кода реально мизерный.
Осталось самое страшное – прокси!
Ипользование прокси#
Многие крупные сайты и веб-сервисы защищаются от ботов. Плюс, если вы хотите ускорить процесс сбора информации, нужно задействовать несколько параллельных потоков. Всё это невозможно без прокси.
Для парсинга используются разные типы прокси: серверные, мобильные и резидентные, прямые и с обратной связью, на базе http или socks-протокола.
# Подключаем библиотеки
from selenium import webdriver
from selenium.webdriver.common.proxy import *
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
# Сюда вписываем ваши параметры прокси
myProxy = "188.114.98.233:80"
proxy = Proxy({
'proxyType': ProxyType.MANUAL,
'httpProxy': myProxy,
'sslProxy': myProxy,
'noProxy': ''})
# Устанавливаем параметры запуска службы web-драйвера для headless-браузера с использованием прокси, опций может быть больше, например, здесь же можно установить свой user-агент и т.п.
options = Options()
options.proxy = proxy
# Запускаем веб-драйвер Chrome с нашими опциями
driver = webdriver.Chrome(options=options)
# Передаём браузеру целевую страницу
driver.get("https://httpbin.io/ip")
# Сохраняем результирующее содержимое в переменную content
content = driver.page_source
# Передаём содержимое на анализ внутри парсера BeautifulSoup
soup = BeautifulSoup(content, "html.parser")
# Ищем содержимое тега <pre>
yourip = soup.find("pre")
# Выводим IP
print(yourip.text)
# Освобождаем ресурсы и закрываем экземпляр браузера
driver.quit()
Если соединение через прокси будет успешным, то вы увидите его IP-адрес в формате:
{
"origin": "188.114.98.233:80"
}
Это только часть «сложного» функционала. По мере совершенствования навыков программирования можно задуматься о следующих вещах:
- Обработка пагинации и подгрузки динамического контента на одной странице.
Поддержка экспорта в JSON и XML. - Подмена и ротация user-агента, а также других HTTP-заголовков, которые отдают браузеры. - - Эмуляция полноценных цифровых отпечатков (например, вместо headless-браузеров можно начать использовать антидетект-браузеры, у них тоже есть API, но управлять большим количеством пользовательских профилей здесь гораздо удобнее).
- Многопоточность и управление задержками. Слишком частые автоматические запросы или запросы с равными промежутками времени быстро вычленяются и легко блокируются, затрудняя парсинг.
В поисках тренировочного объекта#
Теперь, чтобы расслабиться представим, что вы не просто студенты, которые вынуждены парсить данные. Вы юные Асы, обитетли цифрового царства Асгард, собирающие в csv свитки все данные этого мира.

Однажды Один, верховный правитель богов заинтересовался тем, как обстоят дела в Мидграде с транспортными услугами. Из всего огромного шара его заинтересовала особенно Москва. Вам было выдан указ - любой ценой получит данные об организаторах перевозок такси Москвы.
По счастью, у вас был соответсвующий кабель, позволяющий не покидая заоблочных высот быстренько подсоединиться к сети смертных. Зайдя в поисковик вы находите следующий прекрасный сайт, где находится целых 338 объявлений.
Сроки поджимали, стресс накапливался. Тогда по наивности вы решили обратиться к мастеру всех уловок, трюков и веселью - Локи. Не долго думая, хитрейший вам предложил воспользоваться средствами вайб-коддинга. Вы чувствовали, что так делать не надо, но поддались искушению.

Так началось сказание, что вы не прочьтете в Старшей Эдде...
История о том, почему LLM вам не поможет#
Всё началось, когда юные Асы, вдохновлённые хитростью Локи, решили: "А что если просто спросить у Великой Модели — и она всё сделает за нас?" И вправду, ведь LLM (та самая магическая Large Language Model) умеет писать код, сочинять песни и даже объяснять квантовую физику, почему бы ей не справиться с каким-то сайтом?
Но вскоре пришло разочарование. Вот почему:
- LLM не выходит в интернет
Большинство LLM, включая даже мудрейшие из GPT, не умеют ходить по сайтам. Они не могут открывать страницы, кликать кнопки или видеть, что реально загружается в браузере. Они не «живут» в браузере, а значит:
Warning
Если сайт подгружает данные с помощью JavaScript — модель не увидит этих данных вообще.
- Модель не знает конкретную структуру DOM
HTML-страницы могут выглядеть просто, но часто их структура запутана, обфусцирована, и с кучей вложенных классов вроде div[class^=styles-module__root_]. Модель может лишь предположить, как устроен HTML, но:
Warning
Если структура сайта изменилась — её догадки станут бесполезными.

- LLM не знает о защитах
Сайты могут использовать антибот-защиту — капчи, rate-limiting, cookies, user-agent фильтрацию и многое другое. Модель не сможет:
Warning
Обойти защиту или правильно сымитировать поведение настоящего браузера без участия человека.

- LLM — не исполнитель, а советчик
LLM может предложить пример кода, подсказать, как использовать requests, BeautifulSoup, Selenium или Playwright. Но она:
Warning
Не исполняет код, не проверяет результат и не исправляет ошибки в реальном времени.