Введение в БД. История развития БД#
В истории использования вычислительной техники (ВТ) можно выделить несколько направлений ее использования.
В первую очередь, средства ВТ предназначались для решения сложных математических задач, которые требуют большого количества вычислений. Такие задачи невозможно было вычислить «вручную» за разумное время. В этом плане, вычислительная техника значительно облегчила работу инженерам, научным работникам, и т.п. Для упрощения решения таких задач, появились:
- разнообразные численные методы решения задач;
- специализированные алгоритмические языки (например, Fortran).
Однако, со временем, использование персональных компьютеров для выполнения сложных научных расчетов было вытеснено другим направлением использования средств ВТ. Активное развитие получили такие направления вычислительной техники как:
- поддержка надежного сохранения информации;
- выполнение специфических преобразований информации для заданного приложения (программы);
- удобный и легкоусвояемый интерфейс пользователя;
- выполнение специфических (иногда несложных) вычислений для заданного приложения.
Развитие этого направления привело к тому, что в конце 60-х, в начале 70-х годов появилось специализированное программное обеспечение, которое получило название Система управления базами данных (DataBase Management System – DBMS).
Данные и информация#
Прежде чем мы углубимся в мир данных, давайте разберемся в разнице между данными и информацией.
ДАННЫЕ – ЭТО:
Представление информации в формализованном виде, пригодном для передачи, интерпретации или обработки людьми или компьютерами
ГОСТ 33707-2016 (ISO/IEC 2382:2015) «Информационные технологии. Словарь»
Любой вид знаний о предметах, фактах, понятиях и т. д. проблемной области, которыми обмениваются пользователи информационной системы
ГОСТ Р ИСО/МЭК 10746-2-2000 «Информационная технология. Взаимосвязь открытых систем. Управление данными и открытая распределенная обработка»
Для того чтобы информация стала данными, необходимо провести процесс формализации и кодирования. Давайте рассмотрим этот процесс более подробно:
- Сбор информации: Вначале нужно собрать информацию, которую вы хотите преобразовать в данные.
- Формализация: Формализация представляет собой процесс структурирования и организации информации в определенной форме. Например, если вы имеете текстовый документ, вы можете определить структуру, разбив его на заголовки, абзацы, списки и так далее. Формализация также может включать в себя определение формата данных, такого как дата или числа.
- Кодирование: После формализации информации, она должна быть закодирована в определенный формат, который компьютеры могут понимать. Это может включать в себя преобразование текста в байты с использованием определенной кодировки (например, UTF-8 для текста), или преобразование изображения в формат JPEG.
- Хранение данных: Закодированные данные сохраняются в определенном хранилище, таком как жесткий диск, база данных или облако.
Какое назначение систем управления базами данных (СУБД)? Что такое база данных?#
Основой любой современной информационной системы есть система управления базами данных.
Системы управления базами данных предназначены для обработки данных таким образом, чтобы ими можно было удобно оперировать.
Системы управления базами данных (СУБД) представляют собой программное обеспечение, созданное для эффективной работы с данными. Они играют фундаментальную роль в современной информационной инфраструктуре, обеспечивая хранение, организацию и доступ к данным различных организаций и систем.
База данных - это набор информации, структурированный и хранящийся в соответствии с определенными правилами. Она содержит данные, необходимые для деятельности организации: информацию о клиентах, продукции, финансах, а также связанные между собой данные, собранные и организованные для обеспечения оптимального доступа и использования.
СУБД позволяют не только хранить данные, но и управлять ими. Они обеспечивают создание, изменение и удаление информации, а также позволяют выполнять запросы к данным. Благодаря специализированным языкам, таким как SQL (Structured Query Language), пользователи могут эффективно извлекать нужную информацию из базы данных.
Модель данных, на которой основана база данных, определяет ее структуру и способы доступа к данным. Например, реляционные базы данных организованы в виде таблиц, где данные хранятся в строках и столбцах, обеспечивая легкий доступ и обработку. Однако есть и другие модели, такие как объектно-ориентированные базы данных или NoSQL-системы, каждая из которых имеет свои особенности и применения.
В классической теории баз данных, модель данных есть формальная теория представления и обработки данных в системе управления базами данных (СУБД), которая включает, по меньшей мере, три аспекта:
-
Структура данных. Этот аспект модели данных описывает, каким образом данные организованы внутри базы данных. Структура данных включает в себя методы и правила для описания типов данных (например, числовые, текстовые, даты и т.д.) и их логических структур. Эти структуры могут быть различными, от простых таблиц до сложных иерархий и сетей. Важно понимать, что именно структура данных определяет, как данные будут храниться, какие отношения между ними существуют, и как их можно будет извлечь для последующей обработки.
-
Средства манипуляции данными. Этот аспект охватывает методы и операции, которые можно выполнять с данными, хранящимися в базе данных. Манипуляции включают операции по добавлению, удалению, изменению и выборке данных. Для этого используются специальные языки, такие как SQL (Structured Query Language), которые позволяют разработчикам и пользователям базы данных эффективно взаимодействовать с данными. Возможность манипулировать данными является критически важной для выполнения повседневных задач, таких как обновление информации, проведение анализа данных и генерация отчетов.
-
Методы поддержания целостности. Этот аспект связан с обеспечением правильности и согласованности данных в базе данных. Методы поддержания целостности включают правила и механизмы, которые предотвращают нарушение данных, такие как ограничения целостности (например, уникальность ключей, целостность ссылок между таблицами). Целостность данных необходима для того, чтобы гарантировать, что все данные в базе данных остаются достоверными и непротиворечивыми, даже при выполнении множества операций или в случае возникновения ошибок.
## История развития баз данных#
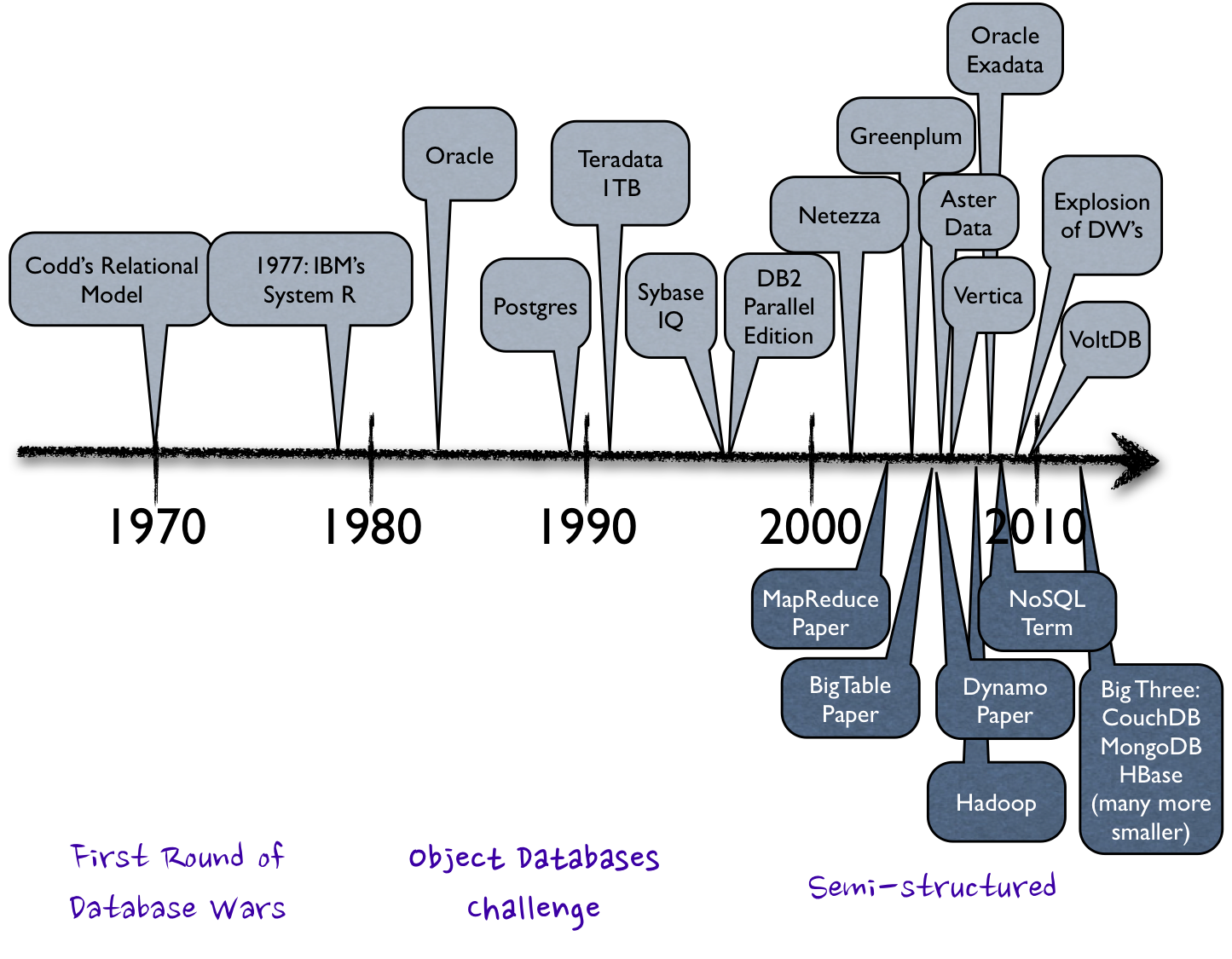
-
1955: Появление программного оборудования для обработки записей. Программное обеспечение этого времени поддерживало модель обработки записей на основе файлов. Для хранения данных использовались перфокарты.
-
1956: Компания IBM представила дисководы жестких магнитных дисков для хранения данных, что стало новым способом хранения информации.
-
1959: В сообществе баз данных "COBOL" была проработана концепция схем баз данных и концепция независимости данных.
-
1961-1963: Integrated Data Store (IDS), первая система управления базами данных, начало сетевой и навигационной моделей данных, разработанная Чарльзом Бахманом.
-
1964: На симпозиумах, организованных компанией SDC, введен термин "база данных".
-
1970: Эдгар Ф. Кодд опубликовал работу по реляционной модели данных, что считается первой работой по этой модели.
-
1971: CODASYL Data Model, стандарт сетевой модели данных, был разработан организацией CODASYL.
-
1973: System R компании IBM стала первой системой управления реляционными базами данных. Чарльз Бахман получил Тьюринговскую премию за руководство работой Data Base Task Group (DBTG), разработавшей стандартный язык описания данных и манипулирования данными.
-
1976: Питер Чен предложил модель "Сущность-связь" (ERD, ERM) - графическую модель данных.
-
1979: Первая СУБД, поддерживающая язык SQL - Oracle V2 для машин VAX от компании Relational Software Inc.
-
1981: Эдгар Ф. Кодд получил премию Тьюринга за свой вклад в теорию и практику.
-
1986: ANSI принял первый стандарт языка SQL.
-
1997: Стандарт объектных баз данных ODMG 2.0 был представлен.
-
2002: Журнал Forbes поместил реляционную модель данных в список важнейших инноваций последних 85 лет.
Классификация БД#
Классификация моделей данных включает различные подходы к организации и хранению информации.
Иерархическая модель#
Иерархическая модель данных — это модель данных, где используется представление базы данных в виде древовидной (иерархической) структуры, состоящей из объектов (данных) различных уровней.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможна ситуация, когда объект-предок имеет несколько потомков, тогда как у объекта-потомка обязателен только один предок. Объекты, имеющие общего предка, называются близнецами (в программировании применительно к структуре данных дерево устоялось название братья).
Базы данных с иерархической моделью одни из самых старых, и стали первыми системами управления базами данных для мейнфреймов. Разрабатывались в 1950-х и 1960-х, например, Information Management System (IMS) фирмы IBM.
Компоненты иерархической модели
-
Поле данных (атрибут) - минимальная неделимая, уникально адресуемая единица хранения данных
-
Сегмент данных (запись/record/экземпляр данных) - совокупность полей данных, имеющая уникальную идентификацию (сущность в модели ER).
-
Экземпляр сегмента — конкретные значения полей
-
Дерево — совокупность сегментов, связанных с помощью связи родитель-потомок
В иерархической модели базы данных пользователи могут выполнять несколько ключевых операций с данными. Эти операции позволяют управлять структурами данных, поддерживать актуальность информации и извлекать нужные данные для дальнейшего использования. Рассмотрим эти операции подробнее:
-
Добавление в базу новой записи. В иерархической базе данных можно добавлять новые записи в определённые места структуры, обычно в качестве дочерних элементов существующих записей. При добавлении важно соблюдать иерархические правила, чтобы сохранить правильные связи между родительскими и дочерними узлами.
-
Изменение значений атрибутов (кроме ключевых) отдельной записи. Эта операция позволяет пользователю обновлять информацию, содержащуюся в атрибутах записи. Важно отметить, что изменения могут касаться только некритичных атрибутов, так как изменение ключевых атрибутов (которые определяют уникальность записи) может нарушить целостность структуры базы данных.
-
Удаление записи со всеми дочерними записями. В иерархической модели удаление записи автоматически приводит к удалению всех записей, которые связаны с ней как дочерние. Это логично, так как в иерархической структуре каждая запись может зависеть от своей родительской, и удаление родителя требует удаления всех его зависимых записей.
-
Извлечение записи. Эта операция позволяет выбрать и извлечь конкретную запись из базы данных для просмотра или дальнейшей обработки. Извлечение записи важно для выполнения поиска, анализа данных или подготовки информации для отчётов.
Сценарии использования операторов#
В иерархической базе данных манипулирование данными осуществляется с помощью различных операторов, которые позволяют выполнять широкий спектр операций над структурой и содержимым базы данных. Рассмотрим примеры типичных операторов манипулирования данными в контексте иерархической модели.
-
Найти указанное дерево в базе данных. Этот оператор позволяет пользователю идентифицировать и получить доступ к конкретному дереву в иерархической базе данных. Дерево в данном контексте представляет собой иерархическую структуру, состоящую из связанных между собой записей, где каждая запись может иметь одну или несколько дочерних записей.
-
Перейти от одного дерева к другому. В базе данных может существовать несколько деревьев, и этот оператор позволяет перемещаться между ними. Это важно, когда необходимо работать с различными иерархиями, организованными по разным принципам.
-
Найти экземпляр записи, удовлетворяющий условию поиска. С помощью этого оператора можно найти конкретную запись, которая соответствует заданным критериям. Это может быть, например, поиск всех записей с определённым значением поля.
-
Перейти от одной записи к другой внутри дерева. Этот оператор позволяет перемещаться между записями в пределах одного дерева. Например, можно перейти от родительской записи к дочерней или наоборот, что особенно полезно для навигации и поиска в сложных иерархиях.
-
Перейти от одной записи к другой в порядке обхода иерархии. Этот оператор используется для последовательного обхода всех записей в дереве в определённом порядке. Обход может быть выполнен, например, в порядке сверху вниз или снизу вверх, что важно для задач, требующих полного просмотра дерева.
-
Вставить новый экземпляр записи в указанную позицию. Этот оператор позволяет добавить новую запись в определённое место в иерархии. Например, можно добавить дочернюю запись к существующему родителю или вставить запись в определённую ветвь дерева.
-
Обновить текущий экземпляр записи. Этот оператор используется для изменения данных в текущей записи. Это важно, когда необходимо внести изменения в уже существующую запись без необходимости создавать новую.
-
Удалить текущий экземпляр записи. Оператор удаления позволяет удалить выбранную запись из базы данных. Важно учитывать, что в иерархических базах данных удаление записи может также затронуть все дочерние записи, что требует особой осторожности.
-
Найти и удержать для дальнейшего изменения единственный экземпляр записи, удовлетворяющий условию поиска. Этот оператор позволяет найти и зафиксировать запись, которая соответствует определённым критериям поиска, для её последующего изменения.
-
Найти и удержать для дальнейшего изменения следующий экземпляр записи с теми же условиями поиска. После того как был найден первый экземпляр, соответствующий условиям поиска, этот оператор позволяет найти следующий такой экземпляр, что удобно для обработки нескольких записей с одинаковыми характеристиками.
-
Найти и удержать для дальнейшего изменения следующий экземпляр для того же родителя. Этот оператор применяется, когда нужно найти и зафиксировать для изменения следующую запись в рамках одного родительского узла, что полезно при последовательной обработке записей, связанных с одним родителем.
Иерархические структуры в современности#
В реальной жизни мы часто сталкиваемся со сложными связями между объектами, которые могут быть описаны как отношения типа «много-ко-многим». Например, один студент может посещать несколько курсов, и каждый курс может быть посещён множеством студентов. В иерархической модели баз данных такие связи отразить сложно, так как она предполагает строгое подчинение, где каждый элемент имеет одного родителя и может иметь множество дочерних элементов. В результате для отображения связей «много-ко-многим» в иерархической модели часто требуется дублирование данных, что приводит к избыточности, усложняет управление данными и увеличивает риск ошибок. Именно по этой причине иерархическая модель считается неудобной и устаревшей для многих задач.
В современном мире иерархические базы данных редко используются для новых проектов. Их популярность существенно снизилась с появлением более гибких и мощных реляционных моделей, которые лучше подходят для отображения сложных взаимосвязей между данными. Тем не менее, в некоторых случаях старые иерархические базы данных продолжают эксплуатироваться. Это происходит тогда, когда базы содержат огромные объёмы критически важной информации, миграция которой в новую систему может быть затруднена или невозможна. В таких ситуациях специалисты вынуждены работать с существующими иерархическими системами, параллельно разрабатывая методы и инструменты для постепенного переноса данных в реляционные базы.
Однако, несмотря на свои ограничения, иерархическая модель данных не потеряла своей актуальности в определённых узкоспециализированных задачах. Например, она может быть полезна в ситуациях, где связи между данными строго однонаправленные, типа «один-ко-многим». В таких сценариях иерархическая структура оказывается достаточно простой и эффективной. Один из самых знакомых примеров использования иерархической модели — это система файлов и папок на персональном компьютере. Все пользователи ПК сталкиваются с иерархической организацией данных, когда работают с вложенными папками и файлами.
Ещё один пример использования иерархической модели — это реестр операционной системы Windows. Реестр представляет собой иерархическую базу данных, которая содержит все настройки и параметры операционной системы. Пользователи могут просматривать и даже редактировать содержимое реестра с помощью встроенной программы regedit. Для доступа к реестру нужно в меню «Пуск» выбрать пункт «Выполнить» и ввести команду regedit. Откроется окно с иерархическим деревом реестра, в котором можно увидеть, как организованы и хранится информация о состоянии системы.
Таким образом, несмотря на ограниченность иерархической модели, она продолжает находить применение в тех областях, где её структура оказывается полезной и эффективной.
Проблемы:
- Требуется много памяти для хранения (производительность)
- Сложно контролировать целостность данных
- Дублирование данных
- Скорость операций записи
- Огромные трудности при реорганизации структуры (иерархии)
- Невозможна связь Many-to-many
Сетевая модель#
Можно ссылаться много раз на один и тот же объект
Разделяем хранение связей от хранения данных
Агрегаты — так называют сегменты
Сетевая модель данных состоит из нескольких основных компонентов:
- Сегменты
Сегменты являются основными элементами структуры сетевой модели данных. Каждый сегмент представляет собой набор связанных записей, которые могут быть связаны с другими сегментами. Каждый сегмент имеет свой уникальный идентификатор, который позволяет обращаться к нему и работать с его содержимым.
- Записи
Записи представляют собой набор полей, которые содержат данные. Каждая запись имеет свой уникальный идентификатор, который позволяет обращаться к ней и работать с ее содержимым. Записи могут быть связаны с другими записями, что обеспечивает гибкость в организации данных.
- Сети
Сети представляют собой связи между сегментами и записями. Они определяют отношения между данными и позволяют обращаться к связанным данным. Сети могут быть однонаправленными или двунаправленными, что позволяет определить направление доступа к данным.
- Владение
Владение определяет отношение между сегментами и записями. Сегмент, который владеет записью, может иметь доступ к ее содержимому и изменять его. Владение может быть однонаправленным или двунаправленным, что позволяет определить, какие сегменты могут владеть записями.
- Связи
Связи определяют отношения между сегментами и записями. Они позволяют связывать данные между собой и обеспечивают гибкость в организации данных. Связи могут быть однозначными или многозначными, что позволяет определить, сколько записей может быть связано с одним сегментом.
Плюсы:
- Обеспечивает атрибутивную целостность
Проблемы:
- Храним сущности и связи отдельно
- Появилась проблема ссылочной целостности
Сценарии использования опреаторов#
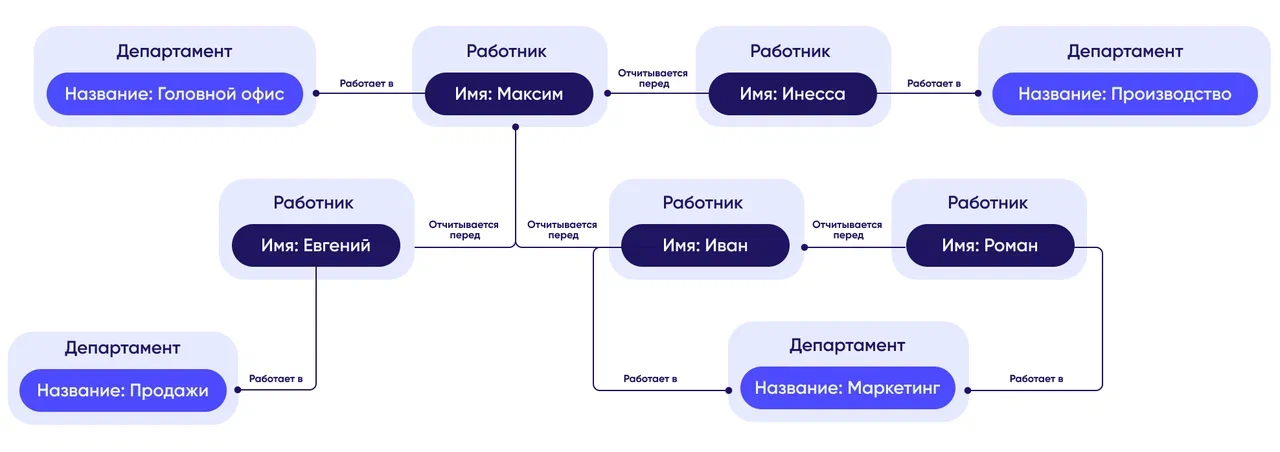
Пример : Сетевая модель для финансового отдела.
В сетевой модели данных, представленной на изображении, можно увидеть, как организованы отношения между различными типами записей, связанными с процессом продаж в компании. Здесь представлены следующие типы записей: SALES-MAN (продавец), CUSTOMER (заказчик), PRODUCT (продукт), INVOICE (счёт), PAYMENT (платёж) и INVOICE-LINE (строка счета).
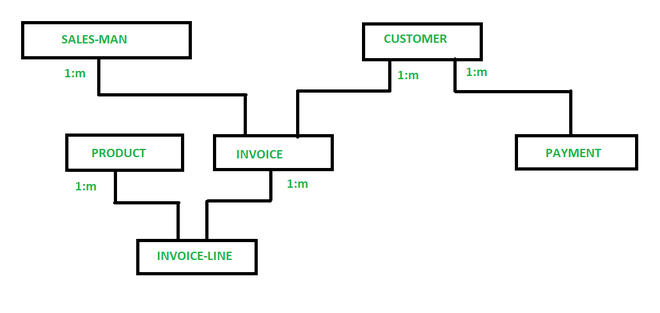
- INVOICE-LINE (строка счета) принадлежит одновременно двум типам записей — PRODUCT (продукт) и INVOICE (счёт). Это означает, что каждая строка в счёте содержит информацию о конкретном продукте и привязана к определённому счёту.
- INVOICE (счёт) связан с двумя владельцами: SALES-MAN (продавец) и CUSTOMER (заказчик). Это подчёркивает, что каждый счёт относится как к конкретному продавцу, так и к конкретному заказчику, обеспечивая возможность отслеживания ответственности за продажу и её адресата.
Графовые модели данных#
Графовая база данных — разновидность баз данных с реализацией сетевой модели в виде графа и его обобщений. Графовая СУБД — система управления графовыми базами данных.
Графовые базы данных применяются для моделирования социальных графов (социальных сетей), в биоинформатике, а также для семантической паутины. Для задач с естественной графовой структурой данных графовые СУБД могут существенно превосходить реляционные по производительности, а также иметь преимущества в наглядности представления и простоте внесения изменений в схему базы данных
Amazon Neptune — публично-облачная графовая СУБД в составе Amazon Web Services. Поддерживает графовые модели RDF и LPG и, соответственно, языки запросов SPARQL и Gremlin.
Выпущена в тестовом режиме 29 ноября 2017 года, в коммерческую эксплуатацию введена 30 мая 2018 года.
Графовые базы уже нашли применение в:
- Социальных сетях
- Системах рекомендаций (с этим товаром часто покупают…)
- Обработка пользовательских данных, корреляция данных из разных источников (информационный след в сети)
Если в вашем приложении планируется много сущностей и связей многие-ко-многим, то это один из признаков, что предпочтительней выбрать графовую СУБД (утверждение Martin Kleppmann’а в книге “Designing Data Intensive Applications”).
А если у вас уже есть приложение с множеством связей, и обход этих связей занимает много времени и ресурсов — стоит присмотреться в сторону графов, т.к. обход связей в них практически ничего не стоит.
Сценарии использования опреаторов#
Одно из применений кграфовых БД - это использование их в семантических базах данных.
Семантические базы данных представляют собой специально организованные хранилища данных, где информация не только описывает факты, но и содержит семантические связи между ними. В отличие от традиционных баз данных, которые ограничиваются хранением и извлечением данных, семантические базы данных исследуют глубинные связи и значения, лежащие в основе этих данных.
Основными строительными блоками семантических баз данных являются
- RDF (Resource Description Framework) – формальный язык для описания ресурсов и их отношений,
- SPARQL – язык запросов к RDF данным, и Linked Data – концепция объединения данных разных источников через общие семантические структуры.
Ключевой концепцией RDF является представление данных в виде троек (субъект, предикат, объект), которые позволяют описывать отношения между ресурсами. Рассмотрим более подробно каждый из элементов тройки:
Субъект (Subject): Это основной объект описания, о котором мы хотим сообщить информацию. Субъект может быть чем угодно – начиная от реальных объектов, таких как конкретные люди или места, и заканчивая абстрактными концепциями или даже другими тройками. Субъект идентифицируется с помощью URI, который уникально идентифицирует данный ресурс.
Предикат (Predicate): Предикат представляет отношение или свойство, которое связывает субъект с объектом. Он описывает, какая именно информация предоставляется о субъекте. Примеры предикатов могут включать "имеет возраст", "является автором" или "расположен в". Подобно субъектам, предикаты также идентифицируются с помощью URI.
Объект (Object): Объект – это значение или ресурс, связанный с субъектом через предикат. Объект может быть конкретным значением, таким как строка или число, или другим ресурсом, который также идентифицируется с помощью URI. Например, в тройке "Анна имеет возраст 25", "25" – это объект.
Пример тройки:
Субъект: "Анна"
Предикат: "имеет возраст"
Объект: "25"
Эта тройка описывает, что субъект "Анна" имеет свойство "возраст" со значением "25".
Примеры публичных проектов
RDF-базы данных:
1) Dbpedia - извлечение структурированной информации из данных Wikipedia
2) Geonames – база географических объектов
3) DBLP – база данных публикаций по информатике
4) PubMed – база данных публикаций по медицине
5) UniProt – база данных белков
6) OpenCyc – объёмная онтологическая база данных
7) LOD – технология связанных открытых данных
• Словари
1) Dublin Core (DC) – атрибуты библиотечных метаданных
2) Friend-of-a-Friend (FOAF) – словарь описания людей, их отношений и
деятельности
3) Semantically-Interlinked Online Communities (SIOC) – словарь онлайн-сообществ
1) Description of a Project (DOAP) – словарь для описания проектов
2) Simple Knowledge Organization System (SKOS) –словарь для представления
стандартизованных таксономий
3) Creative Commons (CC) – словарь для описания лицензий
Объектные или объектно-ориентированные модели данных#
Основаны на представлении данных в виде объектов, которые могут содержать как сами данные, так и методы для их обработки. Эта модель позволяет более естественно отображать реальные объекты и их взаимосвязи.
Объектные или объектно-ориентированные модели данных основаны на представлении данных в виде объектов, объединяющих в себе как сами данные, так и методы для их обработки. Это позволяет более естественно описывать реальные объекты и связи между ними, а также обрабатывать их с помощью методов и операций, применяемых к объектам.
Подобно иерархической модели данных, объектные модели представляют связи между объектами, однако вместо четкой иерархии они уделяют внимание объектам и их взаимосвязям. Объекты могут содержать другие объекты в качестве своих частей, и каждый объект может иметь свои уникальные свойства и методы.
Важным аспектом объектно-ориентированных моделей данных является возможность создания и использования классов объектов, что облегчает повторное использование кода и структурирует данные в единые блоки.
Компоненты объектно-ориентированной модели
- Объекты: Это конкретные экземпляры классов, обладающие конкретными данными и функциональностью, определенной в классе.
- Классы объектов: Это шаблоны или описания объектов определенного типа, который определяет их структуру, свойства и методы.
- Свойства объектов: Это характеристики или атрибуты, которые описывают объекты, например, имя, возраст, размер и т. д.
- Методы объектов: Это функции или действия, которые могут быть выполнены объектом. Они определяют поведение объекта и могут выполнять операции с данными объекта.
- Связи между объектами: Это отношения и взаимодействия между различными объектами, которые могут быть установлены на уровне классов и объектов.
- Наследование: Это концепция, когда один класс может наследовать свойства и методы другого класса, что позволяет унаследованным объектам использовать функциональность родительского класса.
Сценарии использования операторов#
ODMG (Object Data Management Group) - консорциум поставщиков ООБД и других заинтересованных организаций, созданный в 1991 г. Его задачей является разработка стандарта на хранение объектов в базах даннных. В настоящее время опубликован вторая версия стандарта, которую так и называют ODMG 2.0. Рассмотрим кратко основные положения этого документа.
Стандарт на хранение объектов ODMG 2.0 разработан на основе трех существующих стандартов: управление базами данных (SQL), объекты (стандарты OMG - Object Management Group) и стандарты на объектно-ориентированные языки программирования (C++, Smalltalk, Java).
ODMG добавляет возможности взаимодействия с базами данных в объектно-ориентированные языки программирования: определяются средства долговременного хранения объектов и расширяется семантика языка, вносятся операторы управления данными. Стандарт состоит из нескольких частей:
Объектная модель - унифицированная основа всего стандарта. Она расширяет объектную модель консорциума OMG (см. параграф 6.3.1) за счет введения таких свойств как связи и транзакции для обеспечения функциональности, требуемой при взаимодействии с базами данных. Ключевые концепции объекной модели ODMG:
наделение объектов такими свойствами как атрибуты и связи
1. методы объектов (поведение)
- множественное наследование
- идентификаторы объектов (ключи)
- определение таких совокупностей объектов как списки, наборы, массивы и т.д.
- блокировка объектов и изоляция доступа
- операции над базой данных
2. Язык описания объектов (ODL - Object Defifnition Language) - средство определения схемы базы данных (по аналогии с DDL в реляционных СУБД). ODL является расширением IDL (Interface Definition Language - язык описания интерфейсов) модели OMG и предоставляет средства для определения объектных типов, их атрибутов, связей и методов. ODL создает слой абстрактных описаний так, что схема базы данных становится независима как от языка программирования, так и от СУБД. ODL рассматривает только описание объектных типов данных, не вдаваясь в детали реализации их методов. Это позволяет переносить схему БД между различными ODMG-совместимыми СУБД и языками программирования, а также транслировать ее в другие DDL.
3. Язык объектных запросов (OQL - Object Query Language) - SQL - подобный декларативный язык, который предоставляет эффективные средства для извлечения объектов из базы данных, включая высокоуровневые примитивы для наборов объектов и объектных структур. Синтаксис опретора SELECT, определенный SQL-92, является подмножеством OQL, это гарантирует, что SELECT-утверждения, выполняемые над реляционными таблицами, сохранят работоспособность и с наборами объектов ODMG. OQL-запросы могут вызываться из ОО-языка, точно также из OQL-запросов могут делаться обращения к процедурам, написанным на OO-языке. OQL предоставляет средства обеспечения целостности объектов (вызов объектных методов и использование собственных операторов изменения данных).
4. Связывание с ОО-языками. Стандарт связывания с C++, Smalltalk и Java определяет Object Manipulation Language (OML) - язык манипулирования объектами, который расширяет базовые ОО-языки средствами манипулирования и хранения объектов. Также включаются OQL, средства навигации и поддержка транзакций. Каждый ОО-язык имеет свой собственный OML, поэтому разработчик остается в одной языковой среде, ему нет необходимости разделять средства программмирования и доступа к данным.
При подобном подходе можно выделить следующие ограничения реляционной технологии:
-
Неестественное представление данных со сложной структурой. Реляционная модель данных не допускает естественного моделирования данных со сложной структурой, поскольку в ее рамках возможно моделирование лишь с помощью плоских отношеиий (таблиц). Так как все отношения принадлежат одному уровню, многие значимые связи между данными либо теряются, либо их поддержку приходится осуществлять в рамках конкретной прикладной программы.
-
Затруднительно должным образом смоделировать свойства данных. Чтобы естественно смоделировать структуру сложных данных, пользователь должен иметь возможность определять свои типы данных, не ограничиваясь типами данных, предоставляемыми определенной СУБД.
-
Реляционная модель данных не позволяет определить набор операций, связанных с данными определенного типа, что часто является естественным требованием при моделировании данных со сложной структурой. Операции приходится задавать в конкретном приложении.
-
Реляционная модель не позволяет рассматривать данные послойно, на различных уровнях абстракции, при необходимости отвлекаясь от ненужных деталей.
-
Усложненный доступ к базе данных. Интерфейс между языком программирования и языком баз данных обычно усложнен, поскольку каждый язык имеет свой набор типов и свою модель вычислений. Организуя обращение к базе данных из прикладной программы, написанной, например, на C++, приходится подвергать данные структурной трансформации при передаче их из/в базу данных
Примеры#
- федеральная авиационная администрация (Federal Aviation Administration,
FAA) применяет систему, созданную на основе объектно-ориентированной базы данных, для моделирования пассажиро- и грузопотоков. Поскольку
в такой базе процедуры хранятся вместе с данными, моделирование сложных взаимосвязей между объектами оказывается проще, чем при использовании реляционной базы; - Французский национальный центр космических исследований (CNES): Применяет ООБД в авиакосмической промышленности для разработки мультимедийной базы данных, помогающей моделировать интегрированные системы, необходимые в проектировании космических аппаратов.
- французская электрическая компания Electricite de France пользуется объектно-ориентированной базой для управления нагрузкой на линии электропередачи. База данных способна нарисовать карту линий, расположенных в области ответственности обслуживающего предприятия. ООБД также помогает определить, какое оборудование необходимо для прокладки новой линии.
Документ-ориентированные#
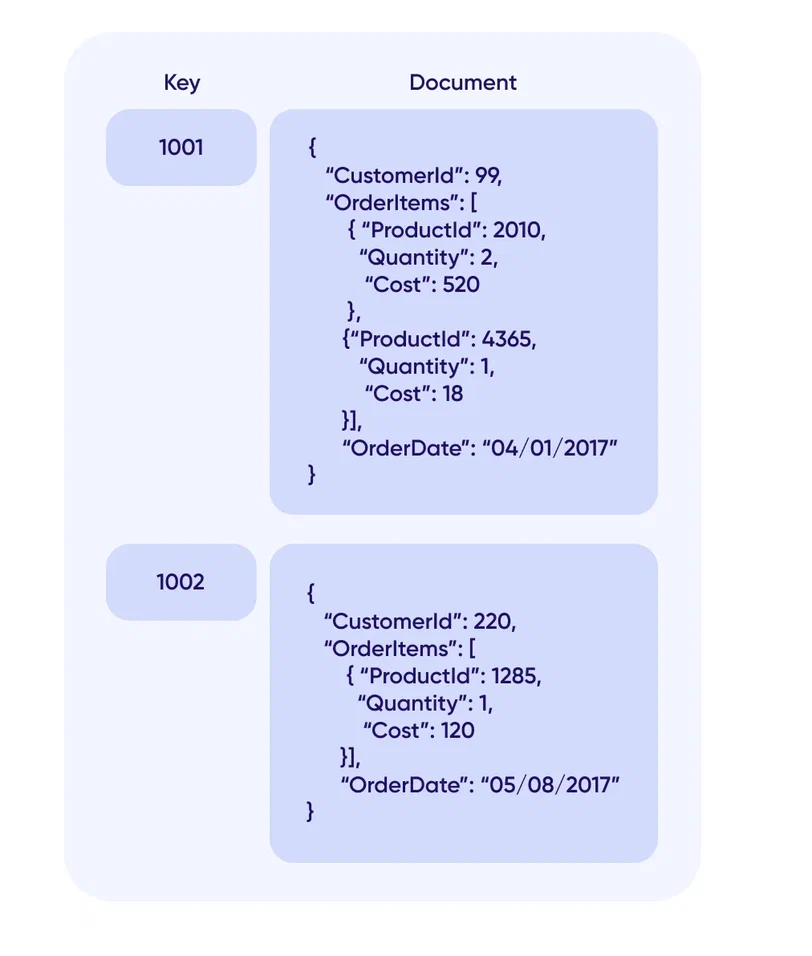
Документоориентированные базы данных – это тип баз данных, направленный на хранение и запрос данных в виде документов, подобном JSON.
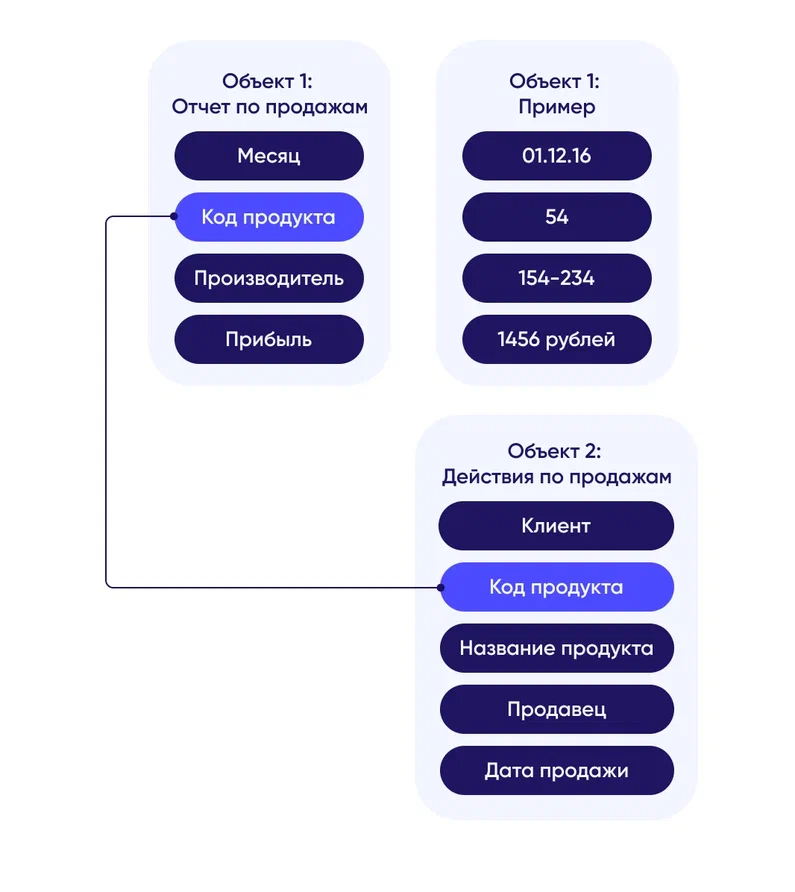
Документ-ориентированная модель специально предназначенная для хранения иерархических структур данных – документов. Документ – набор атрибутов (ключ и соответствующее ему значение. Документ может быть вложен в документ
- Представление данных – JSON или XML формат.
- Документ-ориентированные базы данных применяются в системах управления содержимым, издательском деле, документальном поиске и т.п.

Такой тип БД управляет так называемым документом: набором значений и данных объекта. Важно, что один документ может содержать сведения, которые в реляционной СУБД обычно распределяются по нескольким реляционным таблицам. Вдобавок документоориентированные БД не требуют, чтобы все документы имели одинаковую структуру. Доступ к документам дается через ключ — уникальный идентификатор документа.
Примеры СУБД: CouchDB, Couchbase, MarkLogic, MongoDB, eXist, Berkeley DB
- MongoDB в компании eBay: eBay использует MongoDB для хранения и обработки данных о пользователях и транзакциях. Это позволяет компании эффективно управлять большими объемами данных и обеспечивать высокую производительность при поиске и обработке информации.
- CouchDB в BBC: BBC использует CouchDB для управления данными о своих мультимедийных контентах. CouchDB позволяет хранить данные в формате JSON, что упрощает интеграцию с различными системами и улучшает производительность при доступе к данным.
- Firebase Firestore в компании The New York Times: The New York Times использует Firebase Firestore для управления данными о пользователях и контенте на своем веб-сайте. Это позволяет компании быстро и эффективно обрабатывать запросы пользователей и обеспечивать высокую доступность данных.
- Amazon DocumentDB в компании Capital One: Capital One использует Amazon DocumentDB для управления данными о клиентах и транзакциях. Это позволяет компании обеспечивать высокую производительность и надежность при обработке финансовых данных.
Реляционные модели данных#
Одна из самых широко используемых моделей данных. Здесь данные организованы в виде таблиц, где строки представляют собой отдельные записи, а столбцы - атрибуты или характеристики этих записей.
Реляционная модель данных (РМД) — логическая модель данных, прикладная теория построения баз данных, которая является приложением к задачам обработки данных таких разделов математики, как теория множеств и логика первого порядка.
Реляционная модель данных включает следующие компоненты:
1. Структурный аспект (составляющая) — данные в базе данных представляют собой набор отношений.
2. Аспект (составляющая) целостности — отношения отвечают определённым условиям целостности. РМД поддерживает декларативные ограничения целостности уровня домена (типа данных), уровня отношения и уровня базы данных.
3. Аспект (составляющая) обработки (манипулирования) — РМД поддерживает операторы манипулирования отношениями (реляционная алгебра, реляционное исчисление).
Примеры: MySQL, Oracle DB.
Таблица сравнения основных моделей#
Таблица сравнения объектно-ориентированной модели данных
| Аспект | Объектно-ориентированная модель данных | Реляционная модель данных | Иерархическая модель данных |
|---|---|---|---|
| Определение | Модель данных, основанная на концепции объектов, их свойств и взаимодействий | Модель данных, основанная на таблицах, связанных ключами | Модель данных, основанная на иерархической структуре данных |
| Принципы | Инкапсуляция, наследование, полиморфизм | Нормализация, целостность данных, операции JOIN | Структура дерева, родительские и дочерние элементы |
| Основные понятия | Классы, объекты, свойства, методы | Таблицы, столбцы, строки, ключи | Узлы, родительские и дочерние элементы, связи |
| Преимущества | Гибкость, повторное использование кода, модульность | Простота использования, эффективность запросов | Поддержка иерархической структуры данных, быстрый доступ к связанным элементам |
| Примеры использования | Разработка приложений, моделирование реального мира | Управление данными, хранение информации | Системы управления базами данных, файловые системы |
Каждая из этих моделей имеет свои преимущества и недостатки, а выбор конкретной модели зависит от требований проекта и особенностей данных, которые необходимо хранить и обрабатывать.
Главные концепции реляционных баз данных#
Эти модели характеризуются простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных.
Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
каждый элемент таблицы — один элемент данных
- все ячейки в столбце таблицы однородные, то есть все элементы в столбце имеют одинаковый тип (числовой, символьный и т. д.)
- каждый столбец имеет уникальное имя
- одинаковые строки в таблице отсутствуют
- порядок следования строк и столбцов может быть произвольным
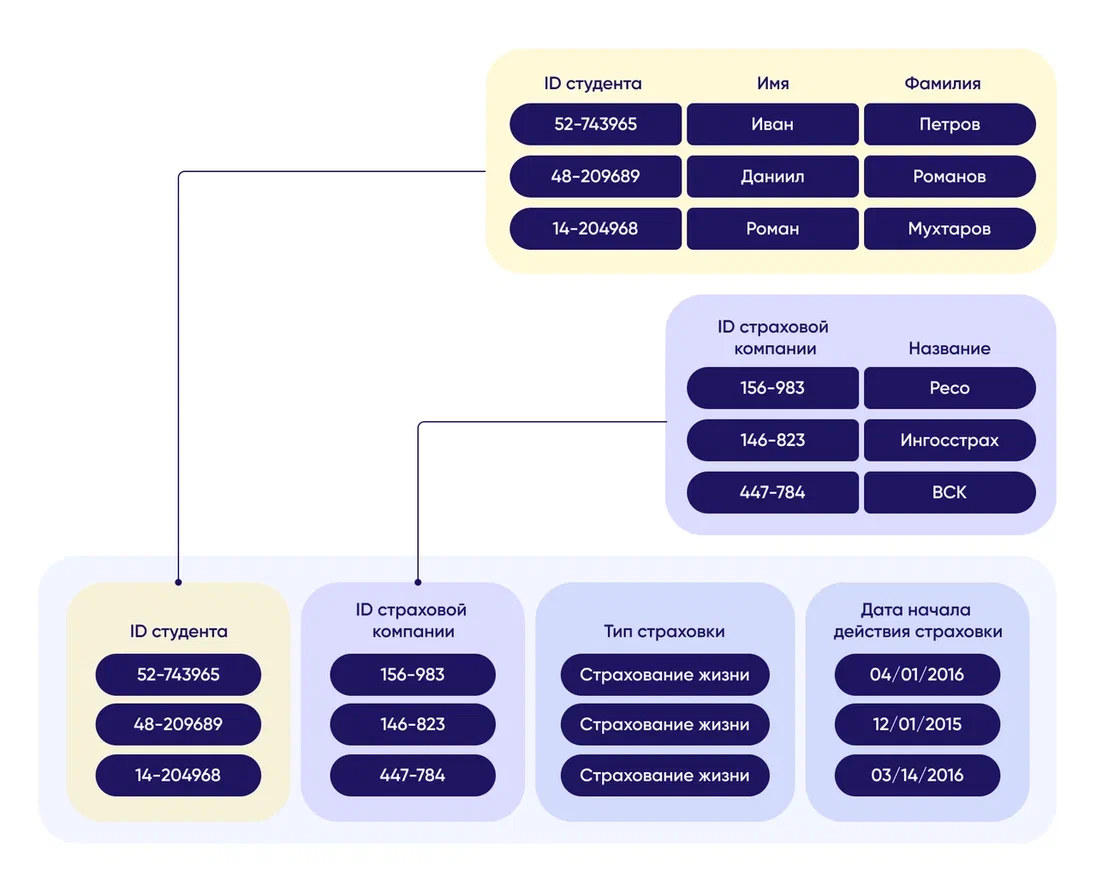
Отношение — фундаментальное понятие реляционной модели данных. По этой причине модель и называется реляционной (от английского relation — отношение).
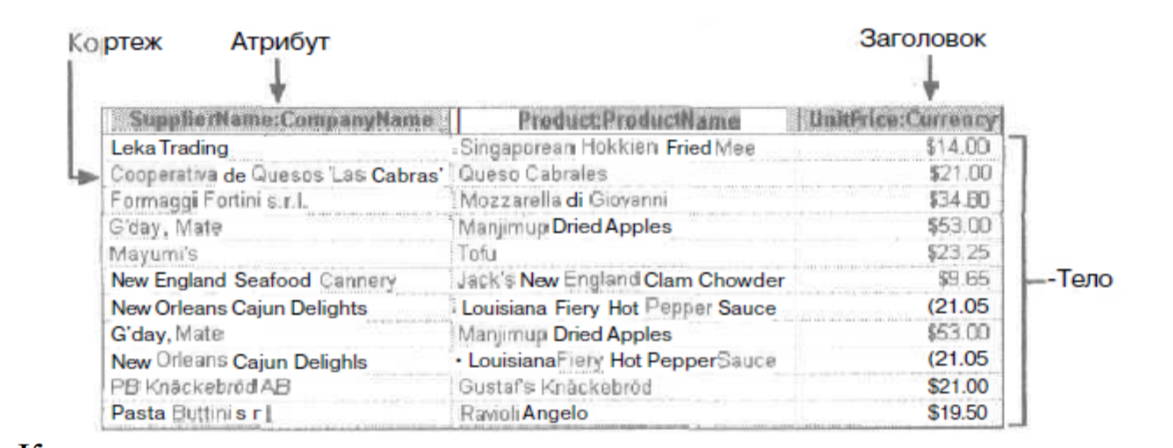
Отношение имеет простую графическую интерпретацию, оно может быть представлено в виде таблицы, столбцы (поля, атрибуты) которой соответствуют вхождениям доменов в отношение, а строки (записи) — наборам из n значений, взятых из исходных доменов. Число строк (кортежей) n, называют кардинальным числом отношения (кардинальностью),или мощностью отношения.
Отношением называется вся структура в целом. Каждая строка, содержащая данные,
является кортежем. Строго говоря, каждая строка является n-кортежем. Число кортежей в
отношении определяет мощность отношения. В примере мощность отношения равна 11.
Каждый столбец отношения называется атрибутом . Число атрибутов в отношении определяет
размерность этого отношения, в примере она равняется трем.
Каждое отношение можно разделить на две части — заголовок и тело.
Телоотношения состоит из кортежей, в то время как заголовок не имеет более мелких
компонентов структуры. Название каждого из атрибутов состоит из двух терминов,
разделенных двоеточием (например, UnitPrice:Currency). Первая часть названия —
непосредственно имя атрибута, вторая — имя домена. Домен атрибута — это вид данных,
которые представляет данный атрибут (в приведенном примере — валюта).
Понятие домен не эквивалентно понятию ≪тип данных≫.
Тело отношения состоит из неупорядоченного набора кортежей (число кортежей
может быть любым, от 0 и более).
Во-первых, отношение не упорядочено. Понятие ≪номер строки≫ не применимо к отношению. Для отношений не существует никакого внутреннего
порядка.
Во-вторых, отношение может иметь нулевое число кортежей (это так называемое
пустое отношение, которое, тем не менее, является отношением). В третьих, отношение
представляет собой набор. Элементы в этом наборе по определению уникально
идентифицируемые. Поэтому чтобы таблица являлась отношением, каждая ее строка должна
быть уникально идентифицируемой, записи в ней не должны повторяться.
Такая таблица обладает рядом свойств:
- В таблице нет двух одинаковых строк.
- Таблица имеет столбцы, соответствующие атрибутам отношения.
- Каждый атрибут в отношении имеет уникальное имя.
- Порядок строк в таблице произвольный.
- Под атрибутом здесь понимается вхождение домена в отношение. Строки отношения называются кортежами.
Далее следует формализованное определение введённых понятий.
- Заголовок Hr (или схема) отношения r — конечное множество упорядоченных пар вида
- Кортеж tr, соответствующий заголовку Hr — множество упорядоченных триплетов вида
- Тело Br отношения — неупорядоченное множество различных кортежей tr.
- Значением Vr отношения r называется пара множеств Hr и Br.
Полезно также понятие первичного ключа — это такой набор атрибутов, который однозначно определяет кортеж и минимален среди всех своих подмножеств (то есть нельзя убрать ни один из атрибутов). При добавлении новых записей первичный ключ обязан оставаться первичным ключом (например, неверным будет использование в качестве первичного ключа набора Имя + Отчество + Фамилия сотрудника, даже если на момент создания таблицы полных тёзок среди заносимых в неё людей не было).
Домен#
Домен определяет ≪вид≫данных, которые представляет данный атрибут. Если дать
более четкое определение, то домен — это набор всех допустимых значений, которые может
содержать данный атрибут.
Понятие ≪домен≫ часто путают с понятием ≪тип данных≫. Необходимо четко
различать эти два понятия. Тип данных — это физическая концепция, а домен — логическая.
Например, ≪целое число≫— это тип данных, а ≪возраст≫— это домен.
Понятие домена намного шире понятия ≪тип данных≫, поскольку определение
домена включает в себя более детальное описание допустимых значений данных.
Домен — это тип данных и логические правила, определенные для данной
сущности, но логические правила — это один из механизмов реализации целостности
данных, а отнюдь не элемент их описания.
Самые популярные СУБД#
Российский рынок систем управления базами данных (СУБД) постепенно развивается, и на нем появляются многообещающие продукты. Несмотря на популярность мировых лидеров, таких как Oracle, MySQL и Microsoft SQL Server, в России начинают активно использовать и разрабатывать собственные СУБД, учитывая особенности и потребности российского бизнеса.
Oracle Database — одна из наиболее узнаваемых и широко используемых систем управления базами данных (СУБД) в мире. Ее популярность обусловлена не только высокой надежностью, но и способностью обеспечивать поддержку корпоративных приложений на высоком уровне. Богатый спектр функций позволяет использовать Oracle Database для разнообразных задач: от аналитики до обработки транзакций с высокой производительностью.
MySQL, с другой стороны, представляет собой открытую реляционную СУБД, пользующуюся популярностью в веб-разработке и среди малых предприятий. Ее бесплатность и легкость использования делают ее предпочтительным выбором для многих разработчиков, особенно для начинающих и проектов с ограниченными ресурсами.
Microsoft SQL Server — еще один крупный игрок, предоставляющий разнообразные функции для разработки приложений под операционную систему Windows и интеграцию с другими продуктами от Microsoft. Его удобство использования и интеграция в экосистему Microsoft делают его популярным среди приложений, созданных для работы в окружении Windows.
MongoDB, нереляционная (NoSQL) база данных, отличается от остальных тем, что хранит данные в формате JSON, что обеспечивает гибкость в обработке неструктурированных данных. Ее масштабируемость и высокая скорость обработки данных делают MongoDB популярным выбором для приложений, работающих с большими объемами данных.
Одной из российских СУБД является Postgres Pro. Она основана на открытой и бесплатной СУБД PostgreSQL, которая пользуется большой популярностью в мировом масштабе. Postgres Pro предназначена для корпоративного сегмента и подверглась значительной доработке и адаптации под требования больших предприятий. Благодаря этому она может предоставлять более широкий спектр функций и поддержку для корпоративных приложений.
Еще одной интересной российской разработкой является Arenadata DB (ADB). Эта реляционная СУБД построена на основе Greenplum и также включена в реестр российского программного обеспечения. Greenplum является мощной распределенной СУБД, ориентированной на анализ больших объемов данных. Arenadata DB предоставляет широкие возможности для хранения, обработки и анализа данных в корпоративных окружениях.