Теория: Основы языка программирования С++#
Язык программирования C++ был разработан на основе языка С Бьярном Страуструпом. Авторство языка С принадлежит Денису Ритчи, сотруднику AT&T Bell Laboratories (1970). Сначала язык программирования С был написан для создания и поддержки операционной системы UNIX. До того времени все программы операционной системы UNIX были написаны либо на языке ассемблера, либо на языке В, разработанном Кеном Томпсоном – создателем системы UNIX. Язык С – это язык общего назначения, и он может быть использован для написания различных программ, но его популярность была связана в основном с операционной системой UNIX. Для поддержки системы UNIX необходимо было писать программы на языке С.
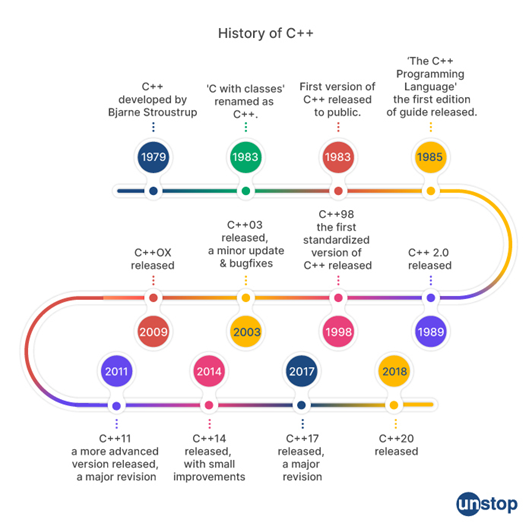
Язык С и UNIX настолько подходили друг к другу, что вскоре почти все коммерческие программы для среды UNIX оказались написанными на С. Язык С стал настолько популярным, что его специально приспособили и для других операционных систем, и его применение не ограничивалось только UNIX-системами. Несмотря на такую популярность, язык С не был лишен недостатков. Особенность языка С заключается в том, что, будучи языком высокого уровня, он сохранил многие черты языка низкого уровня. Язык С
расположен где-то между языками очень высокого уровня и языками низкого уровня, и в этом его сильные и одновременно слабые стороны.
Как и язык ассемблера (язык низкого уровня), язык программирования С может непосредственно управлять памятью компьютера. С другой стороны, С обладает чертами языков высокого уровня, поэтому программы на языке С читать и создавать легче, чем программы на языке ассемблера. Язык С является очень удобным для написания системных программ, но в программах на языке С для иных целей зачастую трудней разобраться, нежели в программах, написанных на других языках. Язык С также имеет меньше возможностей для автоматической проверки программ, чем некоторые друге языки высокого уровня.
Чтобы преодолеть эти и другие недостатки языка С, Бьярн Страуструп из AT&T Bell Laboratories в 1980 году разработал на его основе язык программирования C++. Большая часть С – это подмножество языка C++, и, таким образом, большинство С-программ являются также С++-программами. В программах на языке C++ можно использовать тексты на языке С и обращаться к библиотечным функциям языка С. Основное отличие языка C++ от С заключается в реализации объектно ориентированного подхода программирования – чрезвычайно мощного современного способа программирования.
Простейшая программа#
Простейшая программа, складывающая два числа, на C++ выглядит так:
#include <iostream>
using namespace std;
int main() {
int a, b;
cin >> a >> b;
int s = a + b;
cout << s << endl;
return 0;
}
Давайте разберем ее по строчкам.
#include <iostream>
(Здесь угловые скобки --- это просто символы «меньше» и «больше».)
Строчки, начинающиеся с символа #, в C++ называются директивами
компилятора (или более точно --- директивами препроцессора). В
отличие от практически всех других конструкций языка, они обязательно
должны быть написаны на отдельной строке.
Директива #include <iostream>, грубо говоря, подключает возможность
работы с вводом с клавиатуры и выводом на экран. В первом приближении
директива #include в C++ аналогична import в питоне и uses в
паскале --- она дает вам возможность использовать в программе какие-то
дополнительные функции и конструкции.
При этом в C++, в отличие от питона и паскаля, по умолчанию программе
доступно очень мало всего. Практически все функции, типы данных и т.д.,
за исключением очень-очень базового набора, требуют своего #include. В
частности, вот даже ввод с клавиатуры, который доступен без всяких
import\'ов в питоне и без всяких uses в паскале, в C++ требует
отдельного #include.
То, что указывается после #include, называется заголовочным файлом.
Не надо использовать термин «модуль», который используется в аналогичной
ситуации в питоне и паскале; в C++ модули --- это совсем другое (и на
самом деле доступны только начиная с C++20).
Стоит отметить, что директива компилятора
#includeимеет очень
простой смысл: она берет содержимое указанного файла (в нашем случае
iostream, который входит в стандартный комплект поставки
компилятора), и просто вставляет (include) его в то место вашей
программы, где написана директива. Т.е. запись#include <iostream>
обозначает указание компилятору «прочитай содержимое файлаiostream
так, как будто оно просто было написано в данном месте текущего файла,
после этого читай текущий файл дальше». Соответственно, в стандартном
заголовочном файлеiostreamописаны заголовки функций, типов
данных и т.д., нужных для работы с клавиатурой и экраном. Там вполне
могут быть описаны только заголовки, не полный код функций (код может
быть уже скомпилирован в готовых библиотеках), но именно заголовки
нужны компилятору, чтобы скомпилировать дальше вашу программу.
Собственно, поэтому файлы типаiostreamи называются заголовочными и
нередко имеют расширение.h(от слова header --- заголовок).На самом деле, директиву
#includeможно использовать не только для
подключения заголовочных файлов, но и в любом другом месте, где вам
надо вставить код из другого файла. Но так делать не надо за
исключением крайне редких случаев, которые вряд ли вам в ближашее
время понадобятся.Еще отмечу, что само существование директивы
#include
свидетельствует о том, что язык C++ (ну а точнее язык C, из которого
директива унаследована) --- очень древний язык программирования.
Понятно, что необходимость как-то подключать код из других файлов
возникла еще на заре языков программирования, и ясно, что конструкции,
просто тупо включающие код из другого файла в текущее место в
программе --- это один из простейших способов это сделать, и при этом
очень мощный способ. В более современных языках есть системы типа
модулей, которые, с одной стороны, сложнее (в смысле реализации в
компиляторе), но с другой стороны более аккуратные и имеют ряд
преимуществ; конструкции типа#includeв современных языках
встречаются только в каких-нибудь простых языках разметки или т.п.,
когда сам язык достаточно простой.
Переходим к следующей строке.
using namespace std;
Эта строка, как говорится, подключает namespace (пространство имён)
std. Без нее многие стандартные функции, типы, переменные и т.д. надо
было бы писать с префиксом std::, например, писать std::cin вместо
cin (cin мы увидим дальше в программе). Команда using namespace не
дает вам использовать никакие новые функции (в отличие от #include),
она просто меняет способ обращения к уже подключенным функциям.
В серьезных программах на C++ настоятельно не рекомендуется использовать
команды using namespace, но в наших небольших программах их вполне
можно использовать.
Пока вам не обязательно до конца понимать, что такое пространства имён,
пока просто запомните эту команду, ну или прочитайте следующее
примечание.
Все функции, типы, переменные и т.д. (дальше для простоты буду
говорить только про функции) в C++ распределены по пространствам
имён. Есть глобальное пространство имен, куда попадают все функции,
которые вы можете просто так объявить в программе; также когда вы
пишете новые функции, вы можете их явно заключить в какое-либо
пространство имен. Далее, если ваш код находится в каком-нибудь
пространстве имен, он может напрямую обращаться только к функциям
этого же пространства имен, а также к функциям глобального
пространства имен (а также, на самом деле, к функциям родительских
пространств имен --- потому что структура пространств имен имеет вид
дерева). Если же вам надо вызвать функцию из другого простанства имен,
вам надо перед этой функцией явно написать название пространства имен
и двойное двоеточие, например, функцияfunиз пространства имен
otherвызывается какother::fun.Это все аналогично тому, как в питоне, если вы напишете, например,
import math, то функцию квадратного корня вы не можете вызывать как
простоsqrt, а должны писатьmath.sqrt.Сделано это с очень простой целью: для любого языка программирования
есть огромное количество библиотек, и в каждой библиотеке огромное
количество функций. Конечно, в разных библиотеках могут быть функции с
одним и тем же именем, например, в библиотеке работы с файлами может
быть функцияopenдля открытия файла, и в библиотеке для работы с
сетью может быть функцияopen, например, для открытия соединения с
каким-нибудь сайтом.Соответственно, если вашей программе надо будет работать с обеими
этими библиотеками, и вы будете в коде программы вызыватьopen, то
компилятор может не понять, какая из функций вам нужна. Для решения
этой проблемы код каждой библиотеки помещают в свое пространство имен,
и тогда, явно указав пространство имен, вы можете объяснить
компилятору, какая именно функция вам нужна.В частности, почти все функции из стандартной библиотеки C++ (не из
разных дополнительных библиотек, а именно те функции, которые входят в
состав любого компилятора) находятся в пространстве именstd.
Соответственно, если вы написали#include <iostream>, то вы
подключили возможность работы с клавиатурой и экраном, но к
соответствующим функциям и переменным надо обращаться черезstd::,
например,std::cin.Конструкция же
using namespaceдает вам возможность использовать
функции из указанного пространства имен без явно указания названия
пространства имен. В частности, написавusing namespace std;, вы
можете использовать стандартные функции без префиксаstd::.В серьезных программах не рекомендуется использовать конструкцию
using namespace--- потому что она возвращает назад проблемы
одинаковых названий функций, для решения которых пространства имен как
раз и были придуманы. Но в наших небольших программах маловероятно,
что у вас будет путаница по названиям функций, поэтому обычно
using namespace std;можно писать. (Хотя бывают и проблемы;
например, насколько я помню, в некоторых компиляторах есть функция
std::y1. Если вы пишетеusing namespace std;, то вы не можете
назвать переменнуюy1. Но это вроде бы только какие-то отдельные
компиляторы, и в наших программах в таких случаях проще переименовать
переменную.)Еще стоит отметить, что в большинстве других языков (собственно, там,
где есть четкое понятие модуля), пространства имен и модули --- это
одно и то же, название модуля и пространства имен совпадает, и вы
подключаете модуль и подключаете (или не подключаете) пространство
имен одной и той же командой. Например, в питоне вы можете написать
import math, и дальше писатьmath.sqrt, или написать
from math import *и дальше писать простоsqrt; в этом смысле
import math--- это некоторый аналог#include, а
from math import *--- аналог#include, совмещенного с
using namespace. И поэтому в многих других языках программирования
отдельного понятия пространства имен просто не существует;
пространства имен --- это просто модули.А в C++ есть две независимые друг от друга концепции: пространства
имен и заголовочные файлы, и они не обязаны как-то быть связанными. В
одном заголовочном файле могут быть определены функции из разных
пространств имен (хотя так делать не принято), и наоборот, функции
одного пространства имен могут быть раскиданы по многим заголовочным
файлам, и тогда их надо подключать отдельными#include. Более того,
даже модули из C++20 не создают неявных новых пространств имен, как в
других языках --- даже в C++20 с модулями пространства имен
используются так же, как и раньше.Сам термин «пространство имён» может показаться странным, и на самом
деле это конечно калька с английского namespace, но смысл на самом
деле понятен: это некоторое «пространство», область, в котором живут
«имена» --- имена функций, переменных, типов и т.д. Соответственно,
все имена, которые есть в C++, распределены по этим пространствам,
областям, которые не пересекаются между собой. И каждое такое
пространство называется «пространство имён».
Следующая строка (дальше пойдет уже больше текста по делу и меньше
примечаний):
int main() {
Эта строка определяет функцию main, которая не принимает никаких
аргументов и возвращает значение типа int (это самый стандартный тип
данных для целых чисел). Это эквивалент записи function main:integer в
паскале, или def main(): в питоне (только в отличие от питона, на C++
надо явно указывать, какого типа будет возвращаемое значение, в нашем
случае это int).
В C++, в отличие от питона, паскаля и многих других языков, нет понятия
«основного кода программы», который пишется вне всяких функций. Любой
(ну, почти любой) исполняемый код на C++ должен быть частью какой-то
функции, и вот самый основной код программы --- должен быть написан
внутри функции со специальным названием main. Говоря по-другому, при
старте программы на C++ автоматически запускается функция с названием
main. Она должна быть в любой программе на C++, она должна быть ровно
одна, и она должна, как и написано выше, не принимать никаких параметров
(хотя на самом деле есть вариант, когда она может принимать определенные
параметры --- они используются для передачи параметров командной строки,
--- но это вам пока не будет нужно), и должна возвращать int (про это
поговорим ниже).
В целом про синтаксис функций мы тоже поговорим ниже, пока просто
запомните, что основной код программы надо начинать с такой строки.
Открывающая фигурная скобка здесь обозначает, что начался код функции.
Он будет продолжаться до парной закрывающей фигурной скобки (аналогично
begin/end в паскале; в отличие от питона, в C++ отступы не имеют
значения для компилятора).
int a, b;
Эта строка объявляет две переменные типа int, переменные будут
называться a и b. Напомню, что int --- это самый широкоупотребимый
тип данных для целых чисел, подробнее про существующие типы данных мы
поговорим ниже. Важно отметить, что при такой записи нет никакой
гарантии того, что именно будет записано в переменных a и b. В них
может оказаться какие угодно значения; в частности, вовсе не
гарантируется, что там будут записаны нули. Некоторые компиляторы
зануляют все переменные, но другие компиляторы этого не делают. На самом
деле использование непроинициализированной переменной в ряде случаев
является undefined behavior (см. ниже), т.е. программа в таком случае
может себя вести вообще как угодно. Поэтому всегда, если вам важно
инициализировать переменные --- явно указывайте, чему они должны быть
равны (про это ниже). В нашем случае это пока не важно, потому что эти
переменные мы будем вводить с клавиатуры.
cin >> a >> b;
Вводим переменные a и b с клавиатуры. Обратите внимание на довольно
необычный синтаксис. Переменная cin --- это так называемый поток ввода
с клавиатуры (от console input), два знака «больше» похожи на стрелочку,
указывающую направление движения данных: из cin в a и в b. Так
можно вводить любое количество переменных, просто дописываете далее >>
и имя переменной.
В C++ ввод с клавиатуры устроен так, что в первом приближении не важно,
разделяются числа пробелами или переводами строк. Запись как написано
выше считает число с клавиатуры, пропустив сначала лишние пробелы или
переводы строк, если они там будут, и потом считает еще одно число,
опять же пропустив пробелы и переводы строк перед ним.
Такой «потоковый» ввод, конечно, намного удобнее, чем питоновский ввод
черезinput(), где вы должны каждый раз думать, сколько чисел
вводится на какой строке. Может вызывать удивление, что в питоне нет
именно потокового ввода, --- но на самом деле это не удивительно: в
реальной жизни потоковый ввод бывает нужен крайне редко; такие
ситуации, что во входных данных у вас просто написаны числа,
разделенные пробелами или переводами строк --- это особенности
олимпиад, а в реальной жизни возникают крайне редко.
int s = a + b;
Заводим новую переменную, s, тоже типа int, и сразу в нее записываем
сумму чисел a и b. Вот так можно сразу при создании переменной
записывать в нее нужное значение. Справа от знака =, конечно, может
быть любое выражение, в том числе и просто число, если мы сразу знаем,
какое число нам нужно (т.е. можно, например, написать int cnt = 0;,
если мы хотим в переменную записать ноль).
Вообще, в C++ рекомендуется все переменные сразу при создании
инициализировать, за исключением особых случаев типа ввода с клавиатуры.
В частности, поэтому рекомендуется создавать переменные лишь в тот
момент, когда они уже вам понадобились. Люди, переходящие с паскаля,
любят объявлять все нужные переменные сразу в начале функции --- так
делать не надо. Объявляйте каждую переменную только когда она уже
понадобилась; например, здесь мы объявляем переменную s только когда
она нам уже стала нужна. Заодно часто в таких ситуациях мы сразу можем
записать осмысленное значение в переменную, а если бы объявляли бы в
начале функции, то это было бы невозможно (в нашем примере --- если бы
мы объявляли бы переменную s в начале функции, то мы не могли бы
сначала записать туда ничего осмысленного).
cout << s << endl;
Выводим ответ на экран. Здесь cout --- это переменная, отвечающая за
вывод на экран (console output), и на этот раз используются символы
«меньше», тоже явно указывая направление движения данных: из s в
cout. Далее выводим endl --- это специальная переменная, вывод
которой в cout приводит к переводу строки. (На самом деле, как я буду
писать ниже, не стоит пользоваться endl, он довольно тормозит. Но для
начала, и вообще в программах, где объем выходных данных не очень
большой, endl вполне можно писать.) (Также отмечу, что в данной
конкретной программе перевод строки особо не нужен, т.к. мы и так не
собираемся больше никаких данных выводить. Если бы нам было надо дальше
выводить что-то еще, то да, перевод строки мог бы иметь смысл, а так он
не особо нужен.)
return 0;
Как и в других языках, команда return обозначает завершить работу
функции и вернуть в место вызова указанное значение. Но тут мы находится
в главной функции, main, поэтому эта команда завершает выполнение
программы.
А ноль тут становится кодом возврата (exit code) всей программы.
Вообще, есть общепринятое соглашение во всех операционных системах, что
каждая запускаемая программа возвращает операционной системе специальное
число --- так называемый код возврата, --- который указывает, успешно
ли завершилась программа или нет, так, чтобы тот, кто запускал эту
программу (сама ОС или какие-либо еще программы) мог понять, был ли
вызов успешным. Тоже по общепринятому соглашению, код возврата, равный
нулю, обозначает, что программа успешно завершилась, ненулевой же код
обозначает, что произошла какая-то ошибка.
Например, Code::Blocks пишет код возврата --- exit code --- в окошке
программы после ее завершения. Аналогично, тестирующие системы
анализируют код возврата вашей программы и, если он не ноль, то
выставляют результат теста «ошибка времени выполнения», ну или
«ненулевой код возврата» (это одно и то же).
Вот команда return в функции main в C++ как раз и указывает, какой
код возврата должна вернуть ваша программа. Мы пишем return 0: это
обозначает, что программа успешно завершилась. Мы могли бы написать,
например, return 1, и тогда бы тот, кто запускал программу, мог бы
понять, что что-то пошло не так. В частности, если на каком-то тесте в
тестирующей системе у вас main заканчивается с return 1, то вы
скорее всего получите результат теста типа «ошибка времени выполнения»
или «ненулевой код возврата».
В других языках программирования концепция кода возврата, конечно, тоже
есть, просто в питоне и паскале, например, считается, что если
выполнение успешно дошло до конца основного кода, то код возврата будет
ноль. Но вы наверняка встречали необходимость явно указать код возврата
--- например, в конструкции sys.exit(0) ноль --- это как раз код
возврата, с которым надо завершить программу.
И как раз именно поэтому функция main должна возвращать тип int,
поэтому заголовок функции выглядит как int main() {.
На самом деле, сейчас конкретно в функции
mainможно не писать
return 0--- тогда она вернёт ноль. (Но функция все равно должна
быть определена какint, а не какvoid.) Но лучше всегда явно
писатьreturn 0, в частности, многие старые компиляторы могли
сделать какой попало код возврата, если явно не написатьreturn 0. В
остальных функциях, возвращающихint, не писатьreturnнельзя.
}
Ну и наконец последняя строка программы --- закрывающая фигурная скобка,
показывающая, что код функции main закончился. Это аналогично
паскалевскому end
Типы данных#
Все типы данных можно разделить на две категории: скалярные (простые) и составные
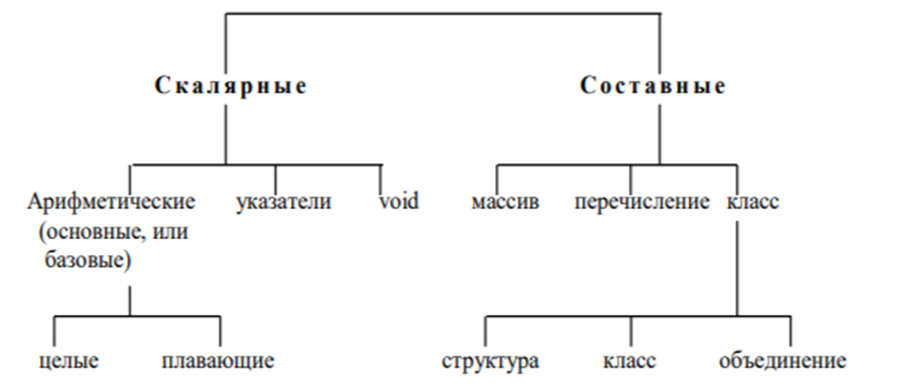
Ключевыми словами, используемыми при объявлении основных типов данных, являются
для целых типов: char, int, short, long, signed, unsigned;
для плавающих типов: float, double, long double;
для классов: structure, union, class;
для перечисления: enum;
для типа void: void (пустой).
Преобразование типов#
Неявное преобразование происходит автоматически. Это выполняется во время сравнения, присваивания или вычисления выражения различных типов.
Например, следующая программа выведет на консоль значение типа float.
При написании программы C++ важно убедиться, что она является типобезопасной.
Это означает, что каждая переменная, аргумент функции и возвращаемое значение функции хранит допустимый тип данных, и что операции со значениями разных ипов "имеют смысл" и не приводят к потере данных, неправильной интерпретации битовых шаблонов или повреждению памяти.
Сужающие преобразования#
Компилятор выполняет сужающие преобразования неявно, но предупреждает о возможной потере данных. Относимся к этим предупреждениям очень серьезно.
Когда компилятор обнаруживает небезопасное преобразование, он выдает ошибку или предупреждение. Ошибка останавливает компиляцию; предупреждение позволяет продолжить компиляцию, но указывает на возможную ошибку в коде.
Явные преобразования#
С помощью операции приведения можно указать компилятору преобразовать значение одного типа в другой тип.
Компилятор в некоторых случаях вызывает ошибку, если два типа полностью не связаны между собой, но в других случаях он не вызовет ошибку, даже если операция не является типобезопасной.
Приведения следует использовать редко, так как любое преобразование из одного типа в другой является потенциальным источником ошибки программы. Однако иногда требуются приведения, и не все приведения одинаково опасны.
static_cast— для приведения, которые проверяются только во время компиляции.
dynamic_cast— для безопасных приведения указателя к базовой точке к указателю на производный от среды выполнения.
const_cast— для отбрасывать const-ness переменной или преобразовывать переменную, не являющуюсяconst переменной, в .const
При преобразовании static_cast проверяет, что такая иерархия действительно имеет место быть (т.е. что класс B является наследником класса A), но он не проверяет, что объект, на который указывает указатель pA, действительно является объектом типа B.
dynamic_cast проверяет не только валидность иерархии классов, но и тот факт, что указатель действительно указывает на объект того типа, к которому мы хотим привести.
Вещественные числа#
апомню, что в целом современные процессоры поддерживают
три типа вещественных чисел<pythonBasicsFloatTypes>{.interpreted-text
role="ref"}:
- single --- хранит 7-8 цифр мантиссы, экспоненту до примерно ±40,
занимает в памяти 4 байта, работает сравнительно быстро; - double --- хранит 15-16 цифр мантиссы, экспонента до примерно
±300, занимает 8 байт, работает несколько медленнее; - extended --- хранит 19-20 цифр мантиссы, экспонента до примерно
±5000, занимает в памяти 10 байт, работает намного медленнее;
В C++ доступны типы single (называется float), double (так и
называется double), а также есть тип long double, который в
зависимости от компилятора может быть или double, или extended.
В большинстве наших программ стоит использовать тип double или
long double; у типа float в наших задачах обычно не хватает
точности. Обратите, в частности, внимание, что в питоне float --- это
double, а в C++ float --- это single.
Ввод-вывод также работает через cin/cout, только надо иметь в виду,
что cout по умолчанию округляет число до шести значащих цифр. Нередко
нам этого недостаточно, тогда надо просто в начале программы например,
например, cout.precision(20); --- это потребует выводить 20 значащих
цифр. Это, конечно, много и даже слишком много, но хуже не будет, и
лучше так, чем потерять точность при выводе.
Есть функции ceil, floor, trunc и round с тем же смыслом, что и
в питоне; для их использования надо подключить заголовочный файл cmath
(#include <cmath>). Для взятия модуля (abs) тоже надо подключать
cmath, иначе могут быть разные неожиданности.
Все соображения про точность работы с вещественными числами и про eps,
описанные в
соответствующем разделе текста про питон<pythonBasicsFloat>{.interpreted-text
role="ref"}, справедливы и для C++.
Целочисленные типы данных и переполнения#
В отличие от питона, в котором тип для целых чисел один и он может
хранить сколько угодно большие числа (переходя на длинную арифметику при
необходимости), в C++ есть очень много разных типов для целых чисел, и у
каждого свои границы допустимого интервала значений. При этом типы
жестко не определены; допустимый интервал у одного типа может быть
разный в разных компиляторах или даже при разных опциях одного
компилятора.
Я не буду перечислять тут все типы, их очень много, перечислю только
основные, которые вы будете использовать:
- int --- основной, наиболее широкоупотребимый тип. Хранит числа
от -2^{31} до 2^{31}-1, либо (в зависимости от компилятора и
опций) от -2^{63} до 2^{63}-1, занимает соответственно 4 или 8
байт. - unsigned int (так и пишется, с пробелом!), или сокращенно
unsigned --- беззнаковый (т.е. не хранит знак числа, а вместо
него хранит дополнительный бит значения числа) аналог int, хранит
числа от 0 до 2^{32}-1 или до 2^{64}-1, занимает соответственно
4 или 8 байт (столько же, сколько и int). - long long int, или сокращенно long long --- хранит числа от
-2^{63} до 2^{63}-1, занимает 8 байт. - unsigned long long int, или сокращенно unsigned long long
--- беззнаковый аналог long long\'а, хранит числа от 0 до
2^{64}-1, занимает 8 байт. - size_t --- это беззнаковый тип, достаточно большой настолько,
что гарантируется, что размер (в байтах) любого допустимого типа
данных (в том числе массивов) точно влезет в этот тип (это не совсем
точное определение, но близко к смыслу). То естьsize_t
гарантированно позволяет хранить количество байт, которое занимает
любая другая переменная. Как правило, это или эквивалент unsigned,
или эквивалент unsigned long long. Он часто используется в
ситуациях, когда какие-то стандартные функции возвращают размер
какого-либо объекта, количество элементов в массиве или т.п. (потому
что, в силу определения выше, этот размер точно влезет в size_t, а
вот в int, к примеру, может и не влезть). В простейших случаях вы не
будете сами этот тип использовать, но будете его встречать в
описаниях стандартных функций.
Вообще говоря, могут существовать компиляторы или опции компиляции,
при которых эти типы будут еще больше --- в смысле занимаемой памяти и
соответственно диапазона значений. Но на практике сейчас таких
компиляторов нет. Также вообще говоряintи соответственно
unsignedмогут быть и меньше, например, занимать 2 байта и иметь
соответствующий диапазон значений, но в компиляторах для полноценных
компьютеров (а не для микропроцессоров и т.п.) вы вряд ли такое
встретите. При этом, конечно, при фиксированных опциях фиксированного
компилятора размеры всех типов фиксированы, т.е. не может быть такого,
что вы объявили в программе две переменные типаint, и одна из них
получилась 4 байта, а другая 8; или что вы скомпилировали программу, у
васintполучился 4 байта, а потом, ничего не меняя,
перекомпилировали тем же компилятором с теми же опциями и получилось 8
байт.
Важной особенностью целочисленных типов в C++ (да и вообще практически в
любом другом языке, но не в питоне) являются переполнения. Если вы
попытаетесь сохранить в переменную значение за пределами допустимого
диапазона ее типа, то вместо этого сохранится какое-то другое значение,
принадлежащее допустимому диапазону. При этом в C++ не возникнет никакой
ошибки, просто молча получится неправильный ответ.
Слово «сохранить» в предыдущем абзаце относится как к ситуациям, когда
вы напрямую попробовали написать такое число (например,
int x = 12345678901234567890;), так и к ситуациям, когда вы сохраняете
результат каких-либо вычислений (int a = 1000000000; int b = a * a;),
и к ситуациям ввода данных и т.д. Попробуйте поэкспериментировать и
посмотреть, как это работает.
Поэтому всегда, когда работаете с целочисленными типами данных, помните
про опасность переполнения. Всегда оценивайте, какое максимальное
значение может получиться в той или иной переменной, и проверяйте,
влезет ли оно в тип. Если не влезает в 4-байтный int, то лучше сделайте
переменную long long (вообще говоря, никто не мешает вообще все
переменные делать long long, но тогда вы рискуете, что какие-то
большие массивы не пройдут по ограничению памяти, плюс long long тоже
может переполниться). Если вы видите, что ответ не влезает даже в
long long, то тут уже надо думать. Возможно, в конкретном компиляторе
есть 16-байтовый целочисленный тип (типа int128_t или __int128), но
это далеко не всегда так, ну и он тоже может переполниться. Или вам надо
использовать длинную арифметику. Или придумать другой алгоритм, в
котором не будут возникать такие большие числа.
Частым и очень ярким признаком переполнения знаковых типов (int и
long long) является то, что ответ, который не может быть отрицательным
(например, сумма положительных чисел), все-таки оказывается
отрицательным. Если вы такое заметили в своей программе --- точно ищите
переполнение.
Кроме того, я не рекомендую вам использовать unsigned-типы без нужды. В
них очень частая ошибка --- так называемое underflow, переполнение вниз:
например, если вы попытаетесь из 0 вычесть 1, то получится не -1 (потому
что unsigned-типы не могут хранить отрицательные числа), а очень большое
число. В частности, характерная ошибка --- вычесть единицу из длины
какого-нибудь массива или строки: поскольку эти длины обычно измеряются
в size_t, то при нулевой длине строки получится переполнение.
Правильно сначала сохранить длину в int, а потом уже вычитать 1, ну
или привести типы, см. ниже.
Что конкретно получается в результате переполнения? При переполнении
беззнаковых типов (unsigned,unsigned long long,size_tи т.п.)
просто берется остаток по модулю 2^x, где x --- количество бит в
этом типе данных (32 или 64 для типов, приведенных выше). Смысл
простой --- при любых операциях с беззнаковым типом сохраняются только
младшие x бит, а все лишние биты отбрасываются.Переполнение же для знаковых типов не определено. Это то, что
называется undefined behavior (см. ниже) --- если говорить очень
просто, то последствия переполнения знаковых типов, в т.ч.int,
могут быть абсолютно любыми, включая даже падение программы.
Еще скажу про так называемые приведения типов (от слова «приводить» ---
вы один тип приводите к другому, т.е. конвертируете в другой тип; также
говорят «кастовать» от английского cast). Вы всегда можете
сконвертировать тип значения, просто сохранив его в переменную нового
типа:
unsigned x = ....;
int y = x; // был x unsigned, а мы сохранили в int
cout << y - 1; // теперь можно вычитать 1, не боясь, что будет переполнение
Но чтобы не заводить лишних переменных, можно просто написать выражение,
которое будет иметь нужный тип. Полный вид записи в стиле C++ такой:
static_cast<int>(x), тут в угловых скобках (опять-таки, это просто
символы меньше-больше) указываете, какой тип вы хотите получить, а в
круглых скобках --- значение какой переменной хотите скастовать. Эта
запись --- это выражение, т.е. ее можно куда-нибудь сохранить или
использовать в других выражениях. Например, так:
unsigned x = ...;
cout << static_cast<int>(x) - 1; // сначала привели к int, потом вычли 1
Есть еще и запись в стиле C: (int)x, например
unsigned x = ...;
cout << (int)x - 1; // сначала привели к int, потом вычли 1
В первом приближении это то же самое, но со сложными типами лучше
использовать static_cast.
Естественно, static_cast касается не только целочисленных типов, можно
указывать разные типы, например вещественный тип:
static_cast<double>(x) (при тип double см. ниже). Строгие правила,
какие типы к какому можно приводить, довольно сложные и в целом довольно
строгие (например, сконвертировать число в строку или наоборот через
static_cast не получится), но можете поэкспериментировать.
Логический тип данных#
Логический тип данных называется bool и может принимать два значения:
true и false (с маленькой буквы). Как и в других языках, в
переменную типа bool можно записывать напрямую результаты сравнений и
других условий; и переменную типа bool можно использовать напрямую в
if\'ах, while\'ах и т.п.
В отличие от других языков,
bool--- тоже целочисленный тип. Если
вы пишете арифметическое выражение, тоfalseпревращается в0, а
true--- в1. Аналогично, логические операции на самом деле
принимают не толькоtrue/false, но и произвольные числа:0
считаетсяfalse, а все остальные значения ---true:bool x = 1 + 2; // 1 + 2 == 3, превратится в true. int y = x; // x == true, превратится в 1. int z = x + 10; // x == true, превратится в 1, 1 + 10 == 11. if (z) { // работает так же, как if (z != 0). } cout << true << '\n'; // выведет 1. cout << false << '\n'; // выведет 0. cin >> x; // ожидает на вход либо 0, либо 1, другие числа или строки нельзя.Но в целом не стоит так писать, в некоторых случаях это может
приводить к незаметным ошибкам. Пишите проверки полностью (z != 0),
как вif\'ах, так и при сохраненияхintвboolи в подобных
случаях, ну и не используйте арифметические операции сbool.
Арифметические операторы#
Сложение, вычитание и умножение делаются также, как и в других языках,
через +, - и *, тут ничего особенного. Специального оператора для
возведения в степень нет, пишите цикл :) (ну или быстрое возведение в
степень, или pow, в зависимости от ситуации).
А вот с делением есть особенности. Неполное частное берется оператором
/, остаток берется оператором %, но при этом нет прямого способа
разделить два целых числа так, чтобы получилось вещественное (т.е. в C++
/ --- это питоновский //, а аналога питоновскому / нет). Чтобы
получить вещественное деление, вам надо явно сделать так, чтобы хотя бы
одно из чисел было вещественное.
Например:
int x = 10, y = 3;
cout << x / y; // выведет 3
cout << 1.0 * x / y; // сделали числитель вещественным, выведет 3.33333
Частный, но очень важный случай --- запись 1/2 дает ноль. Чтобы
получить 0.5, надо написать, например, 1.0/2 (ну или напрямую 0.5,
конечно).
Вторая особенность деления состоит в обработке отрицательных чисел. Если
вы берете остаток от деления отрицательного числа на положительное, то
остаток будет отрицательным. Это может казаться логичным, может казаться
нелогичным (и на самом деле это нелогично), но в питоне это не так, и во
многих случаях вам будет мешать. Стандартный способ обойти эту проблему
--- написать (a%b+b)%b, т.е. после одного взятия остатка прибавить b
(чтобы получилось уж точно положительное число) и взять остаток еще раз.
Ну или написать if. Аналогично при вычислении неполного частного от
деления отрицательного числа на положительное ответ может отличаться на
1 от того, что вы ожидаете.
А если знаменатель отрицательный, то там все еще сложнее может быть.
Чуть более подробно. Определение деления с остатком очень простое:
разделить целое число A на натуральное число B --- это найти такие
два челых числа R (неполное частное) и Q (остаток), что
A = R \cdot B + Q, и дальше надо наложить какие-то еще требования на
Q (ну или R).Классическое определение далее требует, чтобы выполнялось условие
0\leq Q<B, т.е. чтобы остаток был неотрицательным и при этом меньше
B. Именно этого определения придерживается питон. Тогда, например,
получается, что(-10) // 3 = -4и(-10) % 3 == 2(потому что
-10 == 3 * (-4) + 2). Это может показаться немного странным (может
показаться, что(-10) // 3должно быть-3), но на самом деле это
логично и естественно.Но все современные процессоры думают по-другому (видимо, так
исторически сложилось, а сейчас уже менять сложившееся поведение
процессоров нереально). Если A>0, то они используют то же
определение. А вот если A<0, то они требуют, чтобы выполнялось
-B<Q\leq 0. При таком определении получается как раз
(-10) // 3 == -3и(-10) % 3 == -1. В итоге все равно
A = R \cdot B + Q, и поэтому получается, что Q в этом варианте
ровно на B меньше, чем в предыдущем (-1 вместо 2 приB==3в нашем
примере), а R на единицу больше, но это все равно зачастую неудобно.Питон делает специальную поправку на такое поведение, а C++ (и многие
другие языки) просто используют тот результат, который вернул
процессор.Это все было когда знаменатель (B) был положительным. С
отрицательным знаменателем все вообще сложнее.
Условный оператор (if) и логические операции#
Записывается так:
if (условие) {
код
} else {
код
}
Часть else, конечно, может быть опущена:
if (условие) {
код
}
Важно тут следующее. Во-первых, условие обязательно заключается в
круглые скобки. Во-вторых, сам код заключается в фигурные скобки; именно
они определяют, какой код находится внутри if\'а. Исключение --- если в
if только одна команда, то можно фигурные скобки не писать. Но это не
рекомендуется делать, за исключением ситуаций, когда команда очень
простая.
В условии, как и в питоне, можно использовать сравнения (>, >=, <,
<=, ==, !=), обратите внимание, что сравнение делается двойным
равенством (собственно, как и в питоне, и в отличие от паскаля).
Важный момент тут --- что C++ не выдает ошибку, если вы напишете
одиночное равенство, а не двойное:
if (a = b) {...}
но это уже вовсе не сравнение, это присваивание! и поэтому работает
совсем не так, как вы можете думать. Это очень частая ошибка, особенно у
тех, кто переходит с паскаля. Питон в такой ситуации выдает ошибку, а
вот C++ --- нет.
Логические операции записываются так: and --- &&, or --- ||, not ---
!. Пример:
if ((year % 400 == 0) || (year % 4 == 0 && !(year % 100 == 0)))
(конечно, можно было и просто написать year % 100 != 0).
Конструкции elif в C++ нет. Но она и не нужна --- вы прекрасно можете
просто писать else if:
if (...) {
...
} else if (...) {
...
} else if (...) {
...
} else {
...
}
На питоне вы бы не смогли так написать, потому что каждый else/if
требовал бы увеличить отступ, и получились бы отступы ступенькой. Но на
C++ строгих требований на отступы нет, поэтому вполне можно прямо так
писать.
Циклы#
Цикл while пишется так, как вы, наверное, уже ожидаете:
while (условие) {
код
}
Как и в if, тут обязательно брать условие в скобки, и тело цикла
заключается в фигурные скобки, исключение --- если тело цикла состоит из
одной команды, скобки можно не ставить (но все равно рекомендуется).
Работает цикл while так же, как и в других языках.
А вот цикл for в C++ пишется и работает довольно необычно. В
простейшем случае он пишется так:
for (int i = 0; i < n; i++) {
код
}
это эквивалент питоновского for i in range(n): --- переменная i
пробегает все значения от 0 включительно до n невключительно.
В общем виде в заголовке for есть три части, разделенные точкой с
запятой. Первая часть (int i = 0 в примере выше) --- что надо сделать
перед циклом (в данном случае --- объявить переменную i и записать
туда ноль). Вторая часть (i < n) --- условие продолжения цикла: это
условие будет проверяться перед самой первой итерацией цикла и после
каждой итерации, и как только условие станет ложным, выполнение цикла
закончится (аналогично условию while). И третья часть (i++) --- что
надо делать после каждой итерации до проверки условия.
То есть запись выше обозначает: заведи переменную i, запиши туда ноль,
дальше проверь, правда ли, что i<n и если да, то выполняй тело цикла,
потом делай i++, опять проверяй i<n, если все еще выполняется, то
опять выполняй код и делай i++, и т.д., до тех пор, пока в очередной
момент не окажется i>=n.
Примеры:
for (int i = n - 1; i >= 0; i--) // цикл в обратном порядке
for (int i = 0; i < n; i+= 2) // цикл с шагом 2
for (int i = 0; !found && i < n; i++) // цикл закончится когда found станет true, или i >= n
for (int i = 1; i < n; i *= 2) // цикл по степеням двойки
То есть на самом деле for в C++ --- очень мощный вид цикла, такой, что
даже обычный while является частный случаем for (потому что в for
можно просто опустить ненужные части заголовка: for (; условие;)
полностью эквивалентно while (условие)). Но настоятельно рекомендуется
использовать for только в тех ситуациях, когда у вас есть явная
«переменная цикла», которая как-то последовательно меняется, и тогда в
заголовке for вы упоминаете только ее. Если вам надо что-то сложнее,
пишите while.
Обратите также внимание, что переменную цикла принято объявлять прямо в
заголовке цикла. В частности, такая переменная не будет видна снаружи
цикла --- ну и правильно, если вы пишете цикл for, нечего использовать
переменную цикла после цикла. И заодно это позволяет например написать
два цикла for подряд с одной и той же переменной, причем эти
переменные не обязаны иметь одинаковый тип:
for (int i = 0; i < n; i++) {
код, тут i -- int
}
// тут переменной i нет вообще
for (unsigned int i = 1; i < m; i *= 2) {
код, тут i -- unsigned
}
Есть еще одна форма цикла for, которая появилась в C++11 --- это так
называемый range-based for. Это уже чистый аналог питоновского
for ... in, который позволяет итерироваться не по range, а по
более-менее любому объекту (массиву, строке и т.п.). На C++ это пишется
так:
for (int i : v) {
код
}
здесь предполагается, что v --- это массив int\'ов, и тогда i
последовательно принимает все значения элементов этого массива.
В частности, тут часто удобно использовать auto:
for (auto i : v) {
...
}
у переменной i получится такой же тип, как у элементов массива.
Команды break и continue есть и работают в точности так же, как в
питоне и паскале; в частности, можно писать while (true) и далее в
коде использовать break.
Кроме того, есть еще цикл do-while с проверкой условия после итерации, я
его не буду описывать (хотя там ничего сложного), он бывает довольно
редко нужен (точнее даже практически никогда, не случайно в питоне нет
его эквивалента).
Побитовые операции#
Поразрядные операции выполняются над отдельными разрядами или битами чисел. Данные операции производятся только над целыми числами. Но сначала вкратце рассмотрим, что представляют собой разряды чисел.
На уровне компьютера все данные представлены в виде набора бит. Каждый бит может иметь два значения: 1 (есть сигнал) и 0 (нет сигнала). И все данные фактически представляют набор нулей и единиц. 8 бит представляют 1 байт. Подобную систему называют двоичной.
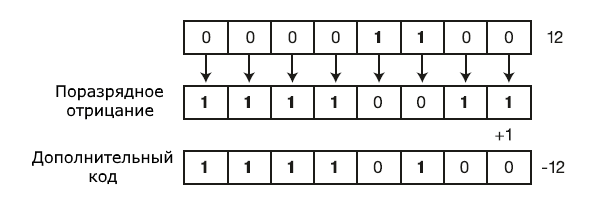
Для записи чисел со знаком в С++ применяется дополнительный код (two's complement), при котором старший разряд является знаковым. Если его значение равно 0, то число положительное, и его двоичное представление не отличается от представления беззнакового числа. Например, 0000 0001 в десятичной системе 1.
Если старший разряд равен 1, то мы имеем дело с отрицательным числом. Например, 1111 1111 в десятичной системе представляет -1. Соответственно, 1111 0011 представляет -13.
Чтобы получить из положительного числа отрицательное, его нужно инвертировать и прибавить единицу:
Операции сдвига#
Каждое целое число в памяти представлено в виде определенного количества разрядов. И операции сдвига позволяют сдвинуть битовое представление числа на несколько разрядов вправо или влево. Операции сдвига применяются только к целочисленным операндам. Есть две операции:
Сдвигает битовое представление числа, представленного первым операндом, влево на определенное количество разрядов, которое задается вторым операндом.
Сдвигает битовое представление числа вправо на определенное количество разрядов.
Поразрядные операции#
Поразрядные операции также проводятся только над соответствующими разрядами целочисленных операндов:
&: поразрядная конъюнкция (операция И или поразрядное умножение). Возвращает 1, если оба из соответствующих разрядов обоих чисел равны 1
|: поразрядная дизъюнкция (операция ИЛИ или поразрядное сложение). Возвращает 1, если хотя бы один из соответствующих разрядов обоих чисел равен 1
^: поразрядное исключающее ИЛИ. Возвращает 1, если только один из соответствующих разрядов обоих чисел равен 1
~: поразрядное отрицание или инверсия. Инвертирует все разряды операнда. Если разряд равен 1, то он становится равен 0, а если он равен 0, то он получает значение 1.
Пример практического применения операций#
Многие недооценивают поразрядные операции, не понимают, для чего они нужны. Тем не менее они могут помочь в решении ряда задач. Прежде всего они позволяют нам манипулировать данными на уровне отдельных битов. Один из примеров. У нас есть три числа, которые находятся в диапазоне от 1 до 3:
int value1 {3}; // 0b0000'0011
int value2 {2}; // 0b0000'0010
int value3 {1}; // 0b0000'0001
Мы знаем, что значения этих чисел не будут больше 3, и нам нужно эти данные максимально сжать. Мы можем три числа сохранить в одно число. И в этом нам помогут поразрядные операции.
#include <iostream>
int main()
{
int value1 {3}; // 0b0000'0011
int value2 {2}; // 0b0000'0010
int value3 {1}; // 0b0000'0001
int result {0b0000'0000};
// сохраняем в result значения из value1
result = result | value1; // 0b0000'0011
// сдвигаем разряды в result на 2 разряда влево
result = result << 2; // 0b0000'1100
// сохраняем в result значения из value2
result = result | value2; // 0b0000'1110
// сдвигаем разряды в result на 2 разряда влево
result = result << 2; // 0b0011'1000
// сохраняем в result значения из value3
result = result | value3; // 0b0011'1001
std::cout << result << std::endl; // 57
}
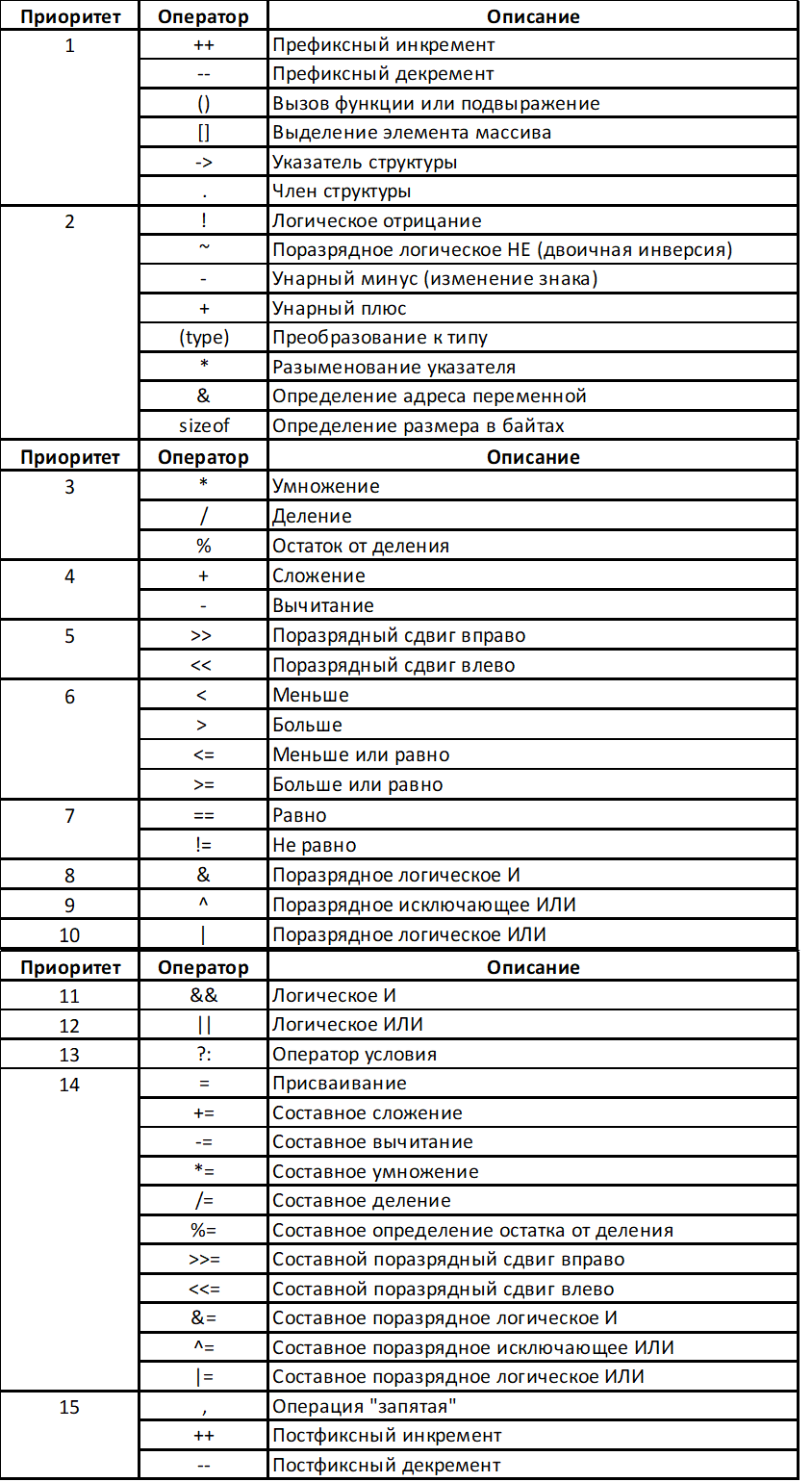
Приоритеты операторов#
Функции#
Функция в общем виде определяется так:
int foo(int x, double y, string s) {
...
}
Это определена функция foo, которая принимает три параметра: x типа
int, y типа double и s типа string, и возвращает тип int.
Если аргументов нет, то надо обязательно написать пустые скобки:
int foo() {...}. Внутри функции для завершения функции и возврата
значения используется команда return <значение>.
Любая ветка исполнения функции обязана завершаться командой
return <значение>, ее отсутствие --- это undefined behavior (см.
ниже), т.е. в случае ее отсутствия программа может вести себя вообще как
угодно. (Исключение --- функции, возвращающие void, см. ниже.)
Особый случай --- функции, не возвращающие ничего («процедуры», если
пользоваться терминами паскаля). Для таких функций надо указать
специальный тип возвращаемого значения void:
void foo() {
...
}
Соответственно, в таких функциях можно использовать только return без
значения, и в месте вызова такой функции ее результат нельзя никак
использовать. Более того, можно не писать return в конце функции.
Локальные переменные внутри функции определяются стандартным образом:
просто в коде функции объявляете переменную, когда она вам понадобилась.
Записи типа питоновской global в C++ нет; наоборот, поскольку все
локальные переменные надо явно объявлять, то если вы используете
переменную, которую не объявляли, C++ будет думать, что это глобальная
переменная (и если такой нет, то это будет ошибка компиляции).
Передача параметров в функции не так тривиальна, как в питоне.
Во-первых, параметры можно объявлять как описано выше: просто тип и имя
параметра. Тогда при вызове такой функции значения будут копироваться в
соответствующие локальные переменные, т.е. в примере выше x, y и s
будут копиями тех значений, которые были переданы в аргументы функции в
момент вызова. Изменения в x, y и s не будут видны наружу. Это
называется «передача параметров по значению».
Также возможна передача «по ссылке», она пишется так:
int foo(int& x, double& y, string& s) {
...
}
Теперь при вызове функции никаких копий переменных не делается, x, y
и s указывают на ту же переменную, ту же память, что была передана в
момент вызова функции. Т.е. если я вызываю функцию как foo(a, b, c),
то внутри функции получается что x соответствует той же переменной,
той же памяти, что и a, и изменения в x будут видны в a, и
аналогично с y и s. Естественно, это тогда требует, чтобы при вызове
функции в параметрах были указаны именно переменные, а не выражения,
запись вида foo(q + w, b, c) не сработает, потому что q+w не есть
переменная.
Передача по ссылке используется, когда вам надо реально снаружи функции
видеть изменения переменных, но это считается довольно плохой практикой
(потому что в месте вызова функции совершенно неочевидно, что переменная
будет меняться).
И есть передача «по константной ссылке»:
int foo(const int& x, const double& y, const string& s) {
...
}
Это примерно то же, что передача по ссылке, только теперь эти переменные
невозможно изменить внутри функции. За счет этого, во-первых, никакие
изменения не будут видны снаружи (просто потому, что никаких изменений
не будет вообще), во-вторых, можно в foo передавать и выражения, а не
только переменные (можно писать foo(q + w, b, c).
Передача по константной ссылке используется в первую очередь чтобы
избежать копирования значений. Скопировать int --- это недолго. А вот
скопировать string или vector может быть очень долго, если они
длинные. А если вы передаете по константной ссылке, то копирований не
будет. Например, если вы хотите передавать граф (матрицу смежности или
списки смежные вершин) в функцию типа поиска в глубину, то передавайте
по константной ссылке.
Естественно, варианты можно комбинировать как вам нужно, можно часть
параметров передавать одним способом, часть --- другим:
int foo(int x, double& y, const string& s) {
...
}
В целом, маленькие типы (в первую очередь примитивные типы данных, не
массивы, не строки и не прочие сложные типы) обычно передают по
значению, а большие --- по константной ссылке. Передача по значению
используется еще, если вам надо будет в функции все равно менять
переменную, но так, чтобы снаружи это не было заметно --- тогда без
копии, конечно, не обойтись. Передаче по не-константной ссылке
используется, если вам надо видеть изменения в переменной снаружи, и
используется довольно редко.
Файловый ввод-вывод#
Файловый ввод-вывод полностью аналогичен вводу с клавиатуры и выводу на
экран. Надо подключить заголовочный файл fstream (от file stream),
после этого создать объект типа ifstream для ввода (input file stream)
или ofstream для вывода (output file stream), указав в скобках имя
файла, и дальше работать с ними как с cin и cout:
#include <fstream>
....
ifstream in("input.txt");
int a, b;
in >> a >> b;
ofstream out("output.txt");
out << a + b;
Вам может потребоваться читать данные «до конца файла». Для этого вы
можете легко проверить, было ли чтение успешным: каждая операция чтения
возвращает некоторый объект (на самом деле тот же самый поток ввода),
который можно проверить в условии if или while. Например, так можно
считать все числа из входного файла и посчитать их сумму:
int sum = 0;
int x;
while (in >> x) { // пока чтение успешно
sum += x;
}
При этом у объектов потоков (в данном случае in) есть метод eof,
который сообщает, кончился ли уже файл, и вы можете захотеть написать
типа
// так делать не надо
while (!in.eof()) {
int x;
in >> x;
...
}
Но так не заработает. Дело в том, что файловый поток ввода узнает, что
файл кончился, только после неуспешной попытки чтения. Т.е. когда вы
прочитали последнее число, условие in.eof() будет еще ложным. Вы
попробуете считать еще одно число, чтение будет неуспешным, в x что-то
окажется (начиная с C++11 гарантируется, что там окажется ноль, но я бы
не полагался на это), и только после этого in.eof() вернет true.
Естественно, это не то, что вы хотели. Правильно проверять результат
считывания числа через while (in >> x) или т.п.
Аналогично, не надо никогда читать while (in) {...}, потому что
проверка самого потока тоже станет ложной только после неудачного
чтения.
Задания на Практике#
-
Определите, что будет выведено на экран в результате работы следующей программы.
#include <iostream>; #include <stdio.h>; using namespace std; int main() { int x = 2147483647; // Максимальное значение для знакового int int y = 1; // Увеличиваем значение на 1, чтобы вызвать переполнение int result = x + y; // Выполняем операцию сложения std::cout << "x: " << x << std::endl; std::cout << "y: " << y << std::endl; std::cout << "Result of x + y: " << result << std::endl; return 0; }
2.
#include <iostream>;
#include <stdio.h>;
using namespace std;
void main() {
int a=17;
bool f = a<18 && a>5;
if (f)
cout << (a%10 < 5 ? a/10*2 : a/5+3) << endl;
else
cout << a << endl;
getchar();
}
3. Определите, что будет выведено на экран в результате работы следующей программы. Как вы думаете, где используется данная операция?.
```cpp
#include <iostream>
int main() {
int x1 = 9; // В двоичной системе: 0000 1001
int y1 = 5; // В двоичной системе: 0000 0101
int result1 = x1 | y1; // Побитовое сложение (OR)
std::cout << "x1: " << x1 << std::endl;
std::cout << "y1: " << y1 << std::endl;
std::cout << "Result of x1 | y1: " << result1 << std::endl;
return 0;
}
```
-
Определите, что будет выведено на экран в результате работы следующей программы и объясните что произошло.
#include <iostream> #include <limits> int main() { int x1 = std::numeric_limits<int>::max(); int y1 = std::numeric_limits<int>::max(); int result1 = x1 | y1; // Побитовое сложение (OR) std::cout << "x1: " << x1 << std::endl; std::cout << "y1: " << y1 << std::endl; std::cout << "Result of x1 | y1: " << result1 << std::endl; return 0; }