Введение в Data Science#
Мы живём в эпоху, когда объёмы данных растут с беспрецедентной скоростью и становятся неотъемлемой частью повседневной жизни. Современные веб-сайты фиксируют каждое взаимодействие пользователя, включая все нажатия и действия. Смартфоны непрерывно собирают информацию о местоположении и скорости перемещения в режиме реального времени.
Иные носимые устройства, такие как фитнес-браслеты и умные часы, постоянно мониторят физиологические показатели — сердечный ритм, активность, режимы питания и сна. Умные автомобили регистрируют особенности стиля вождения владельцев, а системы умного дома собирают данные о поведении и привычках своих обитателей. Современные маркетинговые технологии анализируют покупательское поведение на основе больших объёмов информации.
Сам Интернет представляет собой масштабный граф знаний, включающий гипертекстовые энциклопедии, специализированные базы данных по фильмам, музыке, спорту, видеоиграм, мемам и рецептам. Кроме того, доступно множество статистических отчётов от различных государственных органов, которые хотя и могут содержать погрешности, отражают реальное положение дел. Вся эта совокупность данных позволяет получить обширное представление о мире.

В этих данных скрываются ответы на множество вопросов, которые раньше не ставились. Анализ и интерпретация такого объёма информации открывают новые горизонты для науки, бизнеса и повседневной практики.
Что такое наука о данных?#
Наука о данных (Data Science) — это междисциплинарная область знаний, которая занимается сбором, обработкой, анализом и интерпретацией больших объёмов данных с целью извлечения ценной информации и принятия обоснованных решений. В современном мире, где данные создаются и накапливаются в огромных количествах, именно наука о данных помогает выявлять скрытые закономерности, тренды и взаимосвязи, которые невозможно заметить без использования специальных методов и инструментов.
Наука о данных позволяет принимать более качественные решения и решать сложные задачи. Компании совершенствуют свои продукты и услуги, используя науку о данных, чтобы узнать, что нравится и что не нравится клиентам. Врачи анализируют данные пациентов и разрабатывают более эффективные методы лечения заболеваний. Даже в обычной жизни наука о данных лежит в основе персонализированных предложений на потоковых сервисах или в социальных сетях, помогая зрителям найти контент, который им понравится.
Исходные данные состоят из признаков, часто называемых независимыми переменными, а ценные знания являются целью модели, обычно называемой зависимой переменной.
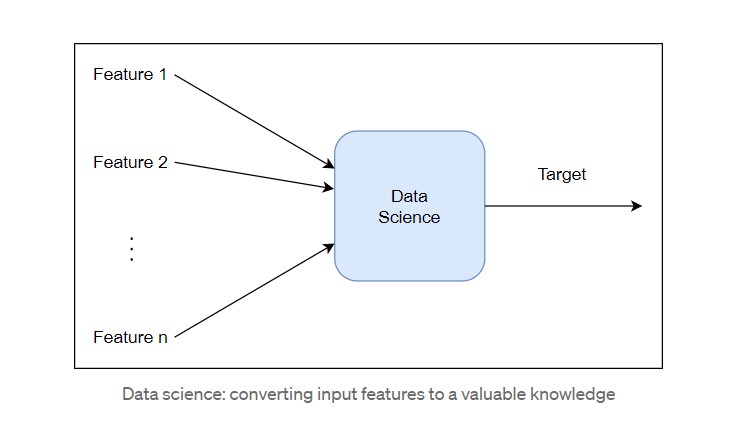
Рабочий цикл data scientist-а#
Прежде чем перейти к обсуждению различных методов и инструментов, применяемых в науке о данных, начнём с описания основного рабочего цикла data scientist-а. Этот процесс представляет собой итеративную последовательность шагов, которая позволяет специалисту извлекать смысл из сырых и зачастую хаотичных данных.
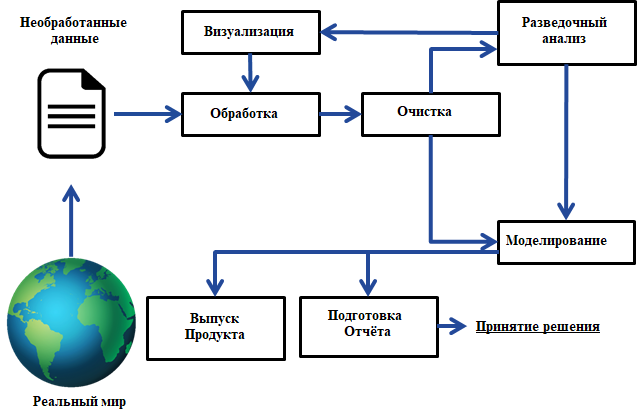
Схема иллюстрирует цикл работы с данными, начиная от их получения из реального мира до принятия решений и выпуска продуктов. В центре внимания — этапы обработки, анализа и моделирования данных.
-
Реальный мир
Источник информации, откуда поступают необработанные данные (например, сенсоры, веб-сервисы, базы данных). -
Необработанные данные
Сырые данные, требующие приведения к пригодному виду для последующего анализа. -
Обработка
Первый шаг преобразования данных, может включать фильтрацию, форматирование, агрегацию и базовые преобразования. -
Очистка
Удаление шумов, пропущенных значений, аномалий и дубликатов. Критический этап, обеспечивающий качество всего дальнейшего анализа. -
Разведочный анализ (EDA)
Исследование структуры и характеристик данных, выявление взаимосвязей, распределений и трендов. -
Визуализация
Создание графиков, диаграмм и других наглядных форм представления информации, помогающих выявить закономерности и аномалии. -
Моделирование
Построение моделей машинного обучения или статистического анализа для прогнозирования или классификации. Основано на очищенных и проанализированных данных. -
Принятие решения
Использование результатов модели для поддержки бизнес- или научных решений. -
Выпуск продукта
Интеграция модели или её результатов в программные решения, приложения или сервисы. -
Подготовка отчёта
Документирование результатов анализа, создание отчётности для заказчиков, стейкхолдеров или публикаций.
Сбор данных#
На первом этапе осуществляется получение информации из различных источников, включая базы данных, электронные таблицы, API-интерфейсы, а также изображения, видеозаписи и данные от разнообразных сенсоров. Особое внимание уделяется качеству и достоверности информации, поскольку ошибки на этом этапе могут существенно повлиять на весь дальнейший анализ. Кроме того, важно учитывать этические аспекты, связанные с приватностью и добровольным согласием на обработку персональных данных.
Предварительная обработка#
Этот этап предполагает очистку и трансформацию данных, чтобы сделать их пригодными для анализа. В процессе предварительной обработки устраняются пропуски, нормализуются значения, приводятся к единому формату категориальные переменные, и в целом создаётся согласованная и чистая структура данных.
Разведочный анализ данных (EDA)#
На этапе EDA данные исследуются с целью выявления их ключевых характеристик. В число типичных задач входят:
- анализ распределения признаков и переменных;
- поиск закономерностей, трендов и возможных взаимосвязей;
- обнаружение аномалий и потенциальных источников ошибок.
Разведочный анализ помогает сформировать гипотезы и определить направления дальнейшей работы с моделью.
Обучение модели#
На этом этапе используются алгоритмы машинного обучения для построения модели, способной делать выводы или предсказания на основе имеющихся данных. Процесс обычно включает:
- выбор подходящего метода с учётом специфики задачи и данных;
- обучение модели на подготовленных выборках;
- настройку гиперпараметров и проверку корректности обучения.
Оценка модели#
После построения модели её необходимо оценить по ряду количественных показателей, чтобы понять, насколько точно она решает поставленную задачу. Выбор метрик зависит от типа проблемы (например, классификация или регрессия) и может включать точность, полноту, F1-меру, среднеквадратичную ошибку и другие. Сравнение предсказаний модели с фактическими результатами позволяет выявить её слабые стороны.
Развертывание#
Когда модель прошла оценку и показала хорошие результаты, наступает этап внедрения в практическую систему. Это может включать интеграцию с веб-приложением, автоматизацию процессов принятия решений или создание API-доступа. Важно также настроить мониторинг, чтобы отслеживать стабильность и качество работы модели в реальной среде. Постоянная обратная связь позволяет своевременно выявлять отклонения и производить дообучение при необходимости.
Основы анализа данных#
Зададимся вопросом: Что такое даныне и какими они бывают?
Note
Данные — это сведения, которые могут принимать различные формы
По способу представления есть два основных типа данных:
- Структурированные. Организованные данные, собранные в таблицы или базы, например, сведения о клиентах, их контактах и заказах в CRM-системе. Их легко анализировать и обрабатывать.
- Неструктурированные. Данные без четкой структуры, представленныеая в различных форматах, например, текстовый бриф, скриншоты с сайтов конкурентов и запись видеозвонка. Работать с ними довольно сложно.
Также данные можно разделить по типу значений на:
Числовые — представленные в виде чисел. Бывают двух видов:
Дискретные. Отдельные значения, которые обычно можно посчитать. Примеры: количество людей, которые посетили сайт, или число проданных товаров.
Непрерывные. Принимают любое значение в пределах определенного диапазона и обычно измеряются. Примеры: рост человека, температура воздуха или время, прошедшее с начала эксперимента.
Категориальные — данные, в которых значения переменных принадлежат одной из нескольких категорий или групп. Могут включать разные переменные, например, цвета, виды животных, пол человека. Делятся на два типа:
Номинальные. Самый простой тип, где каждая категория не имеет порядкового значения. Примеры: марки автомобилей или названия городов.
Порядковые. Имеют определенную последовательность, часто — от худшего к лучшему. Примеры: оценки качества («плохая», «средняя», «хорошая») или уровни образования («бакалавр», «магистр», «доцент»).
Булевые — это данные, которые могут принимать только два значения: — True (истина) или False (ложь). Этот тип получил название в честь Джорджа Буля, английского математика и логика, который разработал основы алгебры логики. Булевые данные помогают определить — «да» или «нет». Например, у пациента либо есть диабет, либо нет, у соискателя на должность водителя либо есть права категории Б, либо нет.
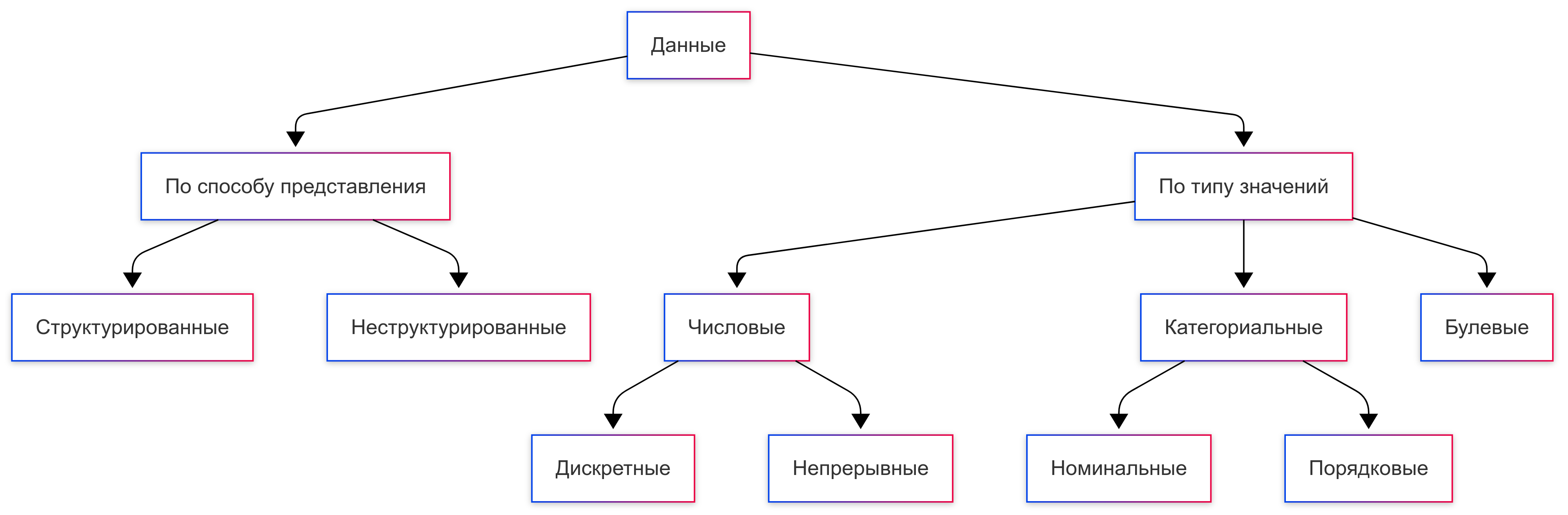
Рассмотрим на примере. У подержанных автомобилей есть разные сведения. Например, числовые (возраст машины, пробег), категориальные (марка, цвет), булевые (попадала машина в аварии или нет).
Что такое анализ данных и для чего он нужен#
Анализ данных — это процесс изучения и обработки данных. Он необходим для извлечения полезной информации и принятия обоснованных решений. Его можно сравнить с пазлом: нужно собрать отдельные части, чтобы увидеть общую картину.
С помощью анализа удается понять, что значат данные, и как их использовать. В результате можно находить закономерности и тренды, выявлять аномалии и составлять прогнозы. И благодаря этому делать более обоснованные выводы, а значит — принимать взвешенные решения.
При анализе нередко возникают ошибки по разным причинам. Во-первых, из-за того, что данные собраны некорректно или содержат слишком много неточностей. Во-вторых, когда наблюдается случайная корреляция без причины: два явления могут происходить параллельно, но не иметь причинно-следственной связи. Например, рост количества студентов-медиков и снижение числа людей, которые на пенсии выращивают кактусы. В-третьих, из-за неверного выбора визуализации, которая искажает восприятие данных. Наконец, нельзя забывать о человеческом факторе: иногда исследователь так стремится найти в данных подтверждение своей гипотезы, что перестает анализировать объективно. По сути — «видит то, что хочет видеть».
Чтобы снизить риск ошибок, важно уделять достаточно времени сбору данных и их проверке. Если вместо полезных сведений — «мусор», работа не имеет смысла.
Какие существуют методы анализа данных#
Рассмотрим основные способы анализа данныхы для решения разных задач.
Описательный#
Название говорит само за себя: метод помогает описать и обобщить основные характеристики данных, полученных в прошлом. Благодаря этому можно понять тенденции и обнаружить закономерности.
Чтобы найти среднее значение, медиану, моду или стандартное отклонение, нужно обратить внимание на распределение данных. Например, по такому принципу работают сервисы Google Аналитика и Яндекс Метрика. С их помощью можно отслеживать и исследовать разные данные, например, количество посетителей сайта за конкретный промежуток времени или устройства, которыми чаще всего пользовались при переходе на сайт.
Корреляционный#
С его помощью можно определить взаимосвязи между переменными и понять, как одна влияет на другую. Благодаря этому получится выяснить, как одно явление меняется относительного другого: — увеличивается, уменьшается или остается неизменным. Например, как возраст человека связан с тем, сколько лет он проработал на конкретной должности.
Если две переменные коррелируют, нельзя однозначно сказать, что они влияют друг на друга. Чтобы выяснить, есть ли причинно-следственная связь, нужно провести дополнительное исследование.
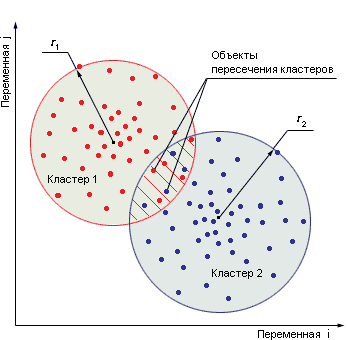
Кластерный#
Этот тип анализа предполагает разделение данных на группы (кластеры) по определенным признакам. Их нужно изучить, чтобы найти закономерности. Например, данные о покупателях можно кластеризовать в зависимости от их поведения: как часто совершают покупки или когда что-то покупали в последний раз. Эта информация поможет выстроить маркетинговую стратегию.
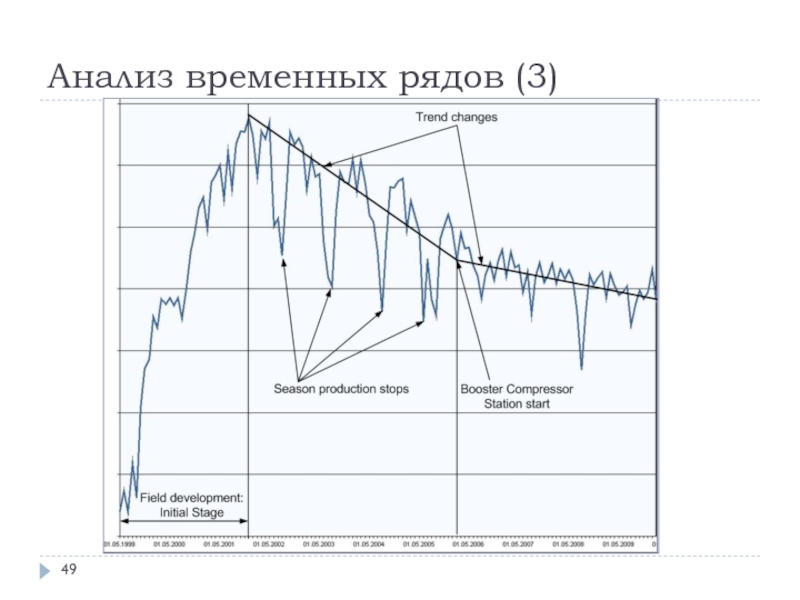
Анализ временных рядов#
Метод используют при работе с временными рядами, когда данные меняются со временем. Это может быть курс валют или показатель рождаемости. Анализ помогает выявить тенденции, сезонные колебания и сделать прогноз будущих значений. Так, финансовые аналитики изучают, как менялась стоимость акций в течение последних месяцев, и делают выводы о цене в ближайшем будущем.
Аналитиком данных может быть каждый?#
Профессия аналитика данных (Data Analyst) в последние годы стала одной из самых востребованных в мире. С ростом объемов данных и их значимости для бизнеса, науки и общества возникает вопрос: может ли каждый стать аналитиком данных? Этот вопрос требует рассмотрения необходимых навыков, личностных качеств и доступности обучения, чтобы понять, насколько эта профессия открыта для широкого круга людей.
Что требуется от аналитика данных?#
Аналитик данных — это специалист, который собирает, обрабатывает и анализирует данные, чтобы предоставить бизнесу или организации ценные инсайты. Для этого необходимы следующие навыки:
- Технические навыки:
- Знание инструментов для работы с данными: Excel, SQL, Python или R для обработки и анализа.
- Навыки визуализации данных с использованием инструментов, таких как Tableau, Power BI или библиотеки Matplotlib и Seaborn.
- Понимание основ статистики и математики для проведения корректного анализа.
- Аналитическое мышление: Способность находить закономерности, задавать правильные вопросы и интерпретировать результаты.
- Предметные знания: Понимание контекста данных (например, знание специфики бизнеса, маркетинга или медицины).
- Навыки коммуникации: Умение презентовать результаты анализа понятным языком для коллег и руководства.
Эти требования могут показаться сложными, но большинство из них можно освоить с нуля при наличии желания и дисциплины.
Ложка дегтя в бочке современного этапа (четыре свидетельства от четерых команд)#
Современные исследования всё чаще поднимают вопрос о том, как использование генеративного искусственного интеллекта влияет на мышление, внимание и способность к анализу. Четыре актуальные статьи — из научных журналов, arXiv и отчётов индустрии — позволяют увидеть эту проблему с разных сторон.

Цель работы — выяснить, как использование AI-инструментов влияет на критическое мышление и способствует когнитивному выносу (cognitive offloading) — переносу умственных задач на внешние средства. В опросе приняли участие 666 респондентов разного возраста и уровня образования.
- Чем активнее участники использовали AI, тем сильнее проявлялось снижение способности к самостоятельному анализу.
- Ключевой медиатор — когнитивный вынос: люди передают часть умственной работы ИИ и теряют навык рассуждения.
- Образование смягчает эффект, но не полностью: наблюдается нелинейная зависимость — от определённого уровня интенсивное использование AI вновь снижает мышление.
📌 Вывод: для сохранения интеллектуальных навыков важно сочетать AI с активным размышлением, а не заменять одно другим.
Группа нейропсихологов из нескольких университетов исследовала, как использование AI-помощника влияет на мозговую активность при написании эссе. Эксперимент включал 54 человека, разделённых на 3 группы: с использованием LLM, с поисковиком и без помощи.
Группа, использующая LLM, показала значительное снижение мозговой активности в альфа- и бета-диапазонах (по данным ЭЭГ).
После нескольких сессий у этих участников наблюдалось снижение памяти, фокусировки и когнитивной гибкости.
📌 Вывод: чрезмерная опора на AI может привести к накоплению когнитивного долга — снижению ментальной вовлечённости и обучаемости в долгосрочной перспективе.
- (Исследование Microsoft Research и Carnegie Mellon — "The Impact of Generative AI on Critical Thinking")[https://www.microsoft.com/en-us/research/wp-content/uploads/2025/01/lee_2025_ai_critical_thinking_survey.pdf]
Цель: оценить, как генеративный AI влияет на повседневное принятие решений и критическое мышление среди “работников знаний”. Опрос охватил 319 специалистов, которые описали 936 случаев использования GenAI.
Участники, ставящие чёткие цели и проверяющие ответы AI, демонстрировали рост критических навыков.
Те же, кто излишне доверял AI, чаще соглашались с неточными или шаблонными выводами.
Уверенность в собственных способностях снижала вероятность “слепой” зависимости от AI.
📌 Вывод: генеративный AI может усиливать критическое мышление, если человек сохраняет контроль и активно проверяет полученные данные.
- (Исследование ИИ-подсказок и когнитивных искажений — arXiv:2506.12338)[https://arxiv.org/abs/2506.12338]
Группа учёных из Кембриджа и Google DeepMind исследовала, как когнитивные искажения (например, bias подтверждения, доступности) в подсказках (prompts) влияют на поведение больших языковых моделей.
Специально сформулированные biased-prompts приводили к снижению точности, повторению ложных утверждений и усилению шаблонности в выводах.
Даже нейтральные LLM демонстрировали подверженность формулировкам, содержащим скрытые установки.
📌 Вывод: формулировка запроса напрямую влияет на качество ответа AI. Разработка методов детектирования и смягчения искажений становится ключевой задачей при взаимодействии с LLM.
Когнитивные искажения#
Примеры запросов с когнитивными искажениями#
Когнитивные искажения — это систематические ошибки в мышлении, которые влияют на восприятие, оценку и принятие решений. Ниже приведены примеры запросов, демонстрирующие различные когнитивные искажения, с пояснениями.
Вы можете на досуге изучить прекрасную инфографику по когнитивным искажениям. Ниже мы остановимся на некоторых примерах.
Список примеров;
-
Эффект подтверждения (Confirmation Bias)
Запрос: "Найди доказательства того, что вакцинация вызывает аутизм."
Пояснение: Пользователь ищет информацию, подтверждающую его предубеждение, игнорируя или отвергая данные, которые могут опровергать эту точку зрения. -
Эвристика доступности (Availability Heuristic)
Запрос: "Насколько опасно летать на самолётах? Я только что видел новости о крушении."
Пояснение: Пользователь переоценивает риск авиакатастроф из-за недавнего яркого события, которое легко приходит на ум, хотя статистически полёты безопасны. -
Якорение (Anchoring)
Запрос: "Сколько стоит эта машина? Я видел похожую за 20 тысяч долларов."
Пояснение: Пользователь ориентируется на первую увиденную цену (якорь), что может исказить его восприятие реальной стоимости автомобиля. -
Фундаментальная ошибка атрибуции (Fundamental Attribution Error)
Запрос: "Почему мой коллега всегда опаздывает? Он просто безответственный?"
Пояснение: Пользователь приписывает поведение коллеги его личным качествам, не учитывая внешние факторы (например, пробки или семейные обстоятельства). -
Эффект Даннинга-Крюгера (Dunning-Kruger Effect)
Запрос: "Я прочитал пару статей по физике, объясни, почему теория струн — это ерунда."
Пояснение: Пользователь с минимальными знаниями переоценивает свою компетентность и делает поспешные выводы о сложной теме. -
Иллюзия контроля (Illusion of Control)
Запрос: "Какой ритуал мне провести, чтобы выиграть в лотерею?"
Пояснение: Пользователь верит, что может повлиять на случайный процесс (лотерею) с помощью действий, хотя результат полностью зависит от случая. -
Склонность к негативу (Negativity Bias)
Запрос: "Почему все новости только о плохом? Расскажи о катастрофах за этот год."
Пояснение: Пользователь фокусируется на негативной информации, игнорируя положительные события, что усиливает восприятие мира как более опасного. -
Эффект ореола (Halo Effect)
Запрос: "Я слышал, что этот актёр — отличный человек, какие благотворительные проекты он поддерживает?"
Пояснение: Пользователь предполагает, что положительные качества актёра (например, талант) распространяются на его моральные качества или действия.