Механизмы управления реляционными базами данных#
Реляционные базы данных – это системы управления базами данных, в которых данные организованы в виде таблиц (или отношений). Каждая таблица состоит из строк и столбцов, где строки представляют записи (объекты), а столбцы – атрибуты (свойства) этих объектов. Основной принцип реляционной модели заключается в том, что все данные представляются в виде взаимосвязанных таблиц, что делает возможным выполнение сложных запросов для выборки, фильтрации и объединения данных.
Основные понятия:
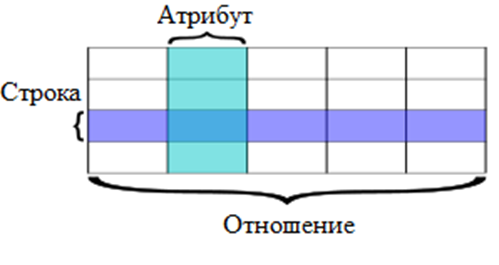
Таблица (Relation) – это основная структура хранения данных, представляющая собой двухмерную таблицу. Каждая строка таблицы называется записью, а каждый столбец – полем (атрибутом).
Первичный ключ (Primary Key) – уникальный идентификатор записи в таблице. Он обеспечивает однозначность каждой строки.
Отношение (Relation) – формальный термин для таблицы в реляционной модели. Каждое отношение является конечным набором записей с одинаковой структурой.
Формальное определение отношения#
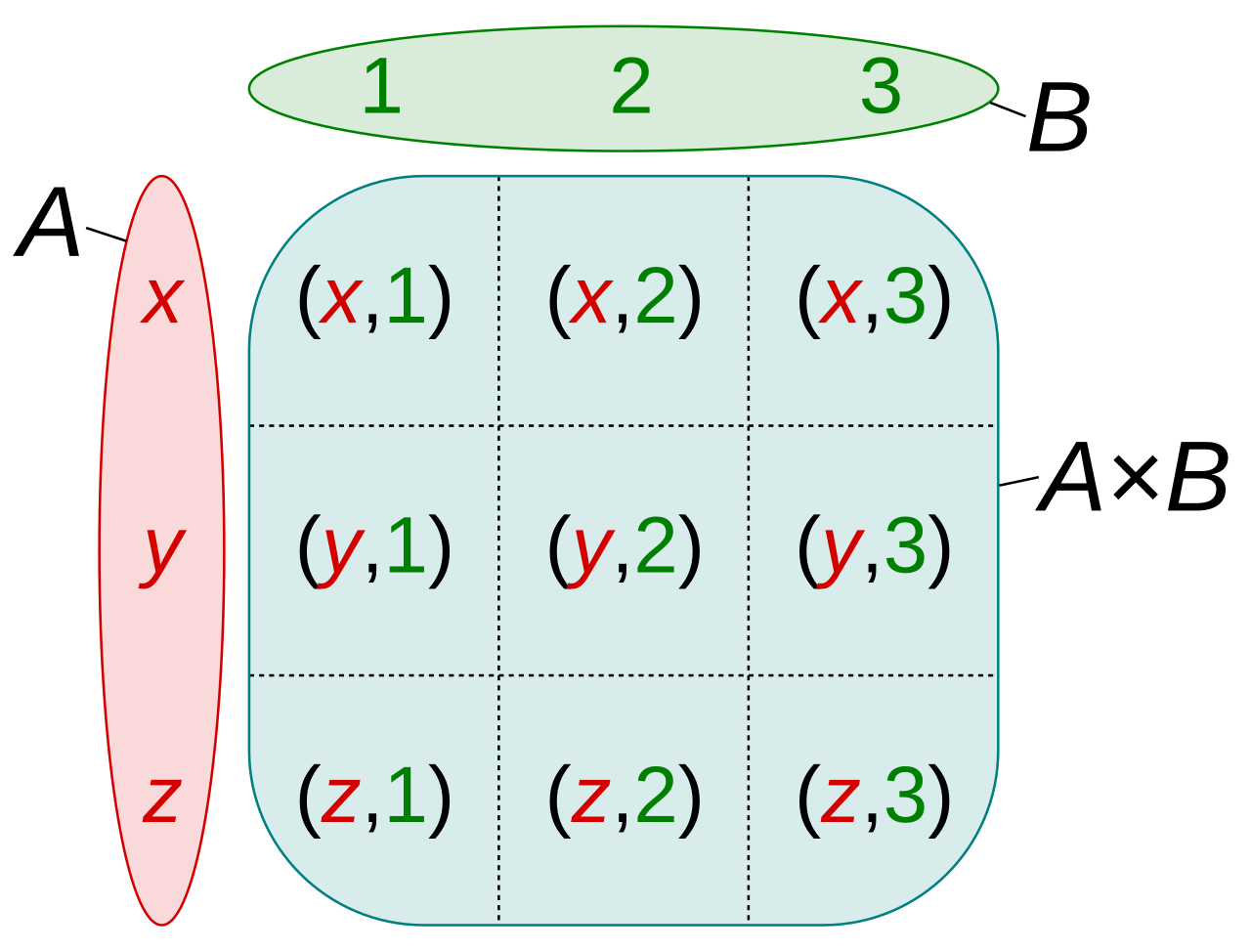
Пусть дана совокупность типов данных T1, T2, …, Tn, называемых также доменами, не обязательно различных. Тогда n-арным отношением R, или отношением R степени n называют подмножество декартовa произведения множеств T1, T2, …, Tn
Отношение R состоит из заголовка (схемы) и тела. Заголовок представляет собой множество атрибутов (именованных вхождений домена в заголовок отношения), а тело — множество кортежей, соответствующих заголовку. Более строго:
- Заголовок (или схема) H отношения R — конечное множество упорядоченных пар вида (Ai, Ti), где Ai — имя атрибута, а Ti — имя типа (домена), i=1,…, n. По определению требуется, чтобы все имена атрибутов в заголовке отношения были различными (уникальными).
- Тело B отношения R — множество кортежей t. Кортеж t, соответствующий заголовку H, — множество упорядоченных триплетов (троек) вида
Количество кортежей называют кардинальным числом отношения (кардинальностью), или мощность отношения.
Количество атрибутов называют степенью, или «арностью» отношения; отношение с одним атрибутом называется унарным, с двумя — бинарным и т. д., с n атрибутами — n-арным. С точки зрения теории вполне корректным является и отношение с нулевым количеством атрибутов, которое либо не содержит кортежей, либо содержит единственный кортеж без компонент (пустой кортеж)
Основные свойства отношения:
- В отношении нет двух одинаковых элементов (кортежей).
- Порядок кортежей в отношении не определён.
- Порядок атрибутов в заголовке отношения не определён.
Подмножество атрибутов отношения, удовлетворяющее требованиям уникальности и минимальности (несократимости), называется потенциальным ключом. Поскольку все кортежи в отношении по определению уникальны, в любом отношении должен существовать по крайней мере один потенциальный ключ.
Отношение обычно имеет простую графическую интерпретацию в виде таблицы, столбцы которой соответствуют атрибутам, а строки — кортежам, а в «ячейках» находятся значения атрибутов в кортежах. Тем не менее, в строгой реляционной модели отношение не является таблицей, кортеж — это не строка, а атрибут — это не столбец. Термины «таблица», «строка», «столбец» могут использоваться только в неформальном контексте, при условии полного понимания, что эти более «дружественные» термины являются всего лишь приближением и не дают точного представления о сути обозначаемых понятий
В соответствии с определением К. Дж. Дейта, таблица является прямым и верным представлением некоторого отношения, если она удовлетворяет следующим пяти условиям:
1. Нет упорядочивания строк сверху вниз (другими словами, порядок строк не несёт в себе никакой информации).
2. Нет упорядочивания столбцов слева направо (другими словами, порядок столбцов не несёт в себе никакой информации).
3. Нет повторяющихся строк.
4. Каждое пересечение строки и столбца содержит ровно одно значение из соответствующего домена (и больше ничего).
5. Все столбцы являются обычными. «Обычность» всех столбцов таблицы означает, что в таблице нет «скрытых» компонентов, которые могут быть доступны только в вызове некоторого специального оператора взамен ссылок на имена регулярных столбцов, или которые приводят к побочным эффектам для строк или таблиц при вызове стандартных операторов. Таким образом, например, строки не имеют идентификаторов, кроме обычных значений потенциальных ключей (без скрытых «идентификаторов строк» или «идентификаторов объектов»). Они также не имеют скрытых временны́х меток.
Пример#
Пусть заданы следующие типы (домены):
T1 = {Иванов, Петров, Сидоров}
T2 = {Информатика, Геодезия}
T3 = {5,5,4}
Тогда декартово произведение
𝑇1 × 𝑇2 × 𝑇3 состоит из 18 кортежей, где каждый кортеж содержит три значения: первое —
одна из фамилий, второе — учебная дисциплина, а третье — оценка.
| Фамилия | Дисциплина | Оценка |
|---|---|---|
| Иванов | Информатика | 3 |
| Иванов | Информатика | 5 |
| Иванов | Информатика | 4 |
| Иванов | Геодезия | 3 |
| Иванов | Геодезия | 5 |
| Иванов | Геодезия | 4 |
| Петров | Информатика | 3 |
| Петров | Информатика | 5 |
| Петров | Информатика | 4 |
| Петров | Геодезия | 3 |
| Петров | Геодезия | 5 |
| Петров | Геодезия | 4 |
| Сидоров | Информатика | 3 |
| Сидоров | Информатика | 5 |
| Сидоров | Информатика | 4 |
| Сидоров | Геодезия | 3 |
| Сидоров | Геодезия | 5 |
| Сидоров | Геодезия | 4 |
Тогда тело отношения R может моделировать реальную ситуацию и содержать пять кортежей, которые соответствуют результатам сессии (при условии, что Петров экзамен по Информатике не сдавал). Отобразим отношение в виде таблицы:
| Фамилия | Дисциплина | Оценка |
|---|---|---|
| Иванов | Информатика | 5 |
| Иванов | Геодезия | 4 |
| Петров | Геодезия | 5 |
| Сидоров | Информатика | 3 |
| Сидоров | Геодезия | 5 |
Реляционная алгебра#
Реляционная алгебра представляет собой набор таких операций над отношениями, что результат каждой из операций также является отношением. Это свойство алгебры называется замкнутостью.
N-арную реляционную операцию f можно представить функцией, возвращающей отношение и имеющей n отношений в качестве аргументов:
R = f(R₁, R₂, ... , Rₙ)
Поскольку реляционная алгебра является замкнутой, в качестве операндов в реляционные операции можно подставлять другие выражения реляционной алгебры (подходящие по типу):
R = f(f₁(R₁₁, R₁₂, ... ), f₂(R₂₁, R₂₂, ... ), ...)
В реляционных выражениях можно использовать вложенные выражения сколь угодно сложной структуры.
Каждое отношение обязано иметь уникальное имя в пределах базы данных. Имя отношения, полученного в результате выполнения реляционной операции, определяется в левой части равенства. Однако можно не требовать наличия имен от отношений, полученных в результате реляционных выражений, если эти отношения подставляются в качестве аргументов в другие реляционные выражения. Такие отношения будем называть неименованными отношениями. Неименованные отношения реально не существуют в базе данных, а только вычисляются в момент вычисления значения реляционного оператора.
Ниже приведён список из восьми операций, изначально предложенных создателем реляционной модели Эдгаром Коддом. Все операции из списка, кроме деления, по-прежнему широко востребованы, однако список не является исчерпывающим, то есть по факту используется гораздо большее число реляционных операций.
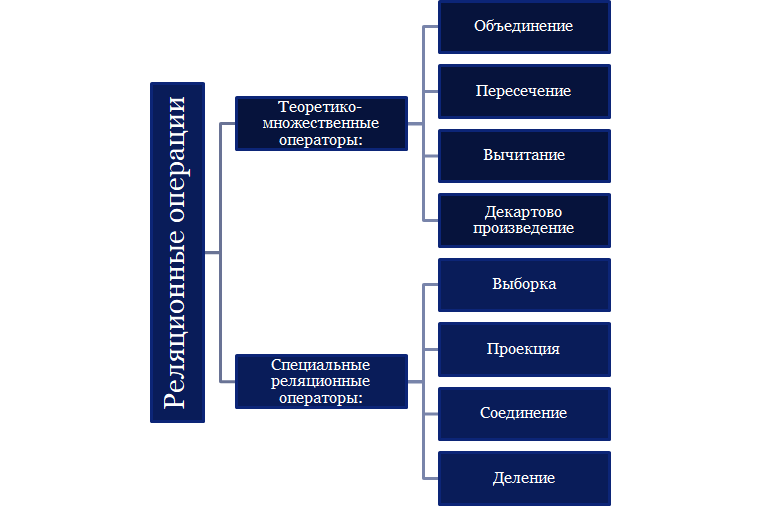
Теоретико-множественные операторы#
- ПРОИЗВЕДЕНИЕ (×): построить декартово произведение двух отношений. Пусть R - таблица, со степенью k1 и пусть S таблица со степенью k2. R × S - это множество всех k1 + k2 - кортежей, где первыми являются k1 элементы кортежа R и где последними являются k2 элементы кортежа S.
- ОБЪЕДИНЕНИЕ(UNION) (∪): построить теоретико-множественное объединение двух таблиц. Даны таблицы R и S (обе должны иметь одинаковую степень), объединение R ∪ S - это множество кортежей, принадлежащих R или S или обоим.
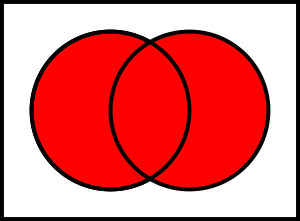
- ПЕРЕСЕЧЕНИЕ(INTERSECT) (∩): построить теоретико-множественное пересечение двух таблиц. Даны таблицы R и S, R ∪ S - это множество кортежей, принадлежащих R и S. Опять необходимо, чтобы R и S имели одинаковую степень.
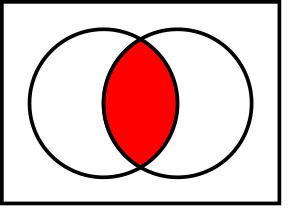
- ВЫЧИТАНИЕ(DIFFERENCE) (− или ∖): построить множество различий двух таблиц. Пусть R и S опять две таблицы с одинаковой степенью. R - S - это множество кортежей R,не принадлежащих S.
Специальные реляционные операторы#
- ВЫБОРКА(SELECT) (σ): извлечь кортежи из отношения, которые удовлетворяют заданным условиям. Пусть R - таблица, содержащая атрибут A. σA=a(R) = {t ∈ R ∣ t(A) = a} где t обозначает кортеж R и t(A) обозначает значение атрибута A кортежа t.
В простейшем случае условие имеет вид σ_C(R), где C — один из операторов сравнения (например, =, ≠, <, >, и т.д.), а A и B — атрибуты отношения R или скалярные значения. Такие выборки называются θ-выборками (тэта-выборками) или условиями θ-селекции.
Синтаксис операции выборки:
σ_C(R)SELECT * FROM R WHERE C
Пример
Пусть дано отношение с информацией о сотрудниках:
| Табельный номер | Фамилия | Зарплата |
|---|---|---|
| 1 | Иванов | 1000 |
| 2 | Петров | 2000 |
| 3 | Сидоров | 3000 |
Отношение A
Результат выборки σ_Зарплата < 3000(A) будет иметь вид:
| Табельный номер | Фамилия | Зарплата |
|---|---|---|
| 1 | Иванов | 1000 |
| 2 | Петров | 2000 |
Отношение A WHERE Зарплата < 3000
Смысл операции выборки очевиден — выбрать кортежи отношения, удовлетворяющие некоторому условию. Таким образом, операция выборки дает "горизонтальный срез" отношения по некоторому условию.
- ПРОЕКЦИЯ (π): извлечь заданные атрибуты (колонки) из отношения. Пусть R отношение, содержащее атрибут X. πX(R) = {t(X) ∣ t ∈ R}, где t(X) обозначает значение атрибута X кортежа t.
При осуществлении проекции необходимо задать проецируемое отношение и некий набор его атрибутов, который станет заголовком результирующего.
Замечание
Операция проекции дает "вертикальный срез" отношения, в котором удалены все дубликаты кортежей, возникшие при таком срезе.
Пример
Пусть дано отношение с информацией о поставщиках, включающих наименование и месторасположение:
| Номер поставщика | Наименование поставщика | Город поставщика |
|---|---|---|
| 1 | Иванов | Уфа |
| 2 | Петров | Москва |
| 3 | Сидоров | Москва |
| 4 | Сидоров | Челябинск |
Проекция на атрибут "Город поставщика" будет иметь вид:
| Город поставщика |
|---|
| Уфа |
| Москва |
| Челябинск |
- СОЕДИНЕНИЕ(JOIN) (∏): соединить две таблицы по их общим атрибутам. Пусть R будет таблицей с атрибутами A,B и C и пусть S будет таблицей с атрибутами C,D и E. Есть один атрибут, общий для обоих отношений, атрибут C. R ∏ S = πR.A,R.B,R.C,S.D,S.E(σR.C=S.C(R × S)). Что же здесь происходит? Во-первых, вычисляется декартово произведение R × S. Затем, выбираются те кортежи, чьи значения общего атрибута C эквивалентны (σR.C = S.C). Теперь мы имеем таблицу, которая содержит атрибут C дважды и мы исправим это, выбросив повторяющуюся колонку.
Операция соединения отношений, наряду с операциями выборки и проекции, является одной из наиболее важных реляционных операций.
Имеются два отношения: Служащий и Отдел. Задано условие соединения: «Служащий.[Код отдела] = Отдел.[Код отдела]».
Служащий
| Фамилия | Код отдела |
|---|---|
| Иванов | 34 |
| Петров | 36 |
| Сидоров | 34 |
| Сергеев | 34 |
Отдел
| Название | Код отдела |
|---|---|
| Бухгалтерия | 34 |
| Маркетинг | 36 |
Результатом операции соединения будет:
Результат соединения
| Служащий.Фамилия | Служащий.Код отдела | Отдел.Название | Отдел.Код отдела |
|---|---|---|---|
| Иванов | 34 | Бухгалтерия | 34 |
| Петров | 36 | Маркетинг | 36 |
| Сидоров | 34 | Бухгалтерия | 34 |
| Сергеев | 34 | Бухгалтерия | 34 |
На уровне реализации операция соединения обычно не выполняется как выборка из декартова произведения. Предложены более эффективные алгоритмы, гарантирующие получение такого же логического результата.
Обычно рассматривается несколько разновидностей операции соединения:
- Общая операция соединения
- соединение (тэта-соединение) θ-соединение определяет отношение, которое содержит кортежи из
декартова произведения отношений R и S, удовлетворяющие предикату p.
Предикат p имеет форму R.ai θ S.bi, где θ может являться одним их операторов сравнения (<, ≤, >, ≥, =, ≠), а R.ai и S.bi – атрибуты отношений R и S соответственно. - Эквисоединение – это частный случай θ-соединения. Он имеет место, когда в качестве оператора сравнения используется только проверка на равенство (=).
- Естественное соединение – это частный случай эквисоединения. Он имеет место, когда отношения R и S соединяются по всем общим атрибутам. Один экземпляр каждого из общих атрибутов исключается из результирующего отношения
Наиболее важным из этих частных случаев является операция естественного соединения. Все разновидности соединения являются частными случаями общей операции соединения.
Естественное соединение – это частный случай эквисоединения. Он имеет место, когда отношения R и S соединяются по всем общим атрибутам. Один экземпляр каждого из общих атрибутов исключается из результирующего отношения
Пусть даны отношения A(A1, A2, ... ,An, X1,X2, ...Xp) и B(X1,X2, ..., Xp, B1, B2, ..., Bm), имеющие одинаковые атрибуты X1,X2, ..., Xp (т.е атрибуты с одинаковыми именами и определенные на одинаковых доменах)
Тогда естественным соединением отношений А и В называется отношение с заголовком (A1, A2, ... ,An, X1,X2, ...Xp, B1, B2, ..., Bm) и телом содержащим множество кортежей (a1,a2, .., an, x1,x2,..,xn,b1,b2...,bn) таких, что (a1,a2, .., an, x1,x2,..,xn) ∈ A и (x1,x2,..,xn,b1,b2...,bn) ∈ В.
Естественное соединение настолько важно, что для него используют специальный синтаксис:
A JOIN B
Замечание 1. В синтаксисе естественного соединения не указываются, по каким атрибутам производится соединение. Естественное соединение производится по всем одинаковым атрибутам.
Замечание 2. амечание. Естественное соединение эквивалентно следующей последовательности реляционных операций:
- Переименовать одинаковые атрибуты в отношениях
- Выполнить декартово произведение отношений
- Выполнить выборку по совпадающим значениям атрибутов, имевших одинаковые имена
- Выполнить проекцию, удалив повторяющиеся атрибуты
- Переименовать атрибуты, вернув им первоначальные имена
Замечание 3. Можно выполнять последовательное естественное соединение нескольких отношений. Нетрудно проверить, что естественное соединение (как, впрочем, и соединение общего вида) обладает свойством ассоциативности, т.е.
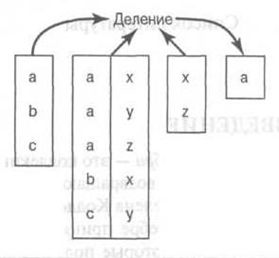
- ДЕЛЕНИЕ (DIVISION) (÷): деление применяется, когда нужно найти множество значений, связанных со всеми значениями другого множества. Пусть
R – отношение с атрибутами
A,B, а S – унарное отношение с атрибутом
B. Тогда
𝑅
÷
𝑆
– это множество значений
A, для которых в
R существуют все соответствующие значения из
S.
Замечание. Типичные запросы, реализуемые с помощью операции деления, обычно в своей формулировке имеют слово "все"
Предположим, что отношения R и S, соответственно, имеют следующие атрибуты: XI, Х2, . . . ,Хm и Yl, Y2, ..., Yn. Здесь ни один из атрибутов Xi (i = 1, 2, . . ., m) не имеет одинакового имени с любым из атрибутов Yj (j = 1, 2, . . ., п).
Пусть отношение T имеет следующие атрибуты: XI, Х2, . . . ,Хm и Yl, Y2, ..., Yn.
Это означает, что T имеет заголовок, представляющий собой (теоретико- множественное) объединение заголовков отношений R и S. Будем рассматривать множества {XI, Х2, . . . ,Хm} и {Yl, Y2, ..., Yn}, соответственно, как составные атрибуты X и Y. В таком случае операция деления R на S по T (где R — делимое, S — делитель, а T — посредник) может быть представлена с помощью следующего выражения:
R DIVIDEBY S PER T
Результат представляет собой отношение с заголовком
{ X } и телом, состоящим из таких кортежей { X х },
присутствующих в R, что кортеж { X х, Y у } присутствует в T для всех кортежей { Y у }, присутствующих в S.
Иными словами, данный результат состоит из тех значений X, присутствующих в R, для которых соответствующие значения Y в T включают все значения Y из S.
Выразимость одних операций через другие#
Некоторые из реляционных операций могут быть выражены через другие реляционные операторы.
- Оператор пересечения выражается через вычитание следующим образом:
A ∩ B = A – ( A – B)
-
Оператор соединения определяется через операторы декартова произведения и выборки следующим образом:
( A TIMES B ) WHERE X = Y -
Оператор деления выражается через операторы вычитания, декартова произведения и проекции следующим образом:
( A / B ) = A [X] MINUS ((A[X] TIMES B) MINUS A)[X]
Методы моделирования БД#
Моделирование данных обычно начинается с концептуального представления данных, а затем их повторного представления в контексте выбранных технологий.
Аналитики и заинтересованные стороны создают несколько различных типов моделей данных на этапе проектирования данных.
В СУБД используются три основных типа моделей данных: концептуальные, логические и физические. Каждый тип модели данных служит разным целям и представляет собой разный уровень абстракции.
Концептуальное моделирование#
Концептуальное моделирование данных представляет собой первый шаг в процессе моделирования данных, ориентированный на высокоуровневое абстрактное представление требований организации к данным. Он включает в себя идентификацию ключевых объектов данных, их атрибутов и связей между ними, не вдаваясь в подробности о типах данных или хранении. Основная цель концептуального моделирования данных — четко понять требования бизнеса и сформировать прочную основу для следующих этапов моделирования данных (логического и физического моделирования).
Концептуальная модель данных — это абстрактное представление данных организации на высоком уровне. Он фокусируется на сборе сущностей, их атрибутов и отношений без указания каких-либо деталей реализации. Основная цель концептуального моделирования данных — четко понять бизнес-требования и облегчить общение между заинтересованными сторонами, такими как бизнес-аналитики, разработчики и конечные пользователи
Основными компонентами концептуального моделирования данных являются:
- Сущности: представляют ключевые объекты или концепции в предметной области, такие как клиенты, продукты, заказы или сотрудники.
- Атрибуты: определите свойства объектов, такие как имя клиента, цена продукта, дата заказа или идентификатор сотрудника.
- Отношения: представляют связи между объектами, такими как клиент, размещающий несколько заказов, продукт, принадлежащий к категории, или сотрудник, работающий в определенном отделе.
Создание концептуальной модели данных включает в себя несколько этапов:
- Определите объекты: перечислите ключевые объекты вашего домена, которые будут включены в базу данных. Подумайте, какие объекты имеют первостепенное значение и требуют хранения и поиска.
- Определить атрибуты: Определите атрибуты каждой сущности, относящиеся к области вашей модели данных. Сосредоточьтесь на основных свойствах каждой сущности, не углубляясь в такие подробности, как типы данных или ограничения.
- Установите отношения: проанализируйте связи между объектами и определите существующие отношения, гарантируя, что предлагаемые отношения имеют смысл с точки зрения бизнеса.
- Обзор и уточнение. Просмотрите исходную концептуальную модель на предмет несоответствий, избыточности и недостающей информации. При необходимости обновляйте модель, чтобы повысить ее точность и полноту.
В конце процесса концептуального моделирования данных вы получите четкое высокоуровневое представление вашей модели данных, которое послужит основой для следующего этапа процесса — логического моделирования данных.
Пример концептуальной модели перелетов
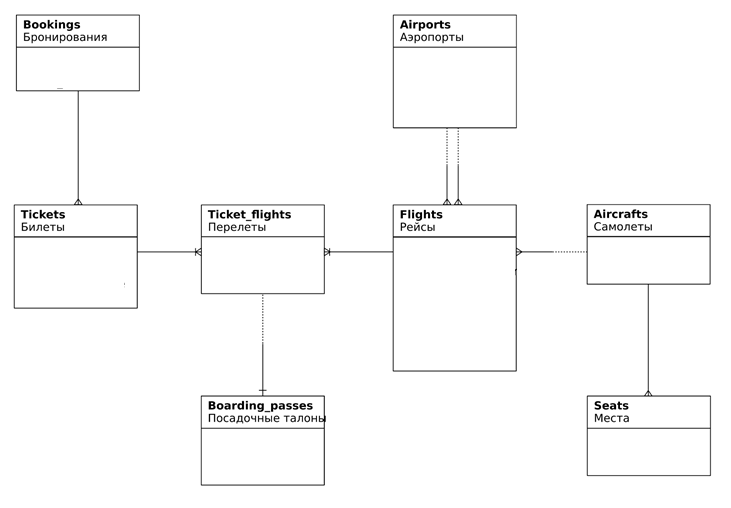
Основной сущностью является бронирование (bookings).
В одно бронирование можно включить несколько пассажиров, каждому из которых выписывается отдельный билет (tickets). Билет имеет уникальный номер и содержит информацию о пассажире. Как таковой пассажир не является отдельной сущностью. Как имя, так и номер документа пассажира могут меняться с течением времени, так что невозможно однозначно найти все билеты одного человека; для простоты можно считать, что все пассажиры уникальны.
Билет включает один или несколько перелетов (ticket_flights). Несколько перелетов могут включаться в билет в случаях, когда нет нет прямого рейса, соединяющего пункты отправления и назначения (полет с пересадками), либо когда билет взят «туда и обратно». В схеме данных нет жесткого ограничения, но предполагается, что все билеты в одном бронировании имеют одинаковый набор перелетов.
Каждый рейс (flights) следует из одного аэропорта (airports) в другой. Рейсы с одним номером имеют одинаковые пункты вылета и назначения, но будут отличаться датой отправления.
При регистрации на рейс пассажиру выдается посадочный талон (boarding_passes), в котором указано место в самолете. Пассажир может зарегистрироваться только на тот рейс, который есть у него в билете. Комбинация рейса и места в самолете должна быть уникальной, чтобы не допустить выдачу двух посадочных талонов на одно место.
Количество мест (seats) в самолете и их распределение по классам обслуживания зависит от модели самолета (aircrafts), выполняющего рейс. Предполагается, что каждая модель самолета имеет только одну компоновку салона. Схема данных не контролирует, что места в посадочных талонах соответствуют имеющимся в самолете (такая проверка может быть сделана с использованием табличных триггеров или в приложении).
Логическое моделирование#
Логическая модель данных — это усовершенствованная модель концептуальной модели данных, в которой сущности, атрибуты и связи дополнительно детализированы и организованы. На этом этапе определяются дополнительные ограничения и правила, а элементы данных организуются в таблицы и столбцы. Логическая модель данных является основой физической модели данных, которая фокусируется на фактических деталях реализации в конкретной СУБД
Логическое моделирование данных уточняет и расширяет концептуальную модель данных, добавляя более подробную информацию об атрибутах, типах данных и отношениях. Это более детальное представление модели данных, независимое от конкретной системы управления базами данных (СУБД) или технологии. Основная цель логического моделирования данных — точно определить структуру и отношения между сущностями, сохраняя при этом определенную степень абстракции от фактической реализации.
Компоненты логического моделирования данных
Важнейшими компонентами логического моделирования данных являются:
- Сущности, атрибуты и связи. Эти компоненты сохраняют свое первоначальное значение и назначение из концептуальной модели данных.
- Типы данных: назначьте определенные типы данных каждому атрибуту, определяя тип информации, которую он может хранить, например целые числа, строки или даты.
- Ограничения: определите правила или ограничения, которым должны соответствовать данные, хранящиеся в атрибутах, такие как уникальность, ссылочная целостность или ограничения домена.
Создание логической модели данных включает в себя несколько шагов:
- Уточнение сущностей, атрибутов и связей: просмотрите и обновите компоненты, перенесенные из концептуальной модели данных, гарантируя, что они точно отражают предполагаемые бизнес-требования. Ищите возможности сделать модель более эффективной, например, идентифицируя повторно используемые сущности или атрибуты.
- Определите типы данных и ограничения: назначьте соответствующие типы данных каждому атрибуту и укажите любые ограничения, которые необходимо применять для обеспечения согласованности и целостности данных.
- Нормализация логической модели данных. Примените методы нормализации, чтобы устранить избыточность и повысить эффективность модели данных. Убедитесь, что каждая сущность и ее атрибуты соответствуют требованиям различных нормальных форм (1НФ, 2НФ, 3НФ и т. д.).
Пример концептуальной модели перелетов
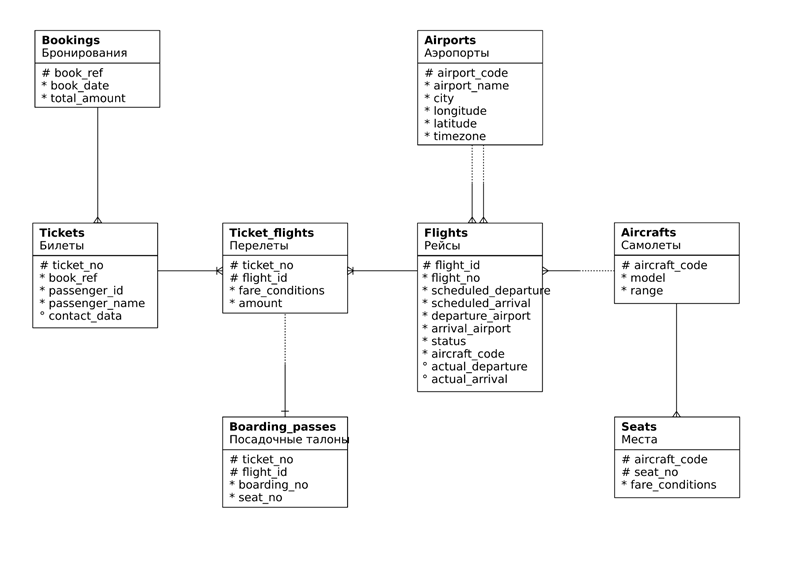
Таблицы:
1) Aircrafts – код самолета, модель самолета, максимальная дальность полета(км)
2) Airports – код аэропорта, название аэропорта, город, координаты города (широта, долгота), временная зона аэропорта
3) Boarding_passes – номер билета, идентификатор рейса, номер посадочного талона, номер места
4) Bookings – номер бронирования, дата бронирования, полная сумма бронирования
5) Flights – идентификатор рейса, номер рейса, время вылета по расписанию, время прилета по расписанию, аэропорт отправления, аэропорт прибытия, статус рейса, код самолета, фактическое время вылета, фактическое время прилета
6) Seats – код самолета, номер места, класс обслуживания
7) Ticket_flights – номер билета, идентификатор рейса, класс обслуживания, стоимость перелета
8) Tickets – номер билета, номер бронирования, идентификатор пассажира, имя пассажира, контактные данные пассажира
Представления:
1) Bookings.flights_v - идентификатор рейса, номер рейса, время вылета по расписанию + местное, время прилета по расписанию + местное, планируемая продолжительность полета, код аэропорта отправления, название аэропорта отправления, город отправления, код аэропорта прибытия, название аэропорта прибытия, город прибытия, статус рейса, код самолета, фактическое время вылета + местное, фактическое время прилета + местное, фактическая продолжительность полета
2) Routes – материализованное представление. Номер рейса, код аэропорта отправления, название аэропорта отправления, город отправления, код аэропорта прибытия, название аэропорта прибытия, город прибытия, код самолёта, продолжительность полета, дни недели, когда выполняется рейс
Физическое моделирование#
Моделирование физических данных — это последний этап процесса моделирования данных, на котором логическая модель данных преобразуется в реальную реализацию с использованием конкретной системы управления базами данных (СУБД) и технологии. Это наиболее детальное представление модели данных, содержащее всю необходимую информацию для создания и управления объектами базы данных, такими как таблицы, индексы, представления и ограничения.
Ключевые компоненты моделирования физических данных включают в себя:
- Таблицы: представляют собой фактические структуры хранения для сущностей в модели данных, причем каждая строка в таблице соответствует экземпляру сущности.
- Столбцы: соответствуют атрибутам в логической модели данных, определяя тип данных, ограничения и другие свойства, специфичные для базы данных, для каждого атрибута.
- Индексы. Определите дополнительные структуры, которые повышают скорость и эффективность операций поиска данных в таблицах.
- Внешние ключи и ограничения: представляют связи между таблицами, обеспечивая поддержание ссылочной целостности на уровне базы данных.
Создание физической модели данных включает в себя несколько этапов:
- Выберите СУБД: выберите конкретную систему управления базами данных (например, PostgreSQL , MySQL или SQL Server), на которой будет реализована физическая модель данных. Этот выбор определит доступные функции модели, типы данных и ограничения.
- Сопоставьте логические объекты с таблицами. Создайте таблицы в выбранной СУБД, чтобы представить каждый объект в логической модели данных и их атрибуты в виде столбцов в таблице.
- Определите индексы и ограничения. Создайте все необходимые индексы для оптимизации производительности запросов и определите ограничения внешнего ключа для обеспечения ссылочной целостности между связанными таблицами.
- Создание объектов базы данных. Используйте инструмент моделирования данных или вручную напишите сценарии SQL для создания реальных объектов базы данных, таких как таблицы, индексы и ограничения, на основе физической модели данных.
Модель физических данных, созданная на этом заключительном этапе, является не только важным документом для разработки и обслуживания базы данных, но также служит важным справочным материалом для других заинтересованных сторон, включая бизнес-аналитиков, разработчиков и системных администраторов.
Методы моделирования#
Для логического проектирования реляционных ХД применяются следующие методики
- Метод моделирования "сущность-связь" (ER modeling) дает абстрактную модель предметной области, используя следующие основные понятия: сущности (entities), взаимосвязи (relationships) между сущностями и атрибуты (attributes) для представления свойств сущностей и взаимосвязей.
- Метод многомерного моделирования (Dimensional modeling) дает абстрактную модель предметной области, используя следующие основные понятия: показатели или метрики (measures), факты (facts) и измерения (dimensions).
- Методы моделирования временных данных (Temporal data modeling) дают абстрактную модель фрагмента предметной области, представляющего временные ряды данных, и используют следующие основные понятия: временные метки (timestamps), временной ряд (time series), дата, диапазон дат, классы.
- Метод моделирования "свод данных" (Data Vault) дает абстрактную модель фрагмента предметной области, основываясь на математических принципах нормализации отношений, и использует следующие основные понятия: сущности-концентраторы (Hub Entities), связывающие сущности (Link Entities), сущности-сателлиты (Satellite Entities),
Основные понятия модели "сущность-связь"#
Системный аналитик начинает работу над новым проектом с изучения его предметной области и терминов, которые в ней используют. Например, нужно создать систему для бронирования билетов на самолёт. Аэропорт, авиакомпания, дата, рейс, пассажир, пункты прибытия и назначения, багаж — термины проекта. Их ещё называют понятиями или сущностями.
В системе сущность представлена в виде экземпляров. Например, экземпляры сущности «Аэропорт» ― аэропорты «Домодедово», «Пулково», «Воронеж».
У сущностей есть атрибуты — характеристики, которые их описывают. Например, атрибутами сущности «Аэропорт» будут код, адрес, номер телефона. Атрибуты есть у каждого экземпляра сущности, но у них разные значения. У аэропортов «Домодедово» и «Воронеж» есть одинаковый атрибут «Адрес», но у каждого из них разное значение этого атрибута.
Собрав все сущности будущего проекта, системный аналитик выясняет, как они связаны между собой, и составляет ER-модель (сокр. от entity–relationship модель или модель «сущность-связь»). В модели есть три типа связей:
● «Один-к-одному» — один экземпляр сущности связан только с одним экземпляром другой сущности. Например, пассажир рейса и его место в самолете.
● «Один-ко-многим» — один экземпляр сущности связан со множеством экземпляров другой сущности. Например, у одного пассажира может быть несколько единиц багажа, при этом каждая единица багажа может быть связана только с одним пассажиром.
● «Многие-ко-многим» — множество экземпляров одной сущности связаны со множеством экземпляров другой сущности. Например, аэропорт обслуживает несколько авиакомпаний. При этом каждая авиакомпания может обслуживаться в нескольких аэропортах.
Системный аналитик создаёт ER-диаграмму модели данных. Это схема, которая показывает, с какими данными нужно будет работать для реализации проекта и как эти данные связаны между собой. Например, ER-диаграмма проиллюстрирует, что багаж связан с номером рейса, но не связан со временем окончания посадки пассажиров на него.
Чтобы создать ER-модель, не нужны специальные инструменты. Её можно построить вручную в любом графическом редакторе: для диаграмм «сущность-связь» используют простые символы вроде квадратов, стрелок и линий.
Для того чтобы построить ER-диаграмму, можно использовать разные нотации. Три самые известные из них:
-
Нотация IDEF1X. Её относят к фундаментальным, но на практике давно не используют, потому что есть более удобные варианты.
-
Нотация Чена. Классическая нотация, которая состоит из простых символов — прямоугольников, овалов и линий. Из-за этого нотацию часто используют для концептуальных моделей, которые презентуют заказчику. Человеку, который далёк от аналитики данных, проще разобраться в понятных диаграммах со знакомыми символами.
-
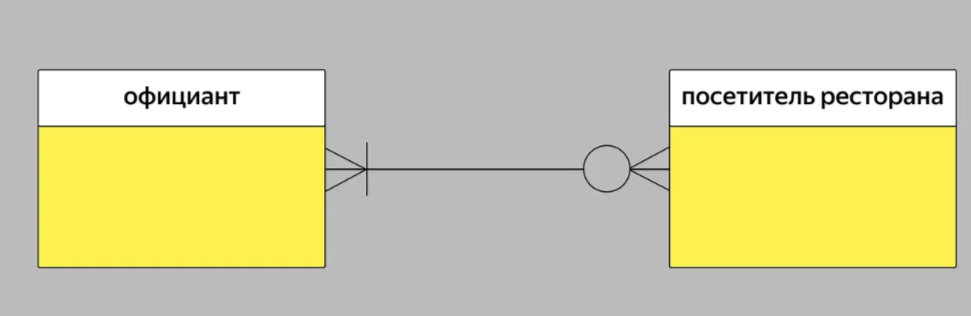
Нотация Мартина. Её ещё называют «воронья лапка» (от англ. Crow's Foot). Она компактнее нотации Чена, поэтому её используют для построения ER-моделей логического уровня, когда нужно описать в модели все атрибуты сущностей.
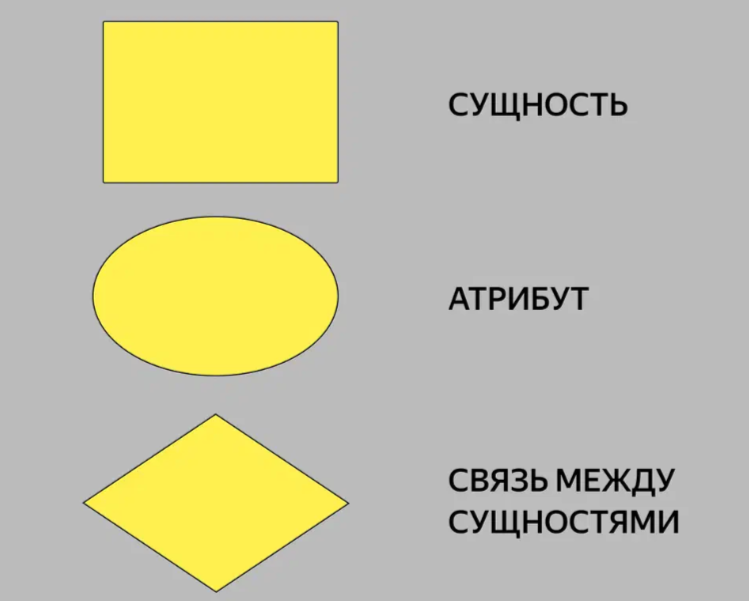
Элементы ER-диаграммы в нотации Чена соединяют линиями. Если линия соединяет две сущности, сверху обозначают тип связи:
● 1:1 — «один-к-одному»;
● 1:N — «один-ко-многим»;
● M:N — «многие-ко-многим».
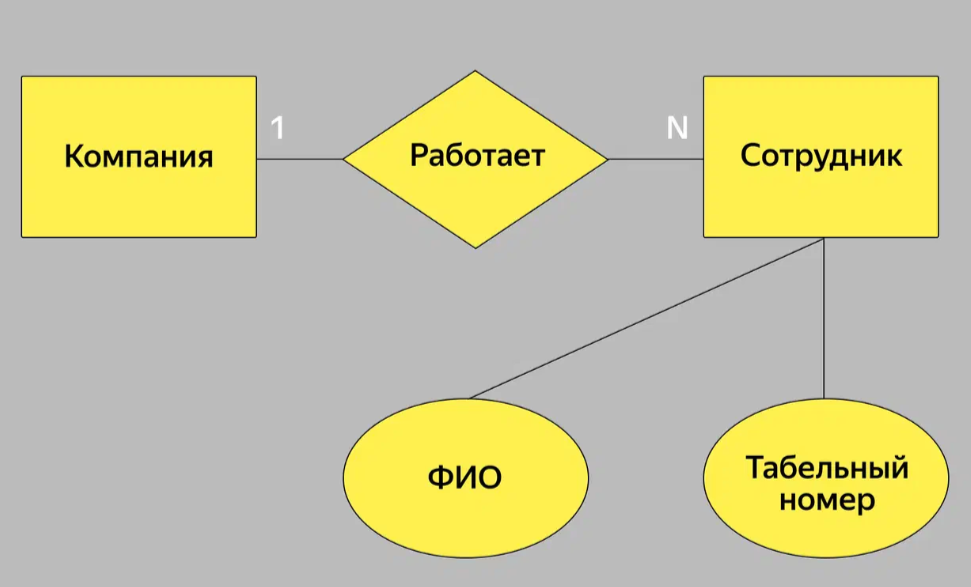
В нотации Мартина сущность также вписывают в прямоугольник, а атрибуты и связи обозначают по-другому:
● атрибуты перечисляют прямо под сущностью,
● связи рисуют разными соединительными линиями.
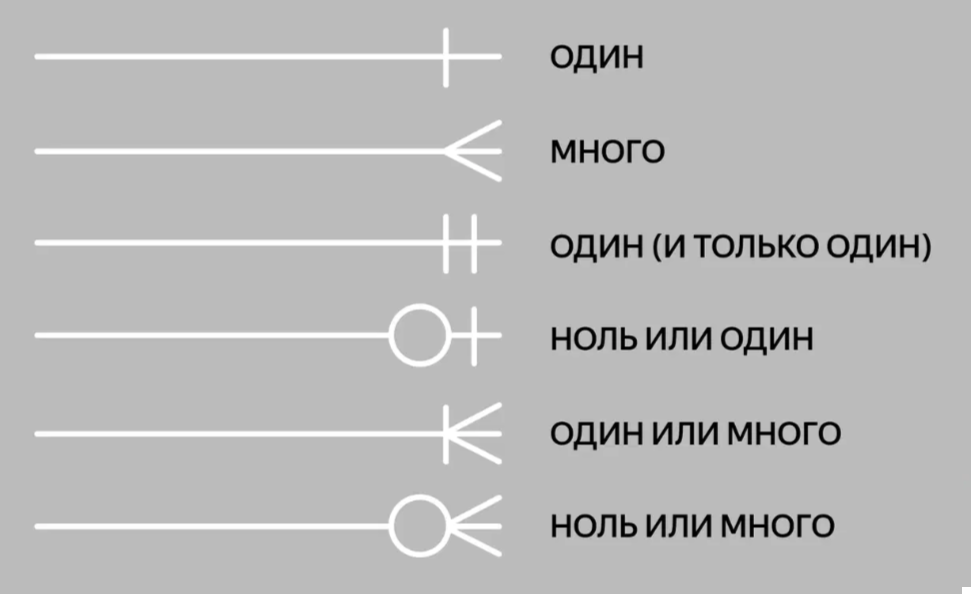
Для того чтобы изобразить три типа связи в нотации Мартина, можно использовать разные комбинации. Например, связь «многие-ко-многим» можно изобразить так: