Ключи. Виды ключей. Нормализация данных. Индексация данных.#
Материалы к лекции#
Введение#
В реляционных базах данных ключи играют важную роль в обеспечении уникальности записей и поддержании целостности данных.
Ключ — это набор одного или нескольких полей (атрибутов), которые используются для идентификации записей в таблице.
Ключи являются одним из основных требований к модели реляционной базы данных. Они широко используются для уникальной идентификации кортежей (строк) в таблице.
Мы также используем ключи для настройки отношений между различными столбцами и таблицами реляционной базы данных.
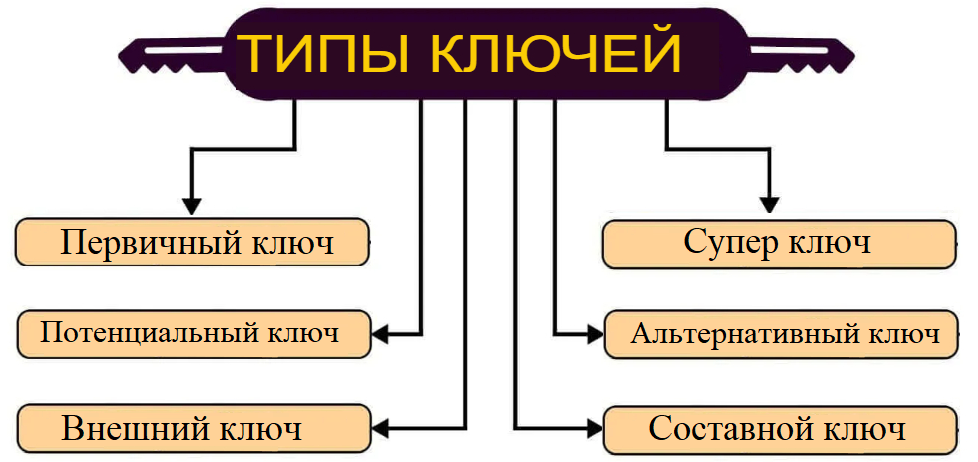
Потенциальный ключ#
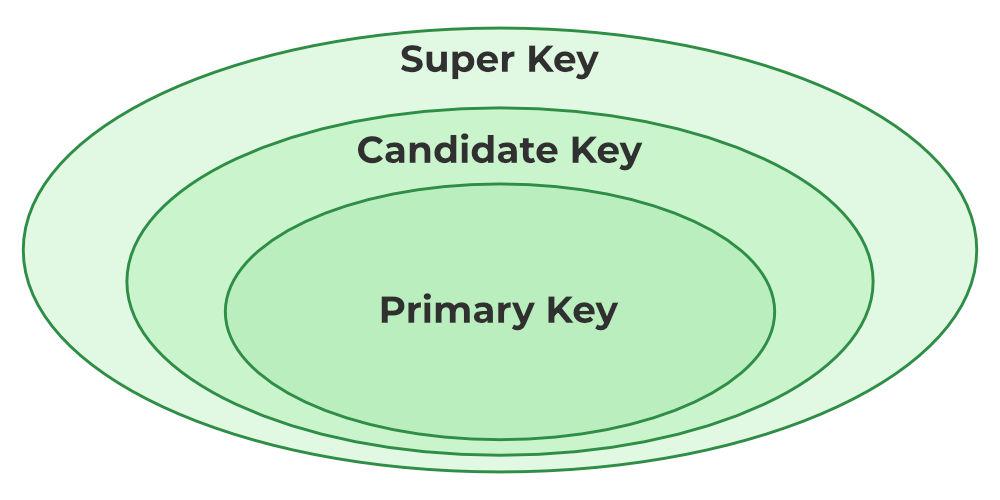
Потенциальный ключ — это минимальный набор атрибутов, который может однозначно идентифицировать кортеж.
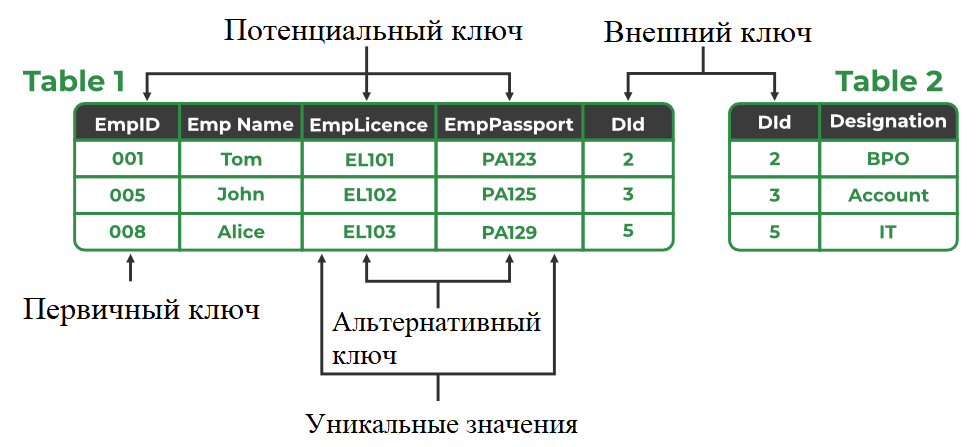
Минимальный набор атрибутов, который может однозначно идентифицировать кортеж, называется ключом-кандидатом. Например, STUD_NO в отношении STUDENT.
- Минимальный набор атрибутов, который может однозначно идентифицировать запись.
- Он должен содержать уникальные значения.
- Он может содержать НУЛЕВЫЕ значения.
- Каждая таблица должна иметь по крайней мере один потенциальный ключ.
- Таблица может содержать несколько потенциальных ключей, но только один первичный ключ.
Например, в отношении STUDENT атрибут STUD_NO является ключом-кандидатом. Ключ-кандидат должен содержать уникальные значения, но может включать нулевые значения. В каждой таблице должен быть как минимум один ключ-кандидат.
| STUD_NO | NAME | CITY | TELEPHONE |
|---|---|---|---|
| 1 | Иван | Биробиджан | +7 (8212) 28-52-68 |
| 2 | Марья | Стерлитамак | +7 (8212) 28-52-05 |
| 3 | Николай | Баклань | +7 (8212) 28-51-30 |
В данном случае, STUD_NO — это ключ-кандидат, так как он уникально идентифицирует студентов.
Потенциальный ключ может быть простым (состоящим из одного атрибута) или составным.
Составной ключ — это комбинация нескольких полей, которая используется для уникальной идентификации записей.
Например, в отношении STUDENT_COURSE, комбинация {Year_in, Faculty, Spec, Group} может служить составным ключом-кандидатом.
| STUD_NO | Year_in | Faculty | Spec | Group |
|---|---|---|---|---|
| 1 | 2022 | ГФ | АКС | 1б |
| 2 | 2024 | ФГиИБ | ИС | 2б |
Первичный ключ#
Из множества потенциальных ключей в отношении выбирается один, который становится первичным ключом. Например, STUD_NO в таблице STUDENT можно выбрать в качестве первичного ключа. Первичный ключ уникален и не может содержать нулевых значений. Он может состоять из одного или нескольких столбцов.
| STUD_NO | NAME | CITY | TELEPHONE |
|---|---|---|---|
| 1 | Иван | Биробиджан | +7 (8212) 28-52-68 |
| 2 | Марья | Стерлитамак | +7 (8212) 28-52-05 |
| 3 | Николай | Баклань | +7 (8212) 28-51-30 |
Супер-ключ#
Суперключ — это набор атрибутов, которые могут однозначно идентифицировать кортеж. Например, STUD_NO и (STUD_NO, SNAME) являются суперключами. Суперключ может включать нулевые значения. Добавление одного или нескольких атрибутов к ключу-кандидату формирует суперключ.
Суперключ отличается от потенциального ключа тем, что на суперключ не накладывается требование минимальности, или несократимости (это требование означает, что в составе ключа отсутствует меньшее подмножество атрибутов, удовлетворяющее условию уникальности). Вследствие этого в состав суперключа может входить другой, более «компактный» по количеству атрибутов суперключ.
Альтернативный ключ#
Альтернативный ключ — это ключ-кандидат, который не был выбран в качестве первичного ключа.
Все ключи, которые не являются первичными, называются альтернативными ключами. Например, NAME и CITY могут выступать в качестве альтернативных ключей.
| STUD_NO | NAME | CITY | TELEPHONE |
|---|---|---|---|
| 1 | Иван | Биробиджан | +7 (8212) 28-52-68 |
| 2 | Марья | Стерлитамак | +7 (8212) 28-52-05 |
| 3 | Николай | Баклань | +7 (8212) 28-51-30 |
Внешний ключ#
Внешний ключ — это атрибут, который может принимать только те значения, которые присутствуют в качестве значений другого атрибута. Отношение, на которое ссылаются, называется ссылочным отношением, а соответствующий атрибут — ссылочным атрибутом. Ссылочный атрибут должен быть первичным ключом в другом отношении.
| STUD_NO | NAME | CITY | TELEPHONE |
|---|---|---|---|
| 1 | Иван | Биробиджан | +7 (8212) 28-52-68 |
| 2 | Марья | Стерлитамак | +7 (8212) 28-52-05 |
| 3 | Николай | Баклань | +7 (8212) 28-51-30 |
| STUD_NO | Year_in | Faculty | Spec | Group |
|---|---|---|---|---|
| 1 | 2022 | ГФ | АКС | 1б |
| 2 | 2024 | ФГиИБ | ИС | 2б |
В данном случае атрибут STUD_NO из таблицы STUDENT_COURSE является внешним ключом по отношению к атрибуту STUD_NO из таблицы STUDENT.
Понимание ключей и их роли в реляционных базах данных является основополагающим для построения эффективных и надежных структур данных. Ключи помогают обеспечить уникальность записей, целостность данных и правильные связи между таблицами, что критично для работы с большими объемами информации.
Нормализация данных#
Нормализация базы данных (БД) - это метод проектирования реляционных БД, который помогает правильно структурировать таблицы данных. Процесс направлен на создание системы с четким представлением информации и взаимосвязей, без избыточности и потери данных.
Нормализация - это итеративный процесс. Как правило, нормализация БД выполняется через серию тестов. Каждый последующий шаг разбивает таблицу на более легкую в управлении информацию, чем повышается общая логичность системы и простота работы с ней.
Нормализация позволяет разработчику БД оптимально распределять атрибуты по таблицам. Данная методика избавляет от:
- атрибутов с несколькими значениями;
- задвоения или повторяющихся атрибутов;
- атрибутов, не поддающихся классификации;
- атрибутов с избыточной информацией;
- атрибутов, созданных из других признаков.
Необязательно выполнять полную нормализацию БД. Однако она гарантирует полноценно функционирующую информационную среду. Этот метод:
- позволяет создать структуру базы данных, подходящую для общих запросов;
- сводит к минимуму избыточность данных, что повышает эффективность использования памяти на сервере БД;
- гарантирует максимальную целостность данных, устраняя аномалий вставки, обновления и удаления.
Нормализация базы данных преобразует общую целостность данных в удобную для пользователя среду.
Избыточность баз данных и аномалии#
Когда вы вносите изменения в таблицу избыточностью, вам придется корректировать все повторяющиеся экземпляры данных и связанные с ними объекты. Если этого не сделать, то таблица станет несогласованной, и при внесении изменений возникнут аномалии.
| Employee_ID | Employee_Name | Sector | Manager |
|---|---|---|---|
| 1 | Adam | Finance | Adam |
| 2 | Jacob | Finance | Adam |
| 3 | Joshua | Finance | Adam |
| 4 | Emily | Marketing | Emily |
Для таблицы характерна избыточность данных, а при изменении этих данных возникают 3 аномалии:
- Аномалия вставки. При добавлении нового «Сотрудника» (employee) в «Отдел» (sector) Finance, обязательно указывается его «Руководитель» (manager). Иначе вы не сможете вставить данные в таблицу.
При добавлении нового сотрудника в отдел Finance, требуется указать его руководителя, даже если сотрудник новый и информация о руководителе уже есть. Например, при добавлении нового сотрудника без указания менеджера будет возникать ошибка.
| Employee_ID | Employee_Name | Sector | Manager |
|---|---|---|---|
| 1 | Adam | Finance | Adam |
| 2 | Jacob | Finance | Adam |
| 3 | Joshua | Finance | Adam |
| 4 | Emily | Marketing | Emily |
| 5 | New_Employee | Finance | (ошибка — не указан менеджер) |
- Аномалия обновления. Когда сотрудник переходит в другой отдел, поле «Руководитель» содержит ошибочные данные. К примеру, Джейкоб (Jacob) перешел в отдел Finance, но его руководителем по-прежнему показывается Адам (Adam).
| Employee_ID | Employee_Name | Sector | Manager |
|---|---|---|---|
| 1 | Adam | Finance | Adam |
| 2 | Jacob | Marketing | Adam (ошибка) |
| 3 | Joshua | Finance | Adam |
| 4 | Emily | Marketing | Emily |
- Аномалия удаления. Если Джошуа (Joshua) решит уволиться из компании, то при удалении строки с его записью потеряется информация о том, что отдел Finance вообще существует.
| Employee_ID | Employee_Name | Sector | Manager |
|---|---|---|---|
| 1 | Adam | Finance | Adam |
| 2 | Jacob | Finance | Adam |
| 4 | Emily | Marketing | Emily |
| 3 (удален) | Joshua (удален) | Finance | (удален) |
Основные понятия в нормализации базы данных#
Простейшие понятия, используемые в нормализации базы данных:
ключи - атрибуты столбцов, которые однозначно (уникально) определяют запись в БД;
функциональные зависимости - ограничения между двумя взаимосвязанными атрибутами;
нормальные формы - этапы для достижения определенного качества БД.
Нормализация базы данных выполняется с помощью набора правил. Такие правила называются нормальными формами. Основная цель данных правил - помочь разработчику БД в достижении нужного качества реляционной базы.
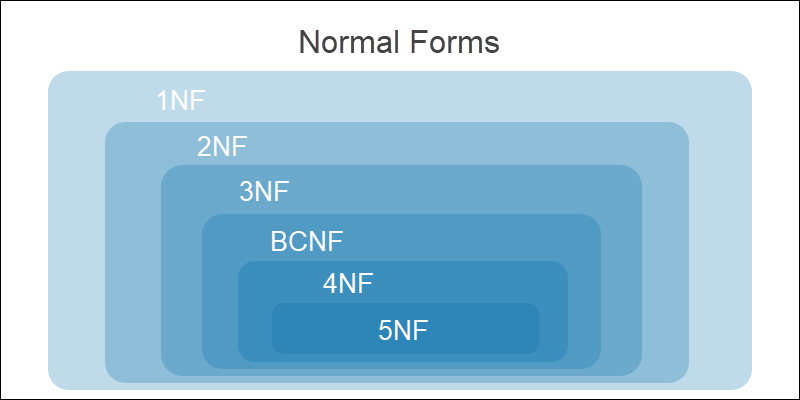
Все уровни нормализации считаются кумулятивными, или накопительными. Прежде чем перейти к следующему этапу, выполняются все требования к текущей форме.
| Стадия | Аномалии избыточности |
|---|---|
| Ненормализованная (нулевая) форма (UNF) | Это состояние перед любой нормализацией. В таблице присутствуют избыточные и сложные значения |
| Первая нормальная форма (1NF) | Разбиваются повторяющиеся и сложные значения; все экземпляры становятся атомарными |
| Вторая нормальная форма (2NF) | Частичные зависимости разделяются на новые таблицы. Все строки функционально зависимы от первичного ключа |
| Третья нормальная форма (3NF) | Транзитивные зависимости разбиваются на новые таблицы. Не ключевые атрибуты зависят от первичного ключа |
| Нормальная форма Бойса-Кода (BCNF) | Транзитивные и частичные функциональные зависимости для всех потенциальных ключей разбиваются на новые таблицы |
| Четвертая нормальная форма (4NF) | Удаляются многозначные зависимости |
| Пятая нормальная форма (5NF) | Удаляются JOIN-зависимости (зависимости соединения) |
База данных считается нормализованной после достижения третьей нормальной формы. Дальнейшие этапы нормализации усложняю структуру БД и могут нарушить функционал системы.
Примеры нормализации базы данных.#
Общие этапы в нормализации базы данных подходят для всех таблиц. Конкретные методы разделения таблицы, а также вариант прохождения или не прохождения через третью нормальную форму (3NF) зависят от примеров использования.
В одном столбце ненормализованной таблицы содержится несколько значений. В худшем случае в ней присутствует избыточная информация.
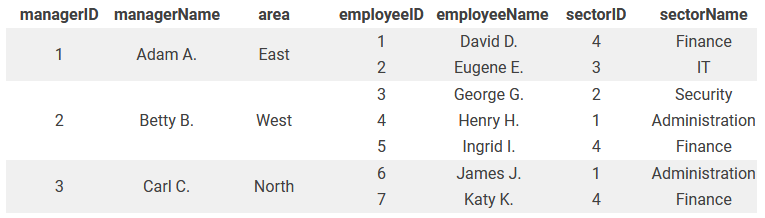
Шаг 1: Первая нормальная форма (1NF)#
Для преобразования таблицы в первую нормальную форму значения полей должны быть атомарными. Все сложные сущности таблицы разделяются на новые строки или столбцы.
Чтобы не потерять информацию, для каждого сотрудника дублируются значения столбцов managerID, managerName и area.
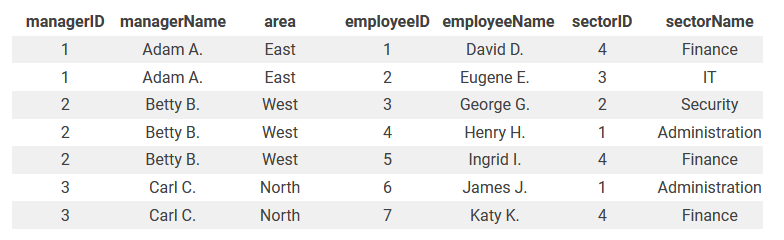
Шаг 2: Вторая нормальная форма (2NF)#
Во второй нормальной форме каждая строка таблицы должна зависеть от первичного ключа.
Чтобы таблица соответствовала критериям этой формы, ее необходимо разделить на 2 части:
Manager (managerID, managerName, area)

Employee (employeeID, employeeName, managerID, sectorID, sectorName)
Итоговая таблица во второй нормальной форме представляет собой 2 таблицы без частичных зависимостей.
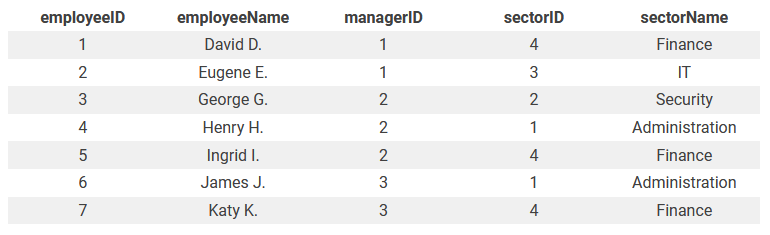
Шаг 3: третья нормальная форма (3NF)#
Tip
транзитивная зависимость - функциональная зависимость между тремя атрибутами: второй атрибут зависит от первого, а третий - от второго. Благодаря транзитивности, третий атрибут зависит от первого;
Третья нормальная форма разделяет любые транзитивные функциональные зависимости. В нашем примере транзитивная зависимость есть у таблицы Employee; она разбивается на 2 новых таблицы:
Employee (employeeID, employeeName, managerID, sectorID)
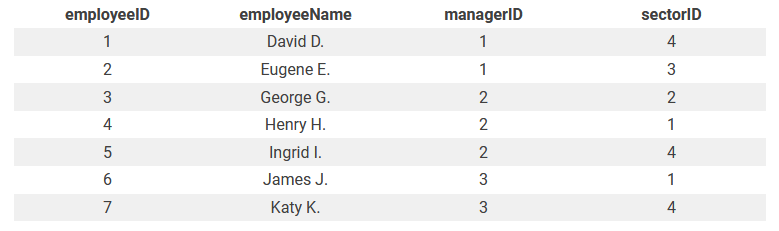
Sector (sectorID, sectorName)

Теперь таблица соответствует третьей нормальной форме с тремя взаимосвязями. Конечная структура выглядит так:

Теперь база данных считается нормализованной. Дальнейшая нормализация зависит от ваших конкретных целей.
Индексация#
Индексирование баз данных — это техника, повышающая скорость и эффективность запросов к базе данных. Она создаёт отдельную структуру данных, сопоставляющую значения в одном или нескольких столбцах таблицы с соответствующими местоположениями на физическом накопителе, что позволяет базе данных быстро находить строки по конкретному запросу без необходимости сканирования всей таблицы. Применяются разные типы индексов, однако они занимают пространство и должны обновляться при изменении данных. Важно тщательно продумывать стратегию индексирования базы данных и регулярно её оптимизировать.
Индексирование базы данных обычно выполняется при помощи алгоритма, определяющего, как должен создаваться и храниться индекс. Конкретный процесс создания индекса может варьироваться в зависимости от типа используемой системы базы данных, однако в целом общие этапы выглядят так:
- Определение столбца или столбцов в таблице базы данных, которые нужно индексировать. Обычно они определяются по тому, какие столбцы чаще всего используются в запросах или поисках.
- Выбор алгоритма индексирования, подходящего для типа индексируемых данных. Например, индексы в виде B-деревьев обычно используются для индексирования строковых или числовых данных, а полнотекстовые индексы — для индексирования текстовых данных.
- Применение алгоритма индексирования к выбранным столбцам, что создаёт структуру данных, сопоставляющую значения в столбцах с местоположениями соответствующих записей таблицы.
- Сохранение индекса в отдельной структуре данных, обычно в другой части диска или в памяти, чтобы доступ к ней был более эффективным, чем к соответствующим табличным данным.
- Обновление индекса в случае добавления новых записей, удаления или изменения записей в таблице.
Создание индекса может существенно улучшить производительность запросов к базе данных и операций поиска, поскольку оно позволяет системе базы данных находить соответствующие записи быстрее и эффективнее. Однако индексирование также может обладать и недостатками, например, увеличение требований к объёму хранилища и замедление выполнения операций вставки и обновления, поэтому перед созданием индекса следует взвесить плюсы и минусы.
Алгоритмы индексирования#
Как говорилось выше, существует множество алгоритмов индексирования, используемых для оптимизации скорости операций получения данных при помощи создания индексов столбцов таблиц. Вот некоторые из самых популярных алгоритмов индексирования баз данных:
- B-дерево
- Bitmap-индекс
- Хэш-индекс
- GiST (Generalized Search Tree, обобщённое поисковое дерево)
Каждый алгоритм индексирования имеет свои сильные и слабые стороны; давайте рассмотрим их по порядку.
B-дерево#
B-tree (сбалансированное дерево) — это самый распространенный тип индекса в PostgreSQL. Он поддерживает все стандартные операции сравнения (>, <, >=, <=, =, <>) и может использоваться с большинством типов данных. B-tree индексы могут быть использованы для сортировки, ограничений уникальности и поиска по диапазону значений.
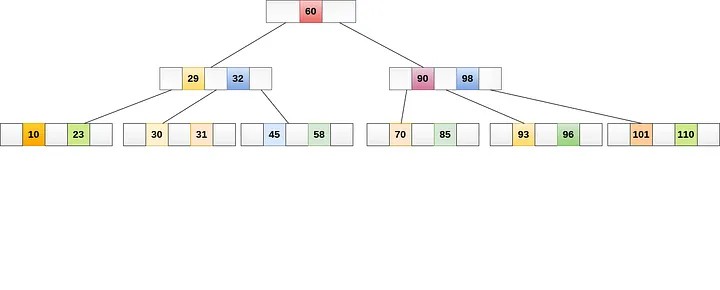
Самое большое преимущество алгоритма B-дерева заключается в минимизации количества дисковых операций ввода-вывода, необходимых для доступа к данным, потому что в B-дереве все узлы-листья находятся на одном уровне, а каждый узел может хранить множество ключей и указателей. Количество ключей и указателей, которое может храниться в узле, определяется параметром, называемым «порядок» дерева.
Однако B-деревья обладают некоторыми недостатками:
Излишняя трата ресурсов: B-деревья задействуют большой объём излишнего пространства, поскольку каждый узел в B-дереве содержит указатель на родительский и дочерний узлы.
Сложность: алгоритмы, используемые для вставки, удаления и поиска данных в B-дереве, сложнее по сравнению с другими структурами данных. Это усложняет реализацию и поддержку B-деревьев.
Медленные обновления: обновление данных в B-дереве может быть относительно медленным по сравнению с другими структурами данных. Каждая операция обновления требует множества операций доступа к диску, и этот процесс может быть медленным для больших B-деревьев.
Bitmap-индекс#
Bitmap-индексирование — это методика индексирования данных, использующая битовые карты (bitmap) для обозначения наличия или отсутствия значения в таблице. Это успешная техника индексирования для таблиц с низкой кардинальностью, где количество уникальных значений в столбце довольно мало по сравнению с общим количеством строк.
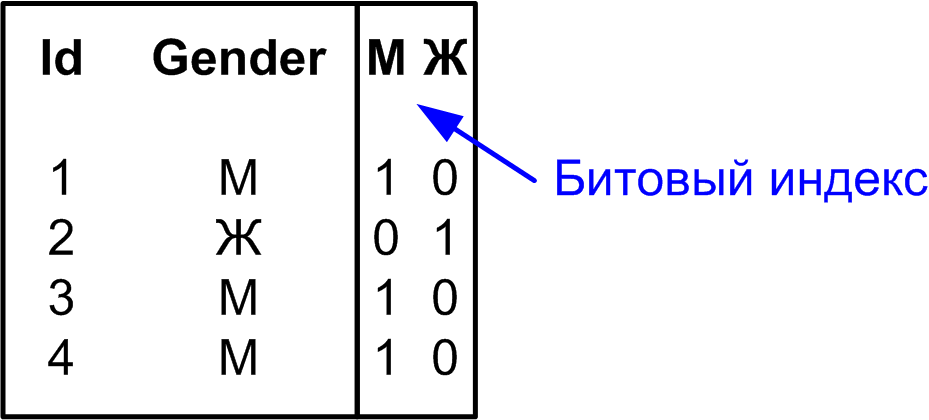
Bitmap-индексирование может быть очень эффективным для столбцов с низкой кардинальностью, поскольку битовые карты крайне компактны и их можно быстро сканировать для извлечения данных. Bitmap-индексы очень удобны для применения в хранилищах данных, где необходимо быстро сканировать огромные объёмы данных. Кроме того, они полезны для баз данных, в которых много операций чтения, но мало обновлений или вставок.
Bitmap-индексы имеют множество недостатков, и в том числе:
Большой размер: Bitmap-индексы могут быть большими, особенно при работе с крупными датасетами. Из-за этого они могут оказаться менее эффективными, чем другие методики индексирования.
Столбцы с высокой кардинальностью: Bitmap-индексы неэффективны для столбцов с высокой кардинальностью, где количество уникальных значений очень высоко. В таких случаях bitmap-индексы могут становиться очень большими и не помещаться в памяти.
Смещённое распределение данных: если данные смещены, у нескольких значений может быть гораздо более высокая частота, чем у других, и bitmap-индексы окажутся неэффективными. Это вызвано тем, что bitmap для наиболее частых значений становятся очень большими и могут доминировать в индексе.
Хэш-индекс#
Hash-индексы предназначены для обеспечения быстрого доступа к данным по равенству. Они менее эффективны, чем B-tree индексы, и не поддерживают сортировку или поиск по диапазону значений. Из-за своих ограничений, Hash-индексы редко используются на практике.
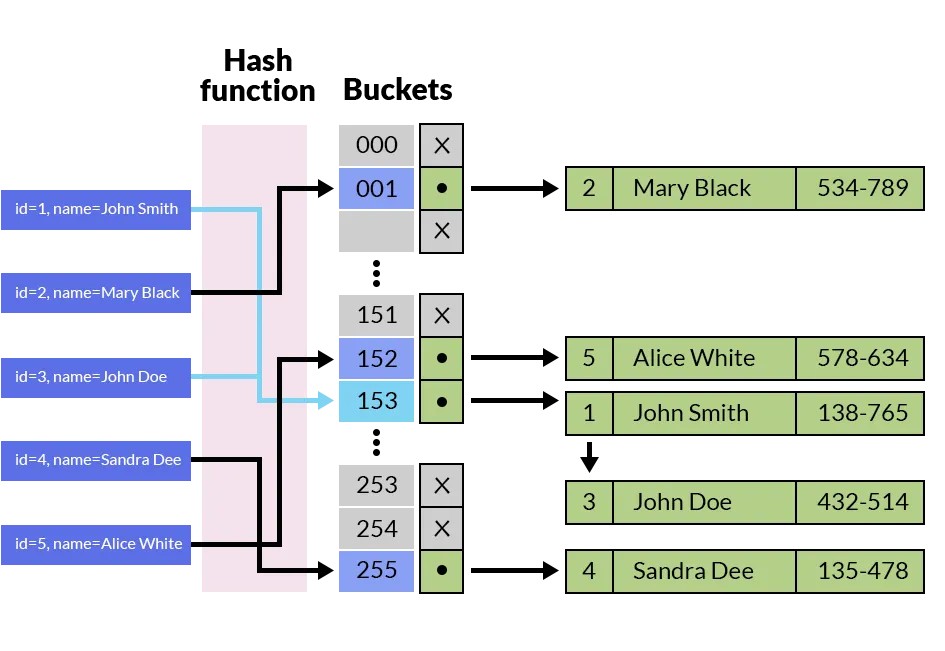
Сопоставление ключей индекса с местоположениями соответствующих записей данных позволяет выполнять быстрый поиск и вставки за постоянное время O(1). Однако этот метод плохо работает с запросами диапазонов или частичными совпадениями и может страдать от коллизий, с которыми можно справляться при помощи различных техник разрешения коллизий.
Ограниченные возможности поиска: хэш-индексы предназначены для обработки только поисков равенства (например, «найти все записи, где столбец A равен значению»). Они плохо подходят для запросов диапазонов или сортировки.
Коллизии: хэш-индексы могут иметь коллизии, при которых несколько ключей соответствуют одному хэш-значению. Это может привести к снижению производительности, поскольку базе данных нужно будет выполнять дополнительные операции для разрешения коллизий.
Непредсказуемые требования к размеру хранилища: размер хэш-индекса невозможно предугадать, так как он зависит от количества уникальных значений в индексируемом столбце. Это усложняет планирование требований к размеру хранилища.
GiST (Generalized Search Tree, обобщённое поисковое дерево)#
GiST (Generalized Search Tree, обобщённое поисковое дерево) — это техника индексирования баз данных, которая может использоваться для индексирования сложных типов данных, например, геометрических объектов
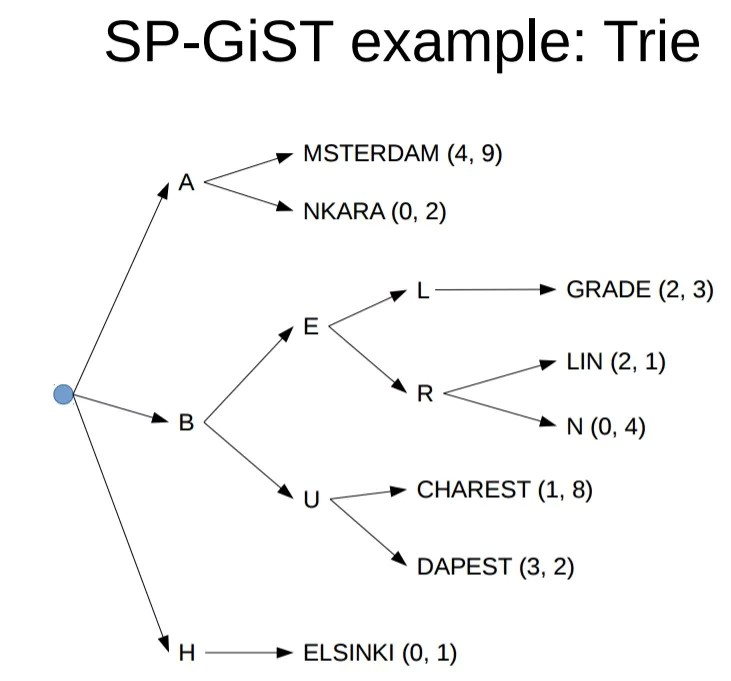
Это сбалансированная древовидная структура, состоящая из узлов с множественными дочерними узлами. Каждый узел описывает диапазон или множество значений и связан с предикативной функцией, проверяющей, принадлежит ли значение диапазону или множеству. Предикативная функция зависит от типа индексируемых данных и может быть подстроена под разные типы данных.
GiST часто используется для индексации пространственных данных, например, в PostGIS — расширении для PostgreSQL. Это особенно полезно, когда речь идет о запросах с геометрическими отношениями, таких как поиск объектов в радиусе, пересечение областей и другие пространственные запросы.
Для создания индекса необходим один столбец. По этой причине необходимо осуществить преобразование многомерных координат в одномерные. Одним из эффективных методов для достижения этой цели является Гильбертовая кривая. Это пространство-наполняющая кривая, которая помогает сохранить близость точек в многомерном пространстве.
Недостатки:
Сниженная скорость вставок и обновлений: структуры индексирования GiST могут быть сложнее, чем традиционные структуры индексирования, что может привести к снижению скорости операций вставки и обновления.
Больше дискового пространства: структуры индексирования GiST могут требовать больше дискового пространства, чем другие методики индексирования, поскольку хранят дополнительную информацию для поддержки различных типов поиска.
Подходит не для всех типов данных: GiST оптимизирован под индексирование сложных типов данных, например, пространственных данных, однако может быть не лучшим выбором для индексирования более простых типов данных, например, целочисленных значений или строк.
Повышенные затраты на поддержку: из-за сложности реализации индексы GiST требуют больше обслуживания по сравнению с традиционными индексами.
Использование#
Рассмотрим пять интересных примеров использования индексов в PostgreSQL в различных реальных сценариях. В каждом примере представлены код таблицы и индекса, а также объяснение того, как индекс может улучшить производительность запросов.
- Онлайн-магазин
В онлайн-магазине есть таблица orders с информацией о заказах. Пользователи могут искать заказы по customer_id, order_date и status. Создадим индексы для этих столбцов.
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
customer_id INT NOT NULL,
order_date DATE NOT NULL,
status VARCHAR(15) NOT NULL
);
CREATE INDEX ix_orders_customer_id ON orders (customer_id);
CREATE INDEX ix_orders_order_date ON orders (order_date);
CREATE INDEX ix_orders_status ON orders (status);
Индексы ускорят поиск заказов по customer_id, order_date и status.
- Система управления документацией
В системе управления документацией есть таблица documents с данными о документах. Пользователи могут искать документы по title, author_id и creation_date. Создадим индексы для этих столбцов и полнотекстовый индекс для content.
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
title VARCHAR(255) NOT NULL,
author_id INT NOT NULL,
creation_date DATE NOT NULL,
content TEXT NOT NULL
);
CREATE INDEX ix_documents_title ON documents (title);
CREATE INDEX ix_documents_author_id ON documents (author_id);
CREATE INDEX ix_documents_creation_date ON documents (creation_date);
-- Создание полнотекстового индекса для столбца content
CREATE INDEX ix_documents_content ON documents USING gin(to_tsvector('english', content));
Индексы ускорят поиск документов по title, author_id, creation_date, а также обеспечат быстрый полнотекстовый поиск по content.
- Система управления проектами
В системе управления проектами есть таблица tasks с информацией о задачах. Пользователи могут искать задачи по project_id, assigned_to и due_date. Создадим индексы для этих столбцов.
CREATE TABLE tasks (
id SERIAL PRIMARY KEY,
project_id INT NOT NULL,
assigned_to INT NOT NULL,
due_date DATE NOT NULL,
description TEXT NOT NULL
);
CREATE INDEX ix_tasks_project_id ON tasks (project_id);
CREATE INDEX ix_tasks_assigned_to ON tasks (assigned_to);
CREATE INDEX ix_tasks_due_date ON tasks (due_date);
Индексы ускорят поиск задач по
project_id, assigned_to и due_date.
- Социальная сеть
В социальной сети есть таблица friendships с информацией о дружественных связях между пользователями. Пользователи могут искать друзей по user_id и friend_id. Создадим индексы для этих столбцов.
CREATE TABLE friendships (
user_id INT NOT NULL,
friend_id INT NOT NULL,
since_date DATE NOT NULL,
PRIMARY KEY (user_id, friend_id)
);
CREATE INDEX ix_friendships_user_id ON friendships (user_id);
CREATE INDEX ix_friendships_friend_id ON friendships (friend_id);
Индексы ускорят поиск друзей по user_id и friend_id.
- Географическая информационная система (ГИС)
В ГИС есть таблица locations с географическими данными. Пользователи могут выполнять пространственные запросы к координатам geom. Создадим геометрический индекс для столбца geom.
CREATE TABLE locations (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
geom GEOMETRY(Point, 4326) NOT NULL
);
-- Созданиегеометрического индекса для столбца geom
CREATE INDEX ix_locations_geom ON locations USING gist(geom);