Введние в БД. Часть 2.#
Базы данных представляют собой основополагающую составляющую современных информационных технологий, обеспечивающих структурирование, хранение и управление данными. Изучение и понимание основ баз данных играют важную роль не только в контексте информационных систем, но и в широком спектре приложений – от бизнеса до науки. В данном введении мы рассмотрим процесс генерации тестовых данных для проверки функциональности баз данных, а также углубимся в тему связей между таблицами, подчеркивая их важность для обеспечения целостности и эффективного управления данными. Это введение позволит нам погрузиться в основы баз данных, представляющие собой уникальное и увлекательное поле информационных технологий, где каждый аспект отражает сложность информационных систем и их важность в современном мире.
О связях между таблицами#
Связи между таблицами в базе данных представляют собой ключевой аспект для организации данных и обеспечения их целостности. Они позволяют связывать информацию из разных таблиц и обеспечивать связь между отдельными элементами данных. Один из основных типов связей - это ключи, которые устанавливают отношения между записями в различных таблицах.
Например, в базе данных авиакомпании связь между таблицами "Рейсы" и "Аэропорты" может быть установлена с помощью внешнего ключа, который связывает код аэропорта в таблице рейсов с записью об этом аэропорте в таблице аэропортов. Это позволяет получить доступ к информации о конкретных аэропортах из данных о рейсах и обеспечивает целостность данных, предотвращая например, создание рейса с несуществующим или неправильным кодом аэропорта. Правильно настроенные связи между таблицами помогают сделать базу данных эффективной, удобной для использования и поддержания, а также обеспечивают согласованность и точность данных при их изменении или обновлении.
Виды ключей#
Суперключ - это аттрибут или множество аттрибутов, единственным образом идентифицирующие кортеж.
Всё множество аттрибутов само по себе является суперключом.
Потенциальный ключ - это суперключ, который не содержит подмножество, также являющегося суперключом (суперключ минимального размера).
Потенциальный ключ может быть простым и составным.
Первичный ключ (Primary Key) - это один из потенциальных ключей, который выбран для уникальной идентификации кортежей данного отношения.
Внешний ключ (Foreign Key) - это аттрибут или множество аттрибутов, которое соответствует потенциальному ключу некоторого, может быть, того же самого отношения.
Обеспечение целостности данных.#
Обеспечение целостности данных является критически важным направлением поддержания качества данных на высоком уровне.
Question
Вспомните, почему нам так важно поддерживать уникальность ?
Виды целостности данных
-
Доменная целостность (столбец) - предусматривает определение набора значений данных, который является допустимым для этого столбца, а также возможность использовать пустые значения;
-
Объектная целостность (таблица) - для её обеспечения требуется, чтобы все строки таблицы имели уникальный код, называемый значением первичного ключа;
-
Ссылочная целостность - гарантирует сохранение связей между ключевыми полями (таблица, на которую указывают ссылки) и внешними ключами (в таблицах, которые содержат ссылки).
Типы связей#
Один к одному (One-to-One):
Каждая запись в одной таблице связана с одной и только одной записью в другой таблице.
Например, таблица "Сотрудники" может иметь отдельную связанную таблицу "Контактная информация", где каждый сотрудник имеет только одну запись с его контактной информацией.
Один ко многим (One-to-Many):
Одна запись в одной таблице связана с несколькими записями в другой таблице.
Пример: У одного автора может быть несколько книг в таблице "Авторы" и таблице "Книги" соответственно.
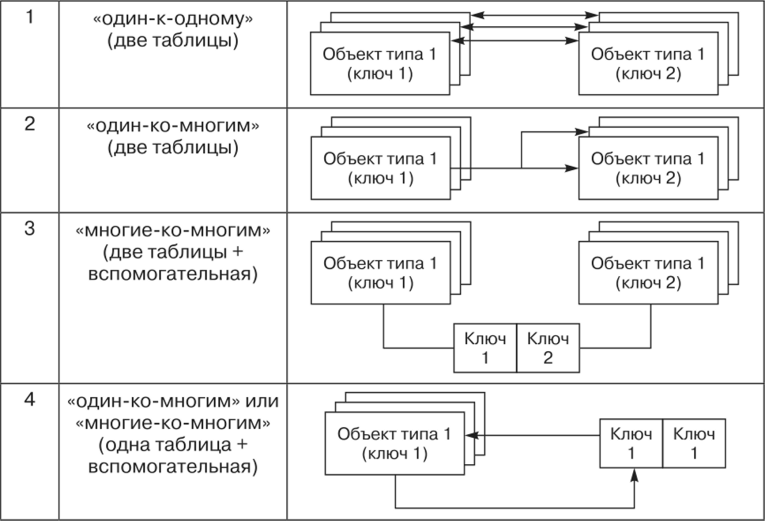
Многие к одному (Many-to-One):
Несколько записей в одной таблице связаны с одной записью в другой таблице.
Например, несколько студентов могут быть связаны с одним курсом в таблице "Студенты" и таблице "Курсы".
Многие ко многим (Many-to-Many):
Множество записей в одной таблице связано с множеством записей в другой таблице.
Это тип связи, который обычно реализуется через дополнительную таблицу-связку (join table), которая связывает две другие таблицы.
Например, студенты могут иметь множество курсов, и каждый курс может иметь множество студентов. Для этого создается таблица, которая соединяет студентов с курсами.
Нормализация#
Нормализация — это процесс организации данных в базе данных, Она включает в себя создание таблиц и установление связей между ними в соответствии с правилами, разработанными как для защиты данных, так и для повышения гибкости базы данных, устраняя избыточность и несогласованную зависимость.
Избыточность данных приводит к непродуктивному расходованию свободного места на диске и затрудняет обслуживание баз данных. Например, если данные, хранящиеся в нескольких местах, потребуется изменить, в них придется внести одни и те же изменения во всех этих местах. Изменение адреса клиента проще реализовать, если эти данные хранятся только в таблице Customers и нигде в базе данных.
Что такое «несогласованные зависимости»? Хотя пользователю интуитивно понятно искать в таблице Клиенты адрес конкретного клиента, возможно, не имеет смысла искать там зарплату сотрудника, который обращается к данному клиенту. Зарплата сотрудника связана с сотрудником (зависит от него), поэтому эти сведения следует хранить в таблице Employees (сотрудники). Несогласованные зависимости могут затруднять доступ к данным, так как путь к данным при этом может отсутствовать или быть неправильным.
Существует несколько правил нормализации баз данных. Каждое правило называется "обычной формой". Если соблюдается первое правило, база данных, как говорят, находится в "первой нормальной форме". При соблюдении первых трех правил база данных считается в "третьей нормальной форме". Хотя и другие уровни нормализации возможны, третья нормальная форма считается самым высоким уровнем, необходимым для большинства приложений.
Как и во многих формальных правилах и спецификациях, реальные сценарии не всегда позволяют обеспечить идеальное соответствие требованиям. Как правило, для выполнения нормализации приходится создавать дополнительные таблицы, и некоторые клиенты считают это нежелательным. Собираясь нарушить одно из первых трех правил нормализации, убедитесь в том, что в приложении учтены все связанные с этим проблемы, такие как избыточность данных и несогласованные зависимости.
Первая нормальная форма#
- Устраните повторяющиеся группы в отдельных таблицах.
- Создайте отдельную таблицу для каждого набора связанных данных.
- Идентифицируйте каждый набор связанных данных с помощью первичного ключа.
Не используйте несколько полей в одной таблице для хранения похожих данных. Например, для слежения за товаром, который закупается у двух разных поставщиков, можно создать запись с полями, определяющими код первого поставщика и код второго поставщика.
Что произойдет при добавлении третьего поставщика? Добавление поля не является ответом; он требует изменений в программе и таблице и не обеспечивает плавное размещение динамического числа поставщиков. Вместо этого можно поместить все сведения о поставщиках в отдельную таблицу Vendors (поставщики) и связать товары с поставщиками с помощью кодов товаров или поставщиков с товарами с помощью кодов поставщиков.
Вторая нормальная форма#
- Создайте отдельные таблицы для наборов значений, относящихся к нескольким записям.
- Свяжите эти таблицы с помощью внешнего ключа.
Записи не должны зависеть от чего-либо, кроме первичного ключа таблицы (составного ключа, если это необходимо). Возьмем для примера адрес клиента в системе бухгалтерского учета. Этот адрес необходим не только таблице Customers, но и таблицам Orders, Shipping, Invoices, Accounts Receivable и Collections. Вместо того чтобы хранить адрес клиента как отдельный элемент в каждой из этих таблиц, храните его в одном месте: или в таблице Customers, или в отдельной таблице Addresses.
Третья нормальная форма#
- Исключите поля, которые не зависят от ключа.
Значения в записи, которые не являются частью ключа этой записи, не принадлежат в таблице. Если содержимое группы полей может относиться более чем к одной записи в таблице, попробуйте поместить эти поля в отдельную таблицу.
Например, в таблицу Employee Recruitment (наем сотрудников) можно включить адрес кандидата и название университета, в котором он получил образование. Однако для организации групповой почтовой рассылки необходим полный список университетов. Если сведения об университетах будут храниться в таблице Candidates, составить список университетов при отсутствии кандидатов не получится. Таким образом, создайте вместо этого отдельную таблицу Universities и свяжите ее с таблицей Candidates при помощи ключа — кода университета.
Warning
ИСКЛЮЧЕНИЕ: Придерживаться третьей нормальной формы, хотя теоретически желательно, не всегда является практическим. Например, для устранения всех возможных зависимостей между полями таблицы Customers придется создать отдельные таблицы для хранения сведений о городах, почтовых индексах, торговых представителях, категориях клиентов и любых других сведений, которые могут дублироваться в нескольких записях. Теоретически нормализация стоит проводить. Однако значительное увеличение числа маленьких таблиц может привести к снижению производительности СУБД или исчерпанию памяти и числа дескрипторов открытых файлов.
Выполнять нормализацию до третьей нормальной формы может быть целесообразно только для часто изменяемых данных. Если при этом сохранятся зависимые поля, спроектируйте приложение так, чтобы при изменении одного из этих полей пользователь должен был проверить все связанные поля.
JOIN#
Оператор JOIN в языке SQL используется для объединения строк из двух или более таблиц на основе определенного условия. JOIN позволяет получать данные из нескольких таблиц и объединять их в один результат запроса.
Существуют различные типы JOIN:
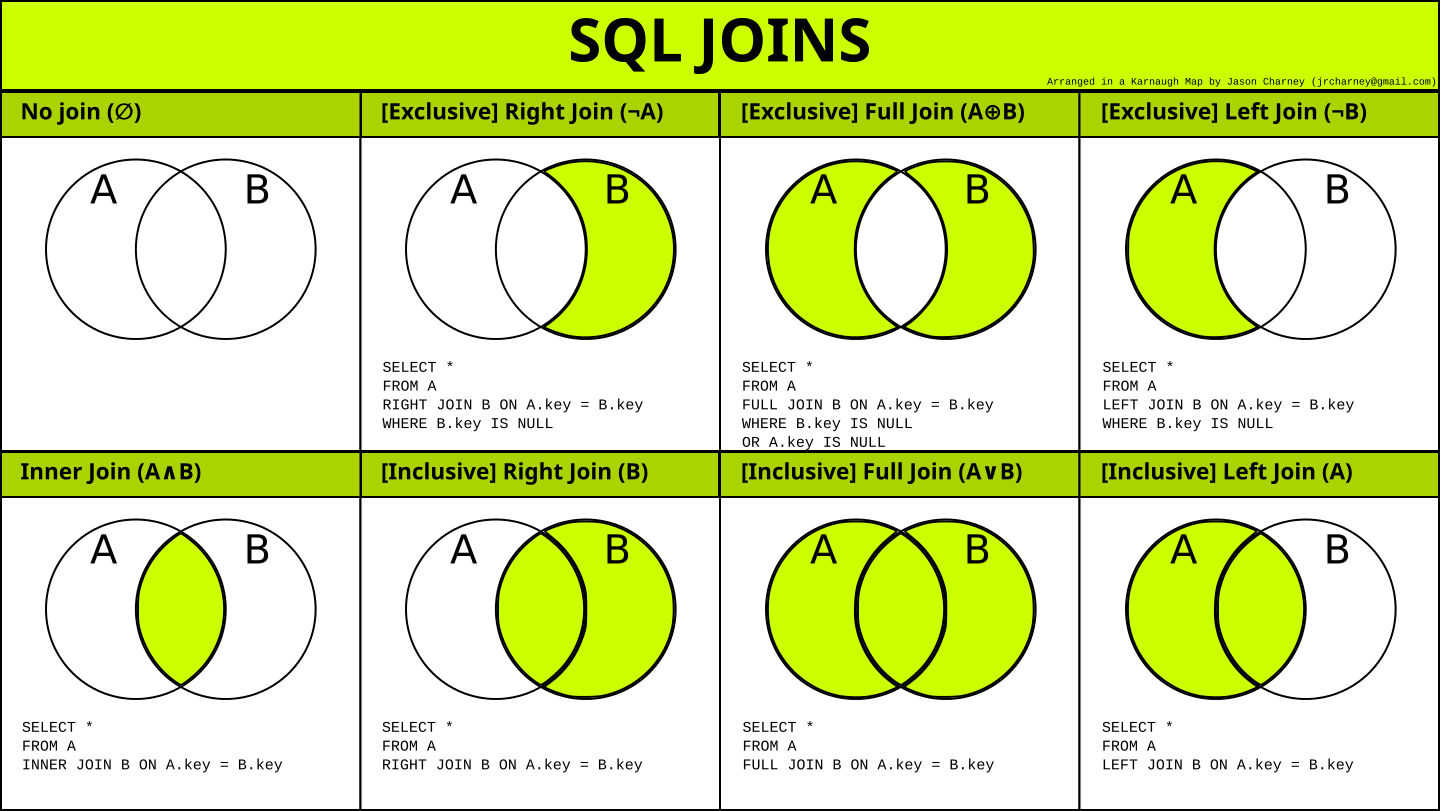
- INNER JOIN: Возвращает строки, которые имеют совпадающие значения в обеих таблицах по указанному условию.
SELECT * FROM Table1
INNER JOIN Table2 ON Table1.column = Table2.column;
- LEFT JOIN (или LEFT OUTER JOIN): Возвращает все строки из левой таблицы (первой указанной), а также совпадающие строки из правой таблицы. Если в правой таблице нет соответствующих строк, будут возвращены NULL значения.
SELECT * FROM Table1
LEFT JOIN Table2 ON Table1.column = Table2.column;
- RIGHT JOIN (или RIGHT OUTER JOIN): Возвращает все строки из правой таблицы и совпадающие строки из левой таблицы. Если в левой таблице нет соответствующих строк, будут возвращены NULL значения.
SELECT * FROM Table1
RIGHT JOIN Table2 ON Table1.column = Table2.column;
-
FULL JOIN (или FULL OUTER JOIN): Возвращает все строки из обеих таблиц. Если строки не имеют соответствия, NULL значения будут заполнены для недостающих столбцов.
SELECT * FROM Table1 FULL JOIN Table2 ON Table1.column = Table2.column; -
CROSS JOIN: Возвращает декартово произведение строк из обеих таблиц, то есть комбинирует каждую строку из первой таблицы со всеми строками из второй таблицы.
SELECT * FROM Table1 CROSS JOIN Table2;
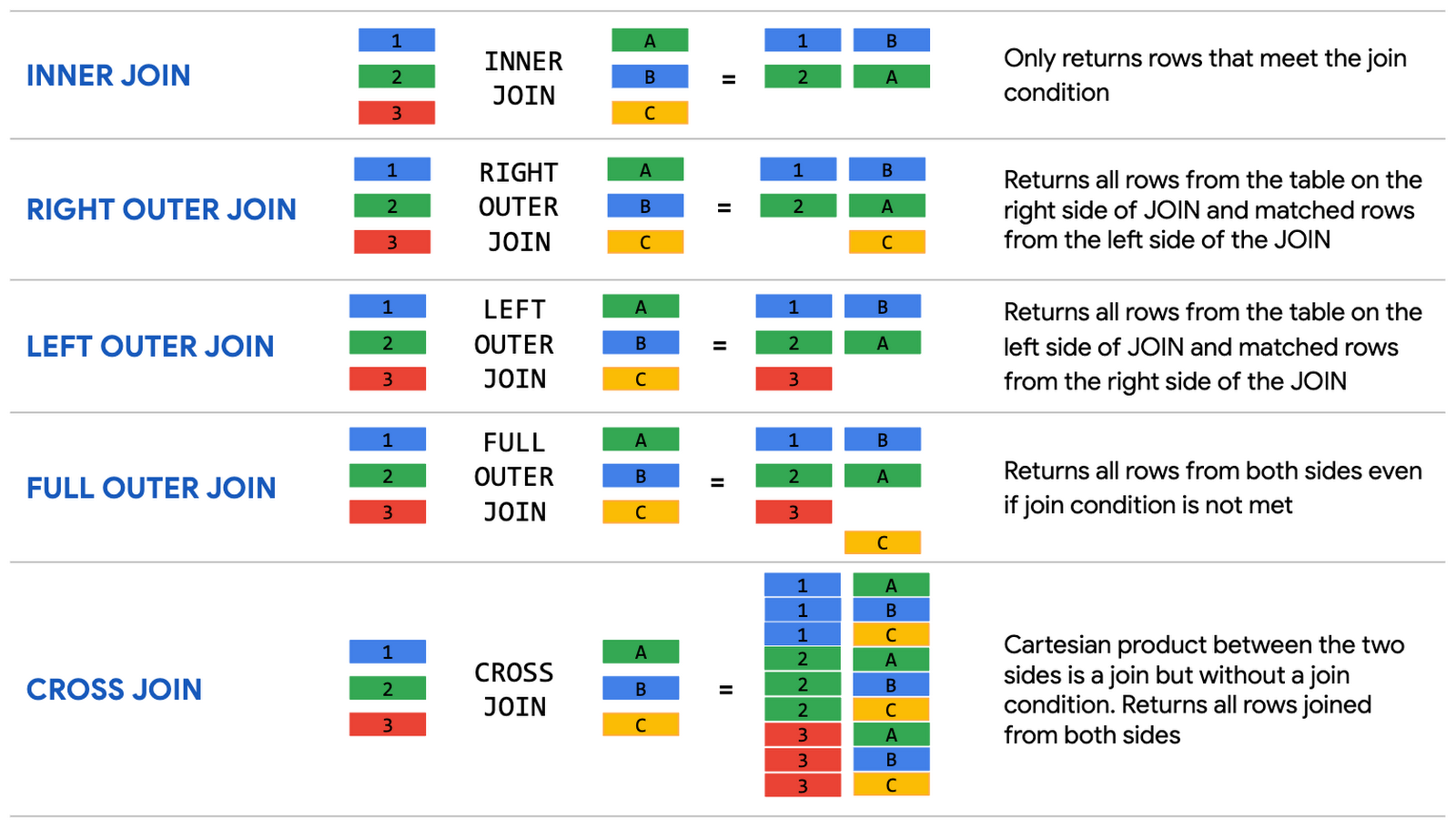
Note
В приведенном ниже примере существует две таблицы (колонки). Первая состоит из цифр, а вторая из букв. Буквы связаны с цифрами посредствам цвета. Посмотрите, как работают разнные типы операторы JOIN.
Агрегатные функции#
Агрегатная функция выполняет вычисление на наборе значений и возвращает одиночное значение. Агрегатныефункции, за исключением COUNT, не учитывают значения NULL.
Агрегатные функции часто используются в выражении GROUP BY инструкции SELECT.Агрегатные функции можно использовать в качестве выражений только в следующих случаях:
- Список выбора инструкции SELECT (вложенный или внешний запрос).
- Предложение HAVING.
С помощью SQL агрегатных функций Access можно определить различные статистические данные по наборам значений. Эти функции можно использовать в запросах и агрегатных выражениях
- Avg: Эта функция вычисляет среднее значение числовых значений в столбце или наборе значений.
- Count: Используется для подсчета количества строк или значений в столбце. Можно использовать для определения количества записей в таблице или определенного условия.
- First и Last: Эти функции возвращают первое и последнее значение в группе, соответственно. Они могут быть полезны для определения первого или последнего значения в упорядоченных данных.
- Min, Max: Они находят минимальное и максимальное значения в столбце или наборе значений. Эти функции могут быть использованы для определения наименьшего или наибольшего значения.
- StDev, StDevP: Эти функции вычисляют стандартное отклонение для выборки (StDev) и для генеральной совокупности (StDevP) числовых значений. Они позволяют оценить разброс данных относительно их среднего значения.
- Sum: Эта функция вычисляет сумму числовых значений в столбце или наборе значений.
- Var и VarP: Они используются для вычисления дисперсии для выборки (Var) и для генеральной совокупности (VarP). Эти функции позволяют оценить, насколько значения данных отклоняются от среднего значения.
Эти агрегатные функции широко используются для анализа данных в Microsoft Access, позволяя проводить статистические вычисления и получать полезную информацию о наборах данных в базе данных. Они могут быть включены в запросы SQL или использованы при создании объектов Recordset для получения нужной информации из базы данных.
Наполняемость базы данных#
Генерация тестовых данных для проверки баз данных (БД) - это процесс создания и заполнения базы данных фиктивными или случайными данными с целью проверки её производительности, стабильности и функциональности.
Вот несколько методов генерации тестовых данных:
-
Генерация случайных данных: Этот метод включает создание случайных записей для заполнения таблиц базы данных. Можно использовать скрипты или инструменты, которые создают данные определенного типа (текст, числа, даты и т.д.) и заполняют таблицы в соответствии с заданными параметрами.
-
Использование генераторов данных: Существуют инструменты и библиотеки программного обеспечения, которые специализируются на генерации тестовых данных. Они могут создавать большие объемы реалистичных данных различных типов для проверки производительности и надежности БД.
-
Импорт реальных данных: Иногда для тестирования базы данных используются реальные данные, полученные из общедоступных источников или скопированные из реальной базы данных (при условии соблюдения конфиденциальности и безопасности данных).
-
Генерация данных на основе шаблонов: Этот метод включает создание данных на основе заданных шаблонов или правил. Например, для тестирования различных кейсов использования можно генерировать данные, отражающие разные сценарии работы с базой данных.
Сервисы для генерации "реалистичных" данных#
Mockaroo — это один из лучших онлайн-инструментов для генерации большого объёма тестовых данных, основанных на заданных характеристиках. Он также позволяет генерировать более 1 000 строк тестовых данных в форматах JSON, CSV, Excel и SQL.
Особенности:
- Позволяет создавать собственные макеты API.
- Предоставляет различные типы данных, включая страну, штат или область, город, улицу, номер телефона и др.
- Позволяет контролировать URL-адреса, ответы и условия ошибок.
- Предоставляет множество библиотек имитации для любого языка и платформы.
- Помогает проводить тестирование на реалистичных данных.
GenerateData — это инструмент генерации данных с открытым исходным кодом. Он позволяет генерировать большие объёмы пользовательских данных в различных форматах для использования при тестировании ПО.
Особенности:
- Позволяет разработчикам создавать собственные типы данных для генерации случайных данных.
- Возможность добавлять новые плагины стран, которые предоставляют названия городов, регионов, а также почтовые индексы.
MOSTLY AI — Генератор синтетических тестовых данных MOSTLY AI работает на основе искусственного интеллекта. Каждый сгенерированный набор данных сопровождается отчётом о проверке качества. После загрузки примера данных генератор может создавать статистически и структурно идентичные синтетические версии оригинальных данных. Сгенерированные данные абсолютно реалистичны и конфиденциальны. Недостатком MOSTLY AI является то, что для обучения алгоритма необходим набор данных. С другой стороны, инструмент позволяет быстро генерировать репрезентативные данные для тестирования.
Особенности:
- Создаёт базы данных с сохранением ссылочной целостности.
- Полностью соответствует общему регламенту по защите данных (GDPR).
- Легко выполнить дискретизацию данных.
- Бесплатное генерирование до 100 тыс. строк в день.
- Подключение к AWS, GCP и Azure.
- Поддержка DB2, MySQL, Oracle и PostgreSQL.
Практика#
Используя сервис Mockaroo сгенерируйте тестовые данные.
После заполнения таблиц выполните следующие запросы:
-
Проверьте, что аэропорт вылета не сопадает с аэропортом прилёта
Чтобы выполнить запрос и проверить, что аэропорт вылета не совпадает с аэропортом прилёта, можно воспользоваться SQL-запросом с использованием оператора JOIN и условия WHERE, чтобы сравнить соответствующие аэропорты для каждого рейса. Предположим, что столбец DepartureAirport в таблице Flights представляет аэропорт вылета, а столбец DestinationAirport представляет аэропорт прилёта. Вот пример такого запроса:
SELECT Flights.DepartureAirport, DestinationAirports.AirportName FROM Flights INNER JOIN DestinationAirports ON Flights.DestinationAirport = DestinationAirports.AirportCode WHERE Flights.DepartureAirport = DestinationAirports.AirportName; -
Посчитать количество уникальных AirportName
SELECT COUNT(*) AS UniqueAirportCount FROM ( SELECT DISTINCT AirportName FROM DestinationAirports );
3. Сделайте свой запрос, с исползованием ключевого слово Where и Like.
Источники данных#
-
Natural Earth Data : Natural Earth предоставляет бесплатные географические данные в форме векторных и растровых наборов, охватывающих культурные, физические и географические аспекты всего мира. Эти данные доступны для использования, модификации и распространения в общественном доступе.
-
USGS Earth Explorer: USGS Earth Explorer предоставляет доступ к различным типам данных, таким как снимки Landsat, снимки MODIS, цифровые карты и другие геопространственные данные, собранные и управляемые Геологической службой США (USGS). Это полезный ресурс для исследований земной поверхности.
-
Esri Open Data Hub: Это платформа Esri, которая предоставляет доступ к открытым данным, созданным и управляемым различными источниками по всему миру. Здесь можно найти разнообразные данные ГИС, такие как карты, наборы данных о населении, экологии и многое другое.
-
NASA’s Socioeconomic Data and Applications Center (SEDAC): SEDAC предоставляет данные о социально-экономических условиях и природной среде на планете. Это включает информацию о населении, климате, здоровье, экономике и других аспектах, собранных NASA и другими организациями.
-
Sentinel Satellite Data: Sentinel - это программа космических миссий Европейского космического агентства (ESA), которая предоставляет бесплатные данные от спутников для мониторинга окружающей среды, изменений на земной поверхности и других приложений, таких как анализ изменений климата.