Практика: Структурированный тип данных#
Структурированный тип данных – тип, характеристиками которого являются: множественность элементов, его структура, способ доступа к элементам, тип элементов и операции с данными этого типа. Множество значений такого типа определяется множеством значений его элементов и их количеством. Переменная или константа структурированного типа всегда имеет несколько компонент. Каждая из этих компонент, в свою очередь, может принадлежать структурированному типу, что позволяет говорить о возможной вложенности типов.
Структурированные типы данных классифицируют по следующим основным признакам:
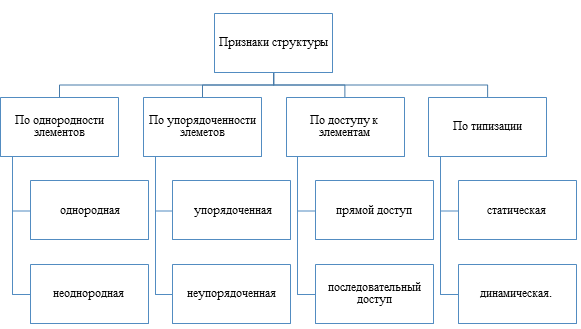
Эти признаки противостоят друг другу лишь внутри пары, а вне этого могут сочетаться.
Если все элементы, образующие структуру, однотипны (например – целые числа или символы), то структура является однородной; если же в ней «перепутаны» элементы разной природы (например, числа чередуются с символами), то неоднородной.
Структуру называют упорядоченной, если между ее элементами определен порядок следования. Примером упорядоченной математической структуры служит числовая последовательность, в которой у каждого элемента (кроме первого) есть предыдущий и последующий. Наличие индекса в записи элементов структуры уже указывает на ее упорядоченность (хотя индекс для этого не является обязательным признаком).
По способу доступа упорядоченные структуры бывают прямого и последовательного доступа. При прямом доступе каждый элемент структуры доступен пользователю в любой момент независимо от других элементов. Глядя на линейную таблицу чисел, мы можем списать или заменить сразу, допустим, десятый элемент. Однако, если эта таблица не на бумаге, а, скажем, каким-то образом записана на магнитофонную ленту, то сразу десятое число нам недоступно – надо сначала извлечь девять предшествующих. В последнем случае мы имеем дело с последовательным доступом.
Если у структуры размер (длина, количество элементов) не может быть изменен «на ходу», а фиксирован заранее, то такую структуру называют статической. Программные средства информатики иногда позволяют не фиксировать размер структуры, а устанавливать его по ходу решения задачи и менять при необходимости, что бывает очень удобно. Такую структуру называют динамической.
Характеристики структур данных следующие:
- Данные в памяти представлены определённым образом, который однозначно позволяет определить структуру.
- Xаще всего внутрь структуры можно добавить элемент или извлечь оттуда. Это свойство не постоянное — бывают структуры, которые нельзя изменять после создания.
- Существуют алгоритмы, которые позволяют взаимодействовать с этой структурой.
Рассмотрим подробнее примеры различных структур и сравним их реализацию в Python и C++
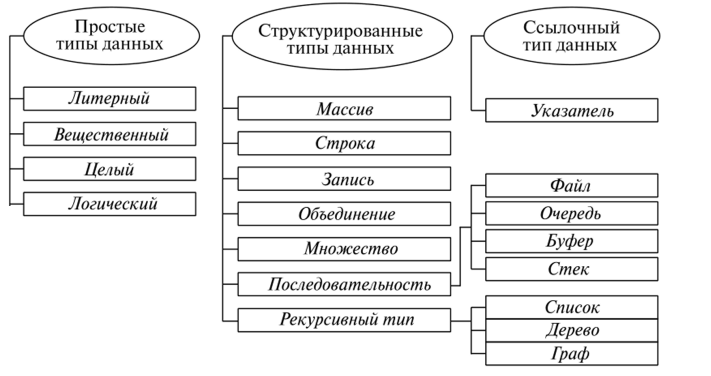
Множество#
Множества хранят данные без определенного порядка и без повторяющихся значений. Помимо возможности добавления и удаления элементов, есть несколько других важных функций, которые работают с двумя наборами одновременно. Особенность множества заключается в высокой скорости проверки принадлежности к нему элемента.
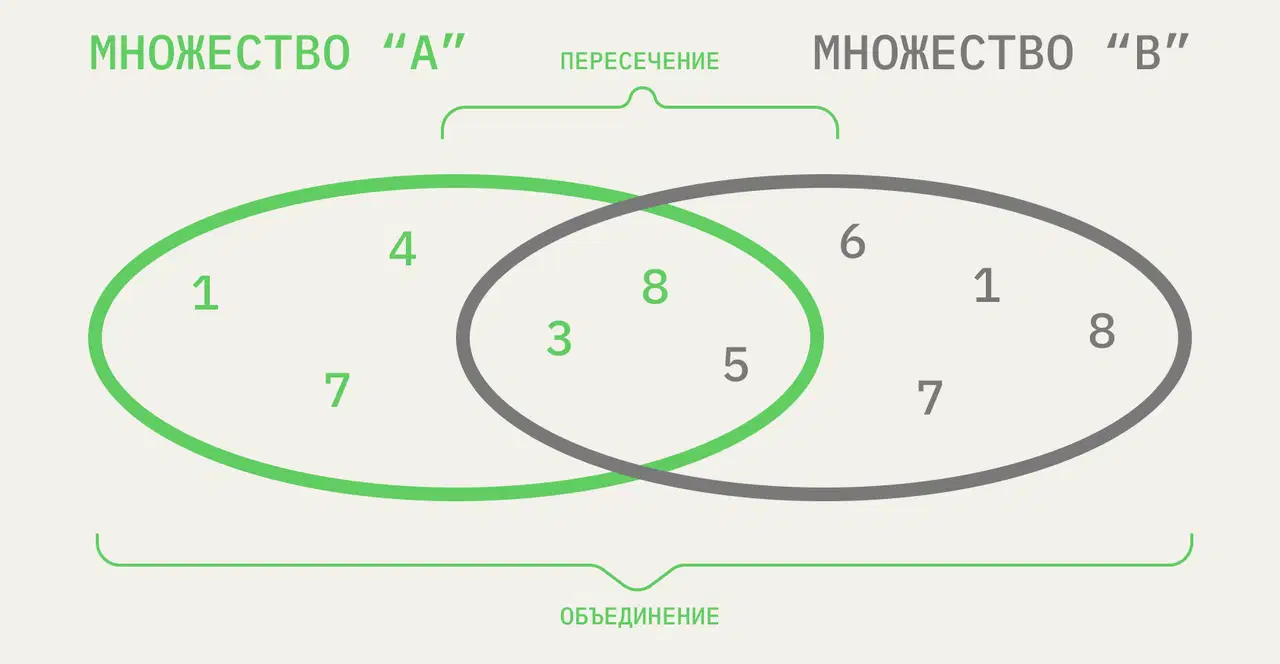
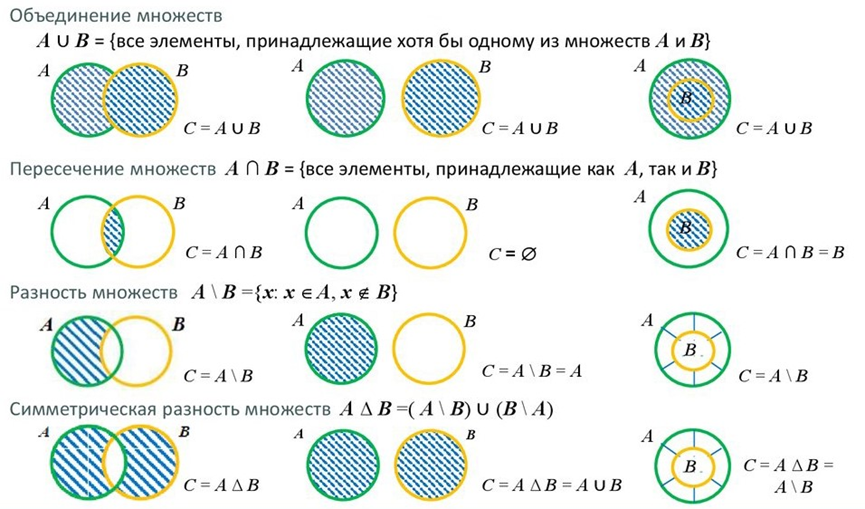
- Объединение комбинирует все элементы из двух разных множеств, превращая их в одно (без дубликатов).
- Пересечение анализирует два множества и создает еще одно из тех элементов, которые присутствуют в обоих изначальных множествах.
- Разность выводит список элементов, которые есть в одном множестве, но отсутствуют в другом.
- Подмножество выдает булево значение, которое показывает, включает ли одно множество все элементы другого множества.
Множество (set) представляет такой контейнер, который может хранить только уникальные значения. Как правило, множества применяются для создания коллекций, которые не должны иметь дубликатов.
Множество в С++#
Множества представлены типом std::set<>, который определен в заголовочном файле
#include <iostream>
#include <set>
int main()
{
std::set<int> numbers; // пустое множество чисел int
}
Для добавления элементов применяется функция insert():
#include <iostream>
#include <set>
int main()
{
std::set<int> numbers{3, 4, 5};
numbers.insert(1);
numbers.insert(2);
numbers.insert(2);
numbers.insert(2);
numbers.insert(6);
for (int n : numbers)
std::cout << n << "\t";
std::cout << std::endl;
}
Для удаления из множества применяется функция erase(), в которую передается удаляемый элемент:
#include <iostream>
#include <set>
int main()
{
std::set<int> numbers{2, 3, 4, 5};
numbers.erase(1);
numbers.erase(2);
numbers.erase(3);
for (int n : numbers)
std::cout << n << "\t";
std::cout << std::endl;
}
Поскольку тип std::set представляет шаблон, то в угловых скобках после названия типа указывается тип элементов, которые будет хранить множество. В данном случае множество будет хранить числа типа int.
C++ предоставляет алгоритмы стандартной библиотеки для работы с множествами: std::set_union, std::set_intersection, std::set_difference, std::set_symmetric_difference (все находятся в заголовке <algorithm>).
#include <iostream>
#include <set>
#include <algorithm> // содержит алгоритмы set_union, set_intersection и др.
#include <iterator> // нужен для inserter()
int main()
{
// Определяем два множества A и B
std::set<int> A{1, 2, 3, 4, 5};
std::set<int> B{4, 5, 6, 7, 8};
// Множество для хранения результата операций
std::set<int> result;
// ---------------- ОБЪЕДИНЕНИЕ ----------------
// std::set_union(A.begin(), A.end(), B.begin(), B.end(), inserter)
// Объединяет элементы обоих множеств без повторений
std::set_union(A.begin(), A.end(),
B.begin(), B.end(),
std::inserter(result, result.begin()));
std::cout << "Union (A ∪ B): ";
for (int n : result) std::cout << n << " ";
std::cout << std::endl;
result.clear(); // очищаем результат перед следующей операцией
// ---------------- ПЕРЕСЕЧЕНИЕ ----------------
// std::set_intersection оставляет только общие элементы двух множеств
std::set_intersection(A.begin(), A.end(),
B.begin(), B.end(),
std::inserter(result, result.begin()));
std::cout << "Intersection (A ∩ B): ";
for (int n : result) std::cout << n << " ";
std::cout << std::endl;
result.clear();
// ---------------- РАЗНОСТЬ ----------------
// std::set_difference(A, B) оставляет элементы, которые есть в A, но отсутствуют в B
std::set_difference(A.begin(), A.end(),
B.begin(), B.end(),
std::inserter(result, result.begin()));
std::cout << "Difference (A - B): ";
for (int n : result) std::cout << n << " ";
std::cout << std::endl;
result.clear();
// ---------------- СИММЕТРИЧЕСКАЯ РАЗНОСТЬ ----------------
// std::set_symmetric_difference оставляет элементы, которые входят только в одно из множеств
// (исключающее ИЛИ для множеств)
std::set_symmetric_difference(A.begin(), A.end(),
B.begin(), B.end(),
std::inserter(result, result.begin()));
std::cout << "Symmetric Difference (A Δ B): ";
for (int n : result) std::cout << n << " ";
std::cout << std::endl;
}
Множество в Python#
Множество в Python - это последовательность элементов, которые разделены между собой запятой и заключены в фигурные скобки.
users = {"Tom", "Bob", "Alice", "Tom"}
print(users) # {"Alice", "Bob", "Tom"}
Обратите внимание, что несмотря на то, что функция print вывела один раз элемент "Tom", хотя в определении множества этот элемент содержится два раза. Все потому что множество содержит только уникальные значения.
Также для определения множества может применяться функция set(), в которую передается список или кортеж элементов:
people = ["Mike", "Bill", "Ted"]
users = set(people)
print(users) # {"Mike", "Bill", "Ted"}
Python предоставляет удобные операторы и методы для выполнения стандартных операций над множествами.
A = {1, 2, 3, 4, 5}
B = {4, 5, 6, 7, 8}
# Объединение (union)
print("A ∪ B =", A | B) # {1, 2, 3, 4, 5, 6, 7, 8}
# Пересечение (intersection)
print("A ∩ B =", A & B) # {4, 5}
# Разность (difference)
print("A - B =", A - B) # {1, 2, 3}
# Симметрическая разность (symmetric difference)
print("A Δ B =", A ^ B) # {1, 2, 3, 6, 7, 8}
Массивы#
Массив — это коллекция (сбор, группа) сходных элементов (похожих, однородных, одного типа). Это основная характеристика массива: он состоит из данных одного типа (а тип задается в начале, при описании массива).
Каждому элементу в массиве присваивается положительное целое число, которое обозначает положение элемента. Это число называется индексом. В большинстве языков программирования индексы начинаются с нуля. Эта концепция называется нумерацией на основе нуля.

Массивы бывают двух видов:
● Одномерные
У каждого элемента только один индекс. Можно представить это как строку с данными, где одного номера достаточно, чтобы чётко определить положение каждой переменной.
● Многомерные
У каждого элемента два или больше индексов. По сути, это комбинация из нескольких одномерных массивов, то есть вложенная структура.

Важные свойства массива:
- Первый элемент в массиве, как правило, с индексом “0” (а не “1”).
- Если понадобился второй элемент массива, к нему обращаются по индексу “1”, и так далее.
- При создании массива задается его размер — далее не изменяемый.
Применение массивов
- Представляют собой строительные блоки более сложных структур данных, таких как стеки, очереди и т.д.
- Подходят для хранения несложных связанных данных благодаря простоте использования.
- Используются для различных алгоритмов сортировки, таких как сортировка вставок, сортировка пузырьком и т.д.
В объявлении массива C++ размер массива указывается после имени переменной, а не после имени типа, как в других языках. В следующем примере объявляется массив из 1000 двойных размеров, выделенных в стеке. Число элементов должно быть предоставлено в виде целочисленного литерала или в качестве константного выражения. Это связано с тем, что компилятор должен знать, сколько пространства стека следует выделить; он не может использовать значение, вычисляемое во время выполнения. Каждому элементу в массиве присваивается значение по умолчанию 0. Если вы не назначаете значение по умолчанию, каждый элемент изначально содержит все случайные значения в этом расположении памяти.
constexpr size_t size = 1000;
// Declare an array of doubles to be allocated on the stack
double numbers[size] {0};
// Assign a new value to the first element
numbers[0] = 1;
// Assign a value to each subsequent element
// (numbers[1] is the second element in the array.)
for (size_t i = 1; i < size; i++)
{
numbers[i] = numbers[i-1] * 1.1;
}
// Access each element
for (size_t i = 0; i < size; i++)
{
std::cout << numbers[i] << " ";
}
Первый элемент в массиве — это нулевой элемент. Последний элемент — это элемент (n-1), где n — это количество элементов, которые может содержать массив. Число элементов в объявлении должно иметь целочисленный тип и должно быть больше 0. Вы несете ответственность за то, чтобы программа никогда не передает значение оператору подстрока, который больше (size - 1).
В Python нет структуры данных, полностью соответствующей массиву!
Динамические Массивы#
В классическом массиве размер задан заранее — мы точно знаем, сколько в нём индексов. А динамический массив — это тот, у которого размер может изменяться. При его создании задаётся максимальная величина и количество заполненных элементов. При добавлении новых элементов они сначала заполняются до максимальной величины, а при превышении сразу создаётся новый массив, с большей максимальной величиной.
Элементы в динамический массив можно добавлять без ограничений и куда угодно. Однако, если добавлять их в середину, остальные придётся сдвигать, что занимает много времени. Поэтому лучше всего динамический массив работает при добавлении элементов в конце.
Как применяют динамические массивы:
- В качестве блоков для структур данных.
- Для хранения неопределённого количества элементов.
Преимущества
- Есть возможность обратиться к элементу по индексу.
- Элементы хранятся последовательно, они попадают в кэш процессора при обращении к массиву и обрабатываются быстрее.
- Массив занимает меньше памяти, так как с элементами не нужно хранить ссылки на “соседей”.
Недостатки
- Долгие процедуры вставки и удаления. Нам нужно сдвигать все последующие элементы на 1 вправо при вставке, либо влево - при удалении.
- Затратная процедура изменения размера массива.
Кроме отдельных динамических объектов в языке C++ мы можем использовать динамические массивы. Для выделения памяти под динамический массив также используется оператор new, после которого в квадратных скобках указывается, сколько массив будет содержать объектов:
int *numbers {new int[4]}; // динамический массив из 4 чисел
// или так
// int *numbers = new int[4];
Обратите внимание, что для задания размера динамического массива мы можем применять обычную переменную, а не константу, как в случае со стандартными массивами.
Для удаления динамического массива и освобождения его памяти применяется специальная форма оператора delete:
#include <iostream>
int main()
{
unsigned n{ 5 }; // размер массива
int* p{ new int[n] { 1, 2, 3, 4, 5 } };
// используем индексы
for (unsigned i{}; i < n; i++)
{
std::cout << p[i] << "\t";
}
std::cout << std::endl;
delete [] p;
}
Также мы можем создавать многомерные динамические массивы. Рассмотрим на примере двухмерных массивов. Что такое по сути двухмерный массив? Это набор массив массивов. Соответственно, чтобы создать динамический двухмерный массив, нам надо создать общий динамический массив указателей, а затем его элементы - вложенные динамические массивы. В общем случае это выглядит так:
#include <iostream>
int main()
{
unsigned rows = 3; // количество строк
unsigned columns = 2; // количество столбцов
int** numbers{new int*[rows]{}}; // выделяем память под двухмерный массив
// выделяем память для вложенных массивов
for (unsigned i{}; i < rows; i++)
{
numbers[i] = new int[columns]{};
}
// удаление массивов
for (unsigned i{}; i < rows; i++)
{
delete[] numbers[i];
}
delete[] numbers;
}
Cвязный список#
Связанный список — это набор элементов, называемых узлами, в линейной последовательной структуре. Узел — простой объект с двумя свойствами. Это переменные для хранения данных и адреса памяти следующего узла в списке. Поэтому узел знает только о том, какие данные он содержит и кто его сосед. Это позволяет создавать связанные списки, в которых каждый узел связан с другим.
Ещё одна базовая структура данных, которую, как и массивы, используют для реализации других структур. Связный список — это группа из узлов. В каждом узле содержатся:
● Данные.
● Указатель или ссылка на следующий узел.
● В некоторых списках — ещё и ссылка на предыдущий узел.
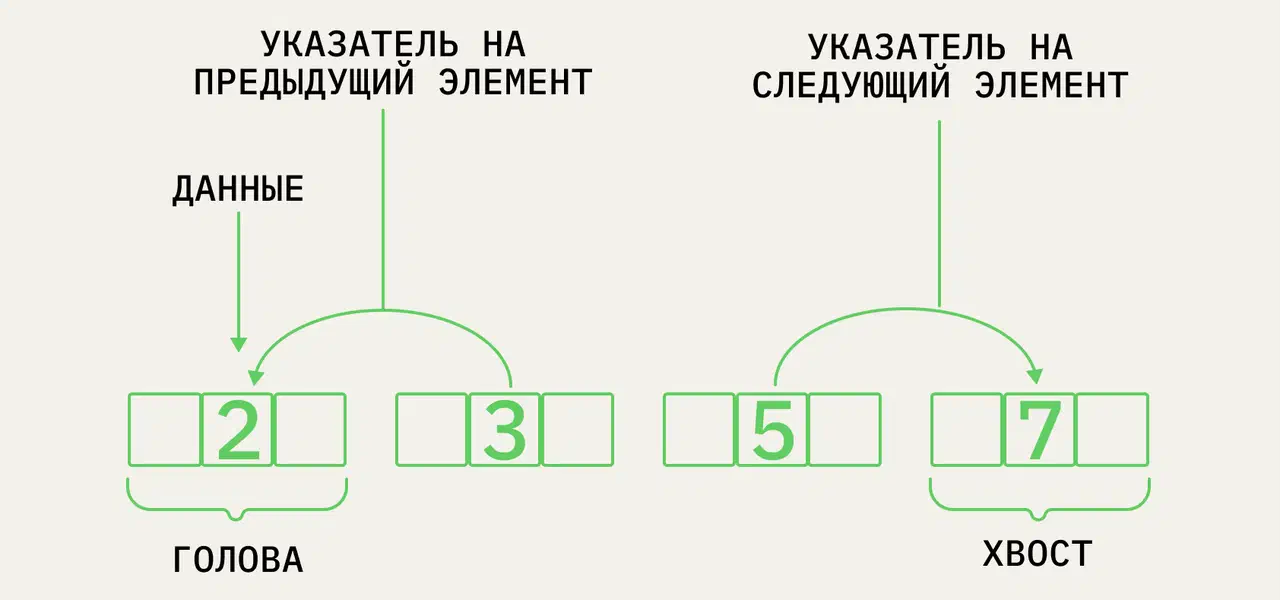
В итоге получается список, у которого есть чёткая последовательность элементов. При этом сами элементы более разрозненны, чем в массиве, поскольку хранятся отдельно. Быстро перемещаться между элементами списка помогают указатели.
Существует несколько типов списков.
- Односвязный. Обход элементов может выполняться только в прямом направлении.
- Двусвязный. Обход элементов может выполняться как в прямом, так и в обратном направлениях. Узлы включают дополнительный указатель, известный как prev, указывающий на предыдущий узел.
- Круговые связанные. Это связанные списки, в которых предыдущий (prev) указатель “головы” указывает на “хвост”, а следующий указатель “хвоста” указывает на “голову”.
Преимущества
- Очень быстрая операция вставки/удаления элемента, для вставки узла в середину нам достаточно изменить всего 2 ссылки.
- Элементы могут храниться в различных областях памяти. Список легко меняет свой размер.
- Легко выделить часть списка, просто изменив поля HEAD и TAIL.
Недостатки
- Чтобы обратиться к элементу необходимо перебрать всех его предшественников.
- Время доступа к узлам больше чем в массиве, так как они хранятся в разных областях памяти.
- Можно двигаться лишь в одном направлении.
Применение связанных списков
- В качестве строительных блоков сложных структур данных, таких как очереди, стеки и некоторые типы графиков.
- В слайд-шоу изображений, поскольку изображения идут строго друг за другом.
- В динамических структурах для выделения памяти.
- В операционных системах для легкого переключения вкладок.
Список в С++#
Для реализации списка С++ необходимо самостоятельно прописать соотвествующий класс, его методы и свойства. Ниже приведён пример реализации.
Стандартное решение добавляет один узел в начало любого списка. Эта функция называется push() так как мы добавляем ссылку в головной конец, делая список немного похожим на stack.
Мы знаем, что C++ имеет встроенный & аргумент функция для реализации эталонных параметров. Если мы добавим & к типу параметра, компилятор автоматически заставит параметр работать по ссылке, не нарушая тип аргумента.
#include <iostream>
#include <vector>
using namespace std;
// Узел связанного списка
class Node
{
public:
int key; // поле данных
Node* next; // указатель на следующий узел
};
/*
push() в C++ — мы просто добавляем `&` в правую часть заголовка
тип параметра, и компилятор заставляет этот параметр работать по ссылке.
Таким образом, этот код изменяет память вызывающей программы, но никакое дополнительное использование `*` недопустимо.
необходимо — мы обращаемся к "head" напрямую, и компилятор делает это
изменить ссылку обратно на вызывающую сторону.
*/
void push(Node* &headRef, int key)
{
// выделяем новый узел в куче и устанавливаем его данные
Node* node = new Node;
node->key = key;
// устанавливаем указатель `.next` нового узла так, чтобы он указывал на текущий
// первый узел списка.
// нет необходимости в дополнительном использовании `*` в голове — компилятор
// позаботится об этом за кулисами
node->next = headRef;
// изменяем указатель головы, чтобы он указывал на новый узел, так что
// теперь первый узел в списке.
headRef = node;
}
// Функция реализации связанного списка из заданного набора ключей
Node* constructList(vector<int> const &keys)
{
Node* head = nullptr;
// начинаем с конца массива
for (int i = keys.size() - 1; i >= 0; i--)
{
// Обратите внимание, что дополнительное использование `&` не требуется — компилятор берет
// позаботимся об этом и здесь. Эти звонки меняют голову.
push(head, keys[i]);
}
return head;
}
// Вспомогательная функция для печати связанного списка
void printList(Node* head)
{
Node* ptr = head;
while (ptr)
{
cout << ptr->key << " -> ";
ptr = ptr->next;
}
cout << "nullptr";
}
int main()
{
// клавиши ввода (в обратном порядке)
vector<int> keys = { 4, 3, 2, 1 };
// строим связанный список
Node *head = constructList(keys);
// распечатать связанный список
printList(head);
return 0;
}
Список в Python#
В Питоне, есть списки, которые являются их надмножеством, то есть это те же массивы, но с расширенным функционалом. Эти структуры удобнее в использовании, но цена такого удобства, как всегда, производительность и потребляемые ресурсы. И массив, и список – это упорядоченные коллекции, но разница между ними заключается в том, что классический массив должен содержать элементы только одного типа, а список Python может содержать любые элементы.
Для вывода каждого элемента используем его порядковый номер в списке:
Num = [9, 8, 7, 6, 5, 4, 3, 2, 1]
print(Num[0]) ##Выведет 9
print(Num[3]) ##Выведет 6
print(Num[8]) ##Выведет 1
Стек#
Стек — линейная структура данных, которая создается на основе массивов или связанных списков. Стек следует принципу Last-In-First-Out (LIFO, “первым на вход — последним на выход”), т.е. последний элемент, вошедший в стек, будет первым, кто покинет его. Причина, по которой эта структура называется стеком, в том, что ее можно визуализировать как стопку книг на столе (по-английски stack).
Саму структуру можно представить как стакан, в который кладут объекты. Ниже представлено его схематичное изображение.
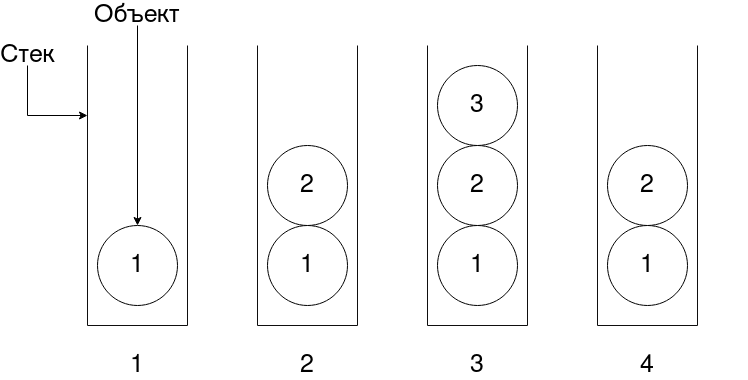
Мы можем положить элемент в стек, либо же вытащить его из стека, также, часто реализуют возможность просто посмотреть что находится наверху, без удаления объекта. На схеме 4 изображения стека, цифра на объекте означает каким по счёту элемент был добавлен в хранилище. На первых 3-х изображениях мы добавляем элементы в стек, а на последнем изображении объект вытаскивается из стека. Как видим, исчез объект, который попал в хранилище последним.
Для хранения стека можно использовать различные структуры данных, например динамический массив или связанный список.
Стек в С++#
Класс std::stack
Для работы со стеком надо подключать заголовочный файл
#include <iostream>
#include <stack>
int main()
{
std::stack<std::string> stack; // пустой стек строк
}
Для добавления в стек применяется функция push(), в которую передается добавляемый элемент:
#include <iostream>
#include <stack>
int main()
{
std::stack<std::string> stack;
// добавляем три элемента
stack.push("Tom");
stack.push("Bob");
stack.push("Sam");
std::cout << "stack size: " << stack.size() << std::endl; // stack size: 3
}
Мы можем получить только самый верхний элемент стека - для этого применяется функция top():
#include <iostream>
#include <stack>
int main()
{
std::stack<std::string> stack;
stack.push("Tom");
stack.push("Bob");
stack.push("Sam");
std::cout << "Top: " << stack.top() << std::endl; // Top: Sam
}
Для удаления элементов применяется функция pop(). Удаление производится в порядке, обратном добавлению.
Очередь#
Как и стек, очередь — это еще один тип линейной структуры данных, основанной либо на массивах, либо на связанных списках. Очереди отличаются от стеков тем, что они основаны на принципе First-In-First-Out (FIFO, “первым на вход — первым на выход”), где элемент, который входит в очередь первым, и покинет ее первым.
Реальная аналогия структуры данных “очереди” — это очередь людей, ожидающих покупки билета в кино.
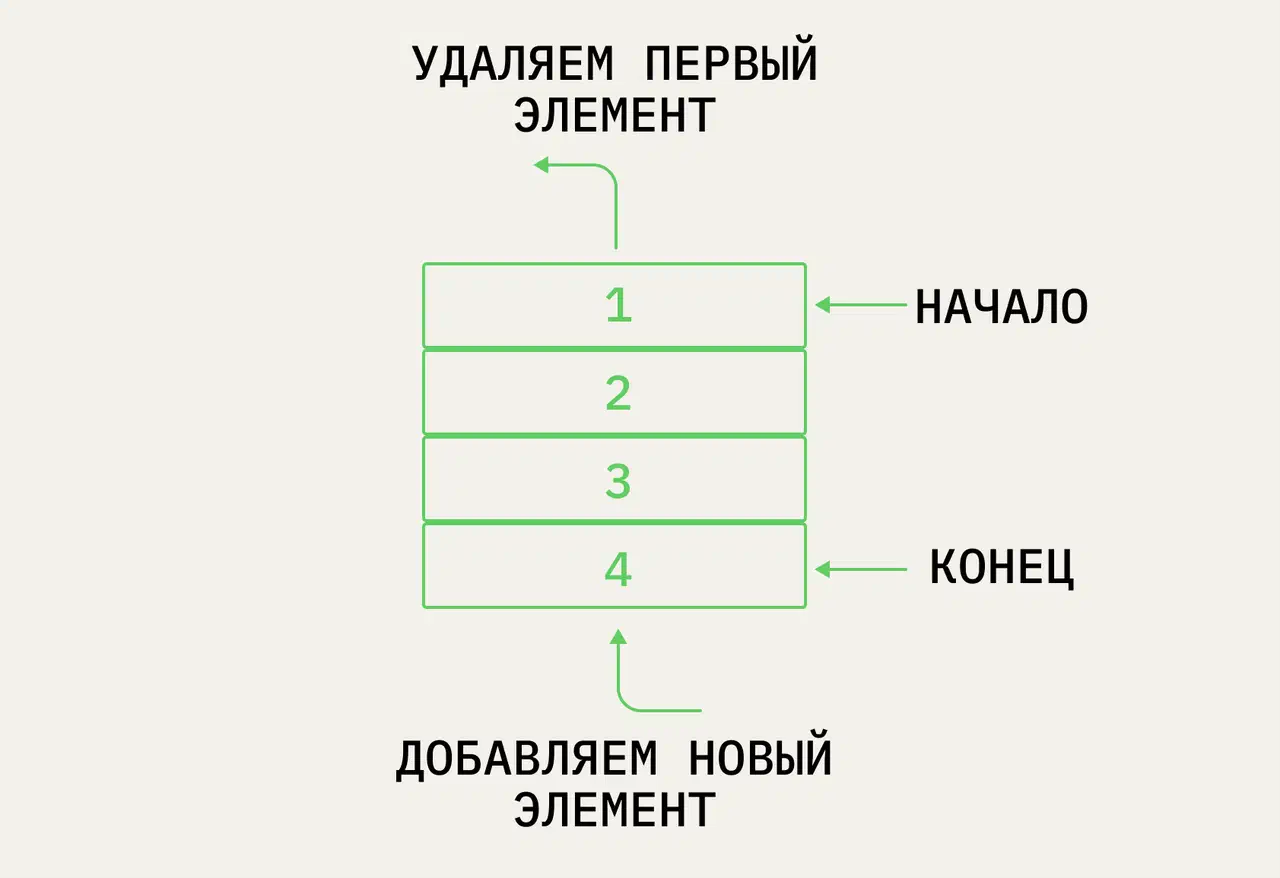
Применение очередей
- Обслуживание нескольких запросов на одном общем ресурсе.
- Управление потоками в многопоточных средах.
- Балансировка нагрузки.
Двусторонняя очередь#
Двусторонняя очередь - абстрактный тип данных, в котором элементы можно добавлять и удалять как в начало, так и в конец. В python есть реализация двусторонней очереди “deque”, которая является обобщением очереди и стека. Данная структура поддерживает эффективное извлечение элемента из любого конца за O(1). Доступ к первому и последнему элементу осуществляется также за O(1), но имеет временную сложность за O(n) для доступа к произвольному элементу.
Ниже приведена временная сложность операций для двусторонней очереди:
- Добавление нового элемента справа/слева - O(1).
- Удаление элемента справа/слева - O(1).
- Расширение на m элементов справа/слева - O(m).
- Вставка нового элемента в произвольную позицию - O(n).
- Удаление элемента с заданным значением - O(n).
Очередь в С++#
Deque представляет двухстороннюю очередь. Для использования данного контейнера нужно подключить заголовочный файл deque.
Способы создания двухсторонней очереди:
std::deque<int> deque1; // пустая очередь
std::deque<int> deque2(5); // deque2 состоит из 5 чисел, каждый элемент имеет значение по умолчанию
std::deque<int> deque(5, 2); // deque3 состоит из 5 чисел, каждое число равно 2
std::deque<int> deque4{ 1, 2, 4, 5 }; // deque4 состоит из чисел 1, 2, 4, 5
std::deque<int> deque5 = { 1, 2, 3, 5 }; // deque5 состоит из чисел 1, 2, 3, 5
std::deque<int> deque6({ 1, 2, 3, 4, 5 }); // deque6 состоит из чисел 1, 2, 3, 4, 5
std::deque<int> deque7(deque4); // deque7 - копия очереди deque4
std::deque<int> deque8 = deque7; // deque8 - копия очереди deque7
Для получения элементов очереди можно использовать операцию [] и ряд функций:
- index: получение элемента по индексу
- at(index): возращает элемент по индексу
- front(): возвращает первый элемент
- back(): возвращает последний элемент
#include <iostream>
#include <deque>
int main()
{
std::deque<int> numbers { 1, 2, 3, 4, 5 };
int first = numbers.front(); // 1
int last = numbers.back(); // 5
int second = numbers[1]; // 2
int third = numbers.at(2); // 3
std::cout << first << second << third << last << std::endl; // 1235
}
Стоит отметить, что если мы будем обращаться с помощью операции индексирования по некорректному индексу, который выходит за границы контейнера, то результат будет неопредленным.
В этом случае использование функции at() является более предпочтительным, так как при обращении по некорректному индексу она генерирует исключение out_of_range:
#include <iostream>
#include <deque>
int main()
{
std::deque<int> numbers { 1, 2, 3, 4, 5};
try
{
int n { numbers.at(7) };
std::cout << n << std::endl;
}
catch (const std::out_of_range&)
{
std::cout << "Incorrect index" << std::endl;
}
}
Очередь в Python#
# Реализация двухсторонней очереди в Python
class Deque:
def __init__(self):
self.items = []
def isEmpty(self):
return self.items == []
def addRear(self, item):
self.items.append(item)
def addFront(self, item):
self.items.insert(0, item)
def removeFront(self):
return self.items.pop()
def removeRear(self):
return self.items.pop(0)
def size(self):
return len(self.items)
d = Deque()
print(d.isEmpty())
d.addRear(8)
d.addRear(5)
d.addFront(7)
d.addFront(10)
print(d.size())
print(d.isEmpty())
d.addRear(11)
print(d.removeRear())
print(d.removeFront())
d.addFront(55)
d.addRear(45)
print(d.items)
Словарь#
Словарь (map) — это структура данных, представляющая собой специальным образом организованный набор элементов хранимых данные. Все данные хранятся в виде пар ключ-значение. Доступ к элементам данных осуществляется по ключу. Ключ всегда должен быть уникальным в пределах одного словаря, данные могут дублироваться при необходимости. У данной структуры есть и другие часто встречающиеся названия: ассоциативный массив или Dictionary. Принцип работы словаря схож с камерой хранения: есть ячейка, в которой может храниться что угодно, но доступ к этой ячейке осуществляется по уникальному номеру, благодаря чему ее всегда легко найти.
Словарь — это некий аналог адресной книги, в которой можно найти адрес или контактную информацию о человеке, зная лишь его имя; т. е. некоторые ключи (имена) связаны со значениями (информацией). Заметьте, что ключ должен быть уникальным — вы ведь не сможете получить корректную информацию, если у вас записаны два человека с полностью одинаковыми именами.
Обратите также внимание на то, что в словарях в качестве ключей могут использоваться только неизменяемые объекты (как строки), а в качестве значений можно использовать как неизменяемые, так и изменяемые объекты. Точнее говоря, в качестве ключей должны использоваться только простые объекты.
Пары ключ-значение указываются в словаре следующим образом: "d = {key1 : value1, key2 : value2 }". Обратите внимание, что ключ и значение разделяются двоеточием, а пары друг от друга отделяются запятыми, а затем всё это заключается в фигурные скобки.
Помните, что пары ключ-значение никоим образом не упорядочены в словаре. Если вам необходим некоторый порядок, вам придётся отдельно отсортировать словарь перед обращением к нему.
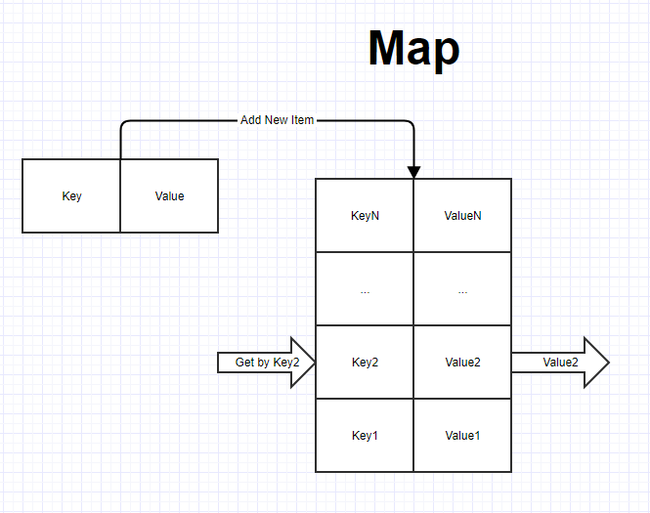
У словаря доступ осуществляется к любому из элементов хранимых данные по его ключу. Основные операции, которые могут выполняться со словарем:
- добавление нового элемента с уникальным ключом.
- удаление элемента по ключу.
- изменение хранимого значения по ключу.
- получение хранимого значения по ключу.
Словарь в С++#
Карта или std::map представляет контейнер, где каждое значение ассоциировано с определенным ключом. И по этому ключу можно получить элемент. Причем ключи могут иметь только уникальные значения. Примером такого контейнера может служить словарь, где каждому слову сопоставляется его перевод или объяснение. Поэтому такие структуры еще называют словарями.
Стандартная библиотека C++ предоставляет два типа словарей: std::map
Тип std::map определен в заголовочном файле
#include <iostream>
#include <map>
int main()
{
std::map<std::string, unsigned> products;
}
Для обращения к элементам словаря - получения или изменения их значений, так же, как в массиве или векторе, применяется оператора индексирования []. Только вместо целочисленных индексов можно использовать ключи любого типа в следующем виде:
#include <iostream>
#include <map>
int main()
{
std::map<std::string, unsigned> products;
// установка значений
products["bread"] = 30;
products["milk"] = 80;
products["apple"] = 60;
// получение значений
std::cout << "bread\t" << products["bread"] << std::endl;
std::cout << "milk\t" << products["milk"] << std::endl;
std::cout << "apple\t" << products["apple"] << std::endl;
}
Для перебора элементов можно применять цикл for в стиле "for-each":
#include <iostream>
#include <map>
int main()
{
std::map<std::string, unsigned> products;
// установка значений
products["bread"] = 30;
products["milk"] = 80;
products["apple"] = 60;
for (const auto& [product, price] : products)
std::cout << product << "\t" << price << std::endl;
}
Как было показано выше, для добавления элемента в словарь достаточно просто установить для некоторого ключа какой-нибудь значение. Для удаления же элементов применяется функция erase(), в которую передается ключ удаляемого элемента:
#include <iostream>
#include <map>
int main()
{
std::map<std::string, unsigned> products
{
{"bread", 30}, {"milk", 80}, {"apple", 60}
};
products.erase("milk"); // удаляем элемент с ключом "milk"
for (const auto& [product, price] : products)
std::cout << product << "\t" << price << std::endl;
// консольный вывод
// apple 60
// bread 30
}
Словарь в Python#
В python cловари являются экземплярами/объектами класса dict.
# 'ab' - сокращение от 'a'ddress'b'ook
ab = { 'Swaroop' : 'swaroop@swaroopch.com',
'Larry' : 'larry@wall.org',
'Matsumoto' : 'matz@ruby-lang.org',
'Spammer' : 'spammer@hotmail.com'
}
print("Адрес Swaroop'а:", ab['Swaroop'])
# Удаление пары ключ-значение
del ab['Spammer']
print('\nВ адресной книге {0} контакта\n'.format(len(ab)))
for name, address in ab.items():
print('Контакт {0} с адресом {1}'.format(name, address))
# Добавление пары ключ-значение
ab['Guido'] = 'guido@python.org'
if 'Guido' in ab:
print("\nАдрес Guido:", ab['Guido'])
Хэш-таблицы#
Хэш-таблица хранит данные в парах ключ-значение. Это означает, что каждый ключ в хэш-таблице имеет некое значение, связанное с ним. Такая простая компоновка обеспечивает эффективность хэш-таблиц, независимо от их размера, при работе с данными.
Хэш-таблицы похожи на обычное хранилище данных с парой ключ-значение, однако их отличает способ генерации ключей. Они создаются с помощью специального процесса, называемого хэшированием.
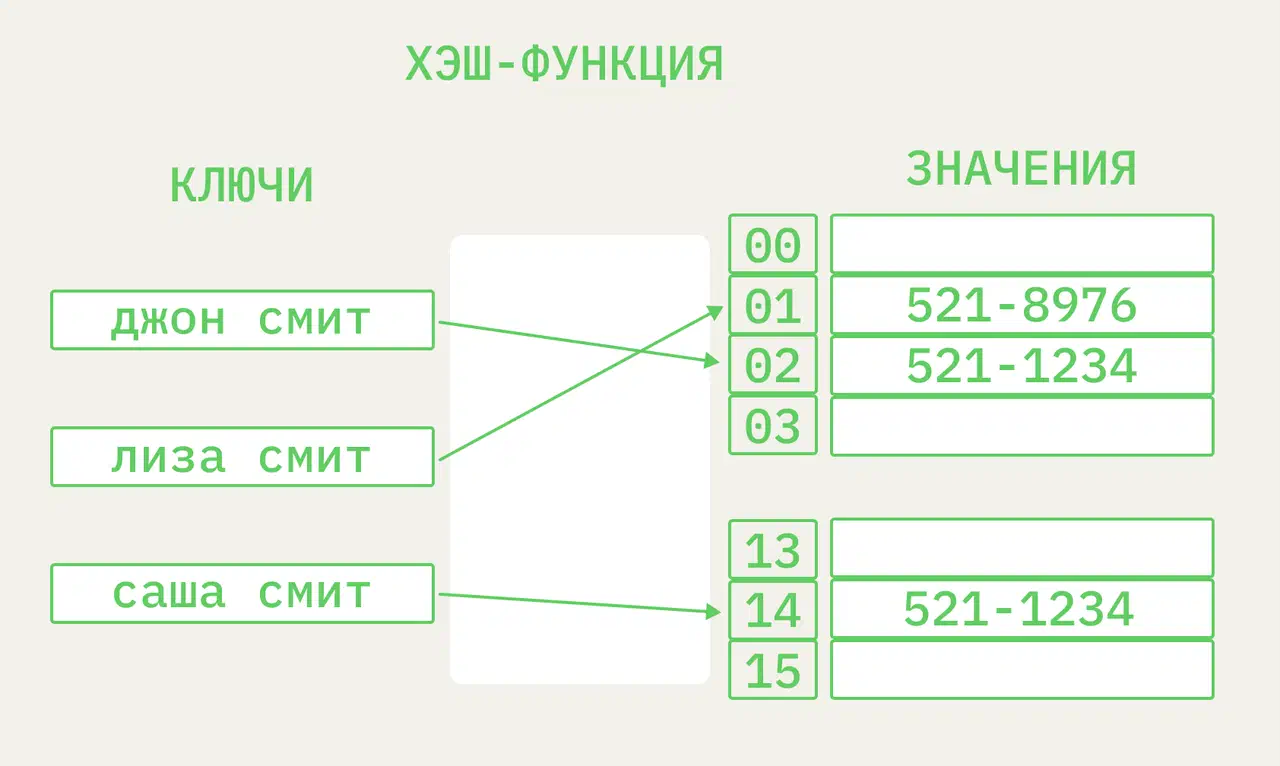
Хэширование — это процесс, который с помощью хэш-функции преобразует ключ для получения хэшированного ключа. Эта хэш-функция определяет индекс таблицы или структуры, в которых должно храниться значение.
Применение хэш -таблиц
- В индексации баз данных.
- При проверке орфографии.
- При реализации заданной структуры данных.
- В кэше.
Графы#
Граф — это структура данных, представляющая собой взаимосвязь узлов, которые также называются вершинами. Пара (x,y) называется ребром. Это указывает на то, что вершина x соединена с вершиной y. Ребро может указывать на вес/стоимость, то есть стоимость прохождения по пути между двумя вершинами.
Ключевые термины
- Размер — количество ребер в графике.
- Порядок — количество вершин в графе.
- Смежность — случай, когда два узла соединены одним и тем же ребром.
- Петля — вершина, соединенная ребром сама с собой.
- Изолированная вершина — вершина, которая не связана с другими вершинами.
Графы часто представляют в виде матрицы смежности.
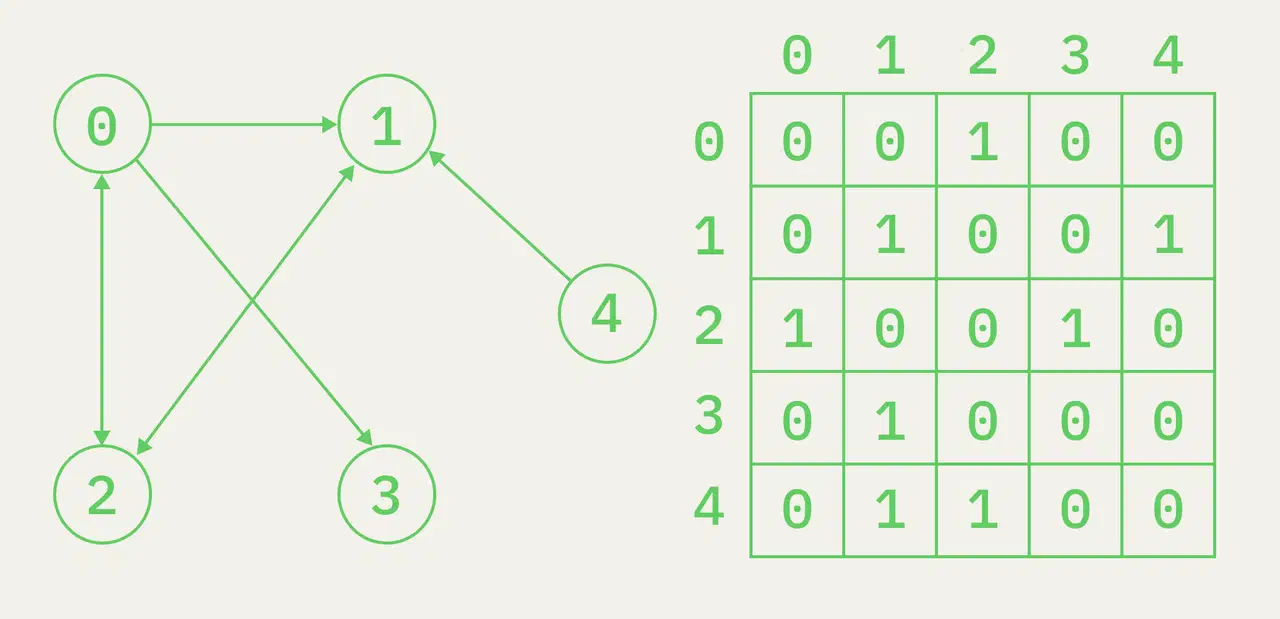
Графы делятся на два типа. Они различаются главным образом по направлениям пути между двумя вершинами.
- Ориентированные графы: все ребра имеют направления, указывающие начальную и конечную точки (вершины).
- Неориентированные графы: ребра не имеют направлений, которые позволяют обходам происходить с любого направления.
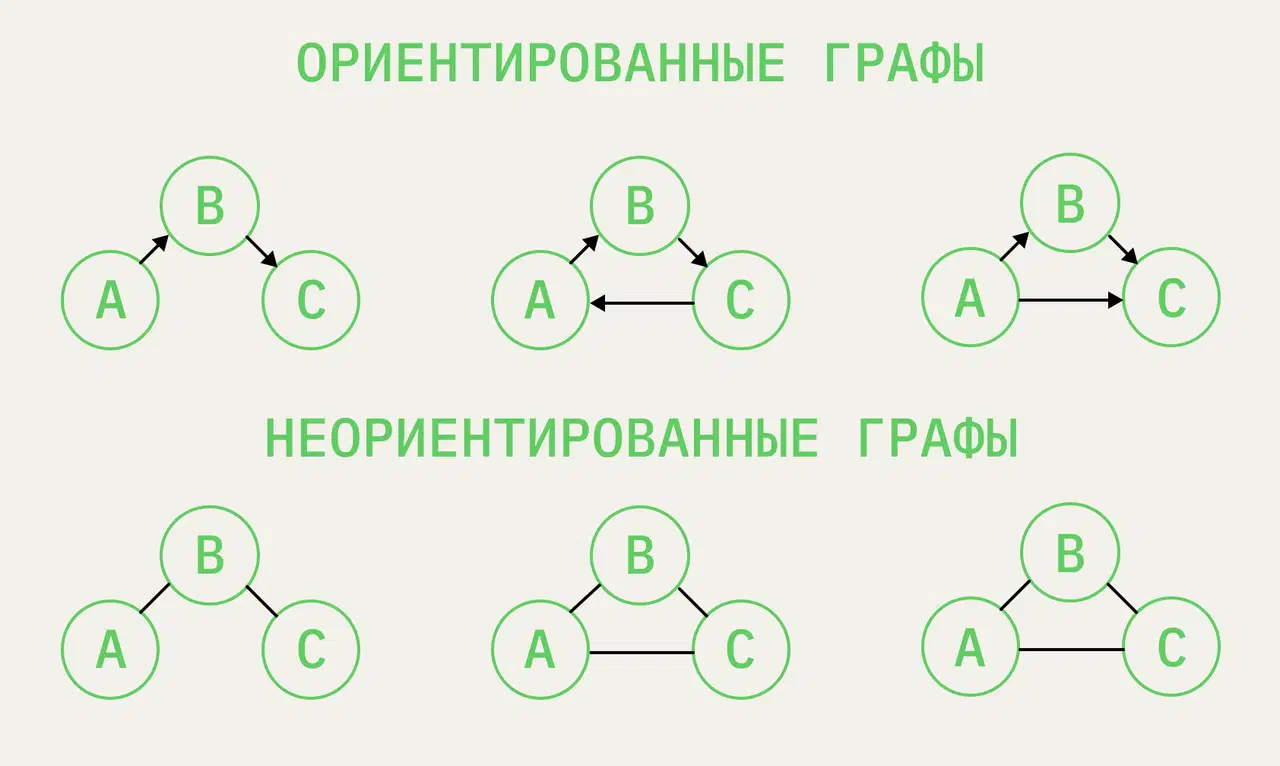
Применение графов
- Для представления потоковых вычислений.
- При распределении ресурсов операционной системой.
- Реализация алгоритмов поиска друзей в Facebook.
- Расчет кратчайшего пути между двумя локациями (Google Maps).
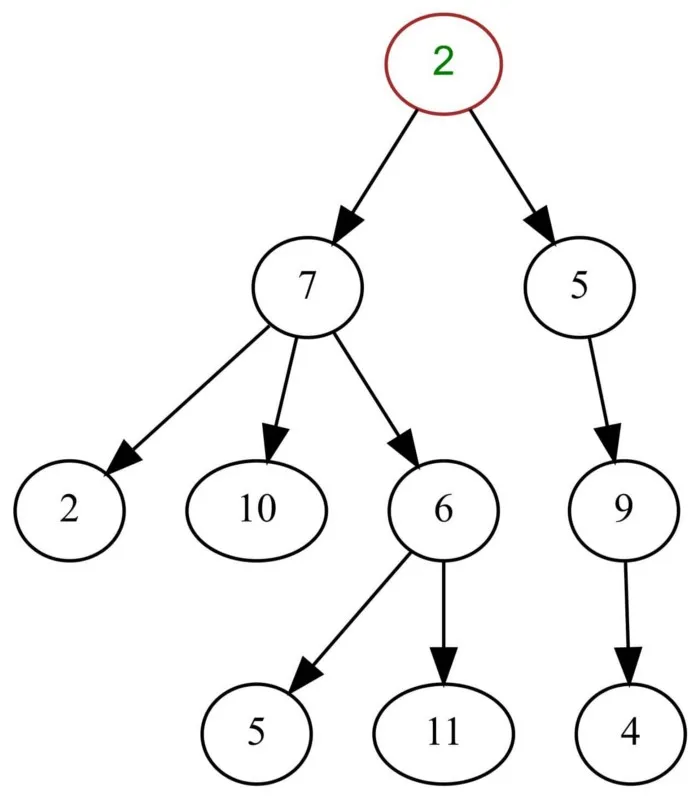
Деревья#
Дерево — это иерархическая структура данных, состоящая из вершин (узлов) и ребер, которые их соединяют. Деревья часто используются в системах искусственного интеллекта и сложных алгоритмах, поскольку обеспечивают эффективный подход к решению проблем.
Дерево — это особый тип графа, который не содержит циклов. Некоторые утверждают, что деревья полностью отличаются от графов, но эти аргументы субъективны.