Практика 6 Параллелизация. Быстрая сортировка.#
Люди давно уже поняли, что в большинстве случаев два человека способны выполнить работу быстрее, чем каждый из них по отдельности,
а трое могут справиться с ней еще быстрее. На практике такое распараллеливание выполняется по-разному.
Документы из большого числа папок в офисе легче перебрать, если распределить папки по нескольким сотрудникам.
Конвейер ускоряет процесс сборки, поскольку человек, постоянно выполняющий одну и ту же работу, делает ее быстрее:
нет необходимости менять инструменты.
Ведра с водой быстрее передавать по цепочке, чем бегать с ними от одного места к другому.
В параллельном программировании используются очень похожие средства.
- Многозадачные системы – каждый процессор выполняет одни и те же операции над различными данными.
- Конвейерные системы – каждый процессор осуществляет лишь один шаг задания, передавая результаты следующему процессору, который делает очередной шаг.
- Системы с потоками данных – последовательность процессоров, сформированная для выполнения определенного задания; для вычисления результата данные передаются от одного процессора к другому.
Работа с потоками#
Откройте Visual Studio и создайте новое консольное приложение
Для начала работы с библиотекой threading в Python не придется ничего дополнительно устанавливать.
Этот инструмент — стандартный модуль, который поставляется вместе с интерпретатором.
Его потребуется всего лишь подключить через специальную команду:
import threading
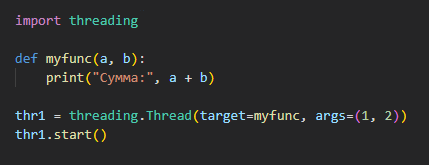
Работа с потоками возможна за счет создания экземпляров класса Thread.
Чтобы создать отдельный поток, нужно создать экземпляр класса и затем применить к нему метод start.
import threading
def myfunc(a, b):
print('сумма : ',a + b)
thr1 = threading. Thread(target = myfunc, args = (1, 2)).start()
print('основной поток')
## основной поток
## сумма : 3
Здесь функция mydef запущена в отдельном потоке. В качестве её аргументов переданы числа 1 и 2.
Конструкция threading.Thread() позволяет создавать новые потоки путем создания экземпляров класса Thread.
threading.Thread(group=None, target=None, name=None, args=(), kwargs={}, daemon=None)
- group – всегда принимает значение
None. Зарезервировано для будущего расширения класса ThreadGroup. - target – функция, выполняемая в потоке через метод run(). Если передается
None, функция не вызывается. - name – имя потока. По умолчанию принимает вид "Thread-X", где
X– десятичное число. Можно задать вручную. - args – кортеж аргументов, передаваемых в вызываемую функцию.
- kwargs – словарь аргументов, передаваемых в функцию.
- daemon – флаг, указывающий, является ли поток демоническим.
- По умолчанию
None, что означает, что поток наследует это свойство от родительского потока. - Разработчик может самостоятельно установить этот параметр.
Daemon требует более подробного рассмотрения. Не все разработчики быстро понимают, что этот параметр собой представляет. Данный материал в лекции 5.
Прочие методы сведем в таблицу.
| Метод | Описание | Пример кода |
|---|---|---|
| start() | Запускает созданный поток. После вызова threading.Thread() поток неактивен, и для его запуска необходимо использовать start(). |
 |
| join(timeout=None) | Блокирует выполнение текущего потока до завершения вызываемого потока. Можно передать timeout – время ожидания в секундах. |
 |
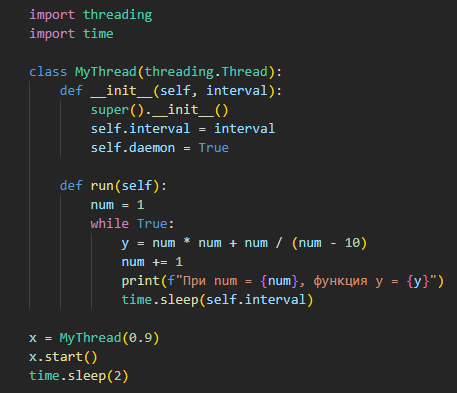
| run() | Определяет выполняемые операции при запуске потока. Используется при создании пользовательских классов на основе Thread. |
 |
| is_alive() | Проверяет, выполняется ли поток в текущий момент. Полезно для управления демоническими потоками. | 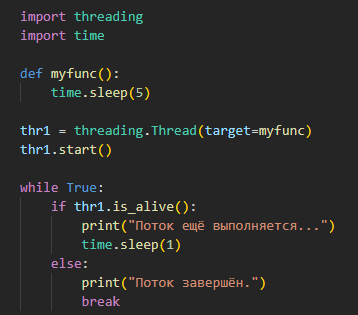 |
Для работы с потоками в C++ используется стандартная библиотека
#include <thread>
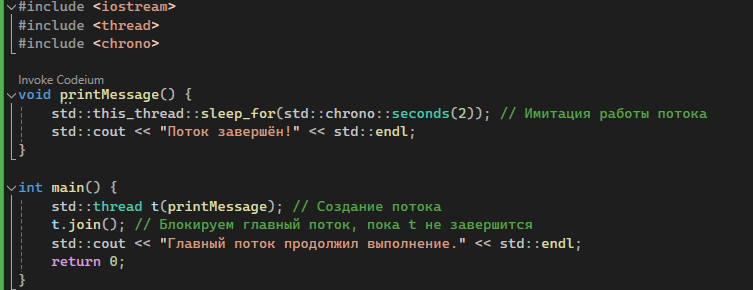
Работа с потоками возможна за счет создания экземпляров класса std::thread. Чтобы создать отдельный поток, нужно создать экземпляр этого класса и затем вызвать метод join(), чтобы ожидать завершения потока.
#include <iostream>
#include <thread>
void myfunc(int a, int b) {
std::cout << "Сумма: " << a + b << std::endl;
}
int main() {
std::thread thr1(myfunc, 1, 2);
std::cout << "Основной поток" << std::endl;
thr1.join(); // Ожидаем завершения потока
return 0;
}
Конструкция std::thread t() позволяет создавать новые потоки путем создания экземпляров класса Thread.
std::thread t(callable_object, arg1, arg2, ..)
Создаёт новый поток выполнения, ассоциируемый с
t, который вызывает callable_object(arg1, arg2). Вызываемый объект (т.е. указатель функции, лямбда-выражение, экземпляр класса с вызовом функции operator) немедленно выполняется новым потоком с (выборочно) передаваемыми аргументами. Они копируются по умолчанию. Если хотите передать по ссылке, придётся использовать метод warp к аргументу с помощью std::ref(arg). Не забывайте: если хотите передать unique_ptr, то должны переместить его (std::move(my_pointer)), так как его нельзя копировать.
Прочие методы сведем в таблицу.
| Метод | Описание | Пример кода |
|---|---|---|
| std::thread::join() | Блокирует выполнение текущего потока до завершения вызываемого потока. Можно передать timeout – время ожидания в секундах. |
 |
| std::thread::detach() | Ожидает завершения потока или освобождает его ресурс, если поток не требуется для дальнейших операций. | 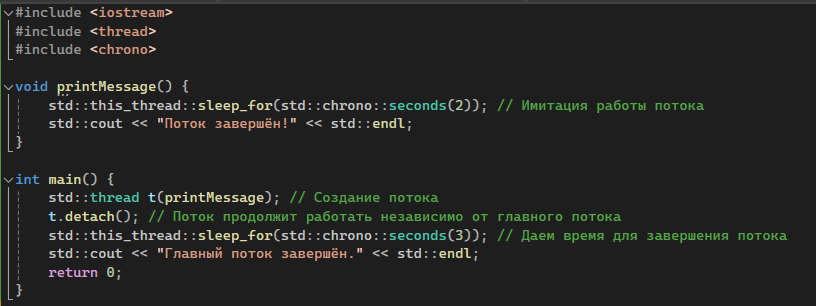 |
| std::thread::get_id() | Получает идентификатор потока, который можно использовать для проверки состояния или логирования. | 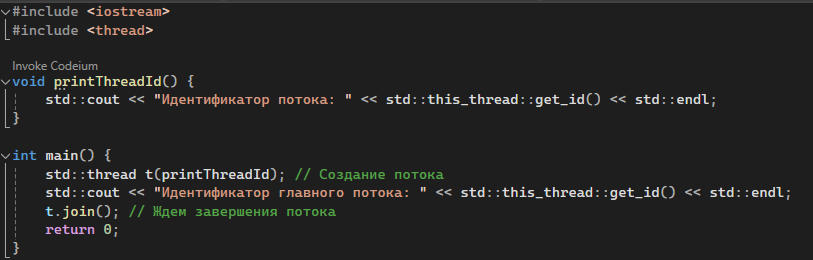 |
| std::this_thread::get_id() | Получает идентификатор текущего потока. Часто используется для логирования. | |
Потоковая остановка#
Иногда фоновый поток необходимо остановить, например, если в методе run() используется бесконечный цикл. Один из распространённых способов — использование специальной переменной stop.
Принцип работы:#
- В потоке проверяется значение переменной
stopв бесконечном цикле. - Если
stop == True, поток завершает работу. - Не рекомендуется использовать функции, которые могут блокировать выполнение на длительное время. Лучше применять
timeout.
| Метод | Описание | Пример кода |
|---|---|---|
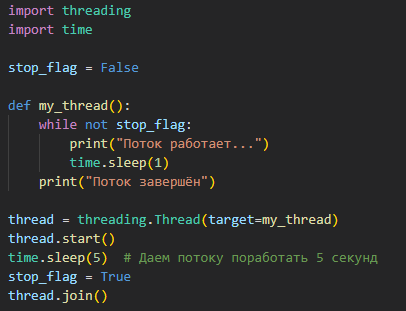
Остановка потока через переменную stop |
В бесконечном цикле создаётся проверка переменной stop. Если её значение становится True, поток завершает работу. |
 |
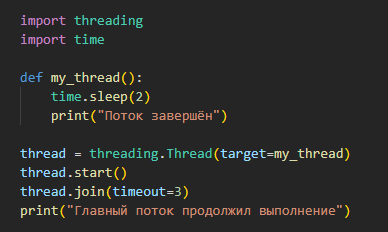
Использование timeout в блокирующих функциях |
Если поток использует блокирующую операцию, например time.sleep(), можно передавать timeout, чтобы избежать зависания. |
 |
В C++ завершение потока можно осуществить с помощью двух способов:
-
detach()— позволяет отцепить поток от основного потока, чтобы он продолжил выполнение в фоновом режиме. Однако, после вызоваdetach(), поток должен быть завершён сам, и основному потоку не нужно ожидать его завершения с помощьюjoin(). Это используется, когда не требуется отслеживать завершение потока. -
Использование переменной
stop— можно использовать атомарную переменную или флаг для управления состоянием потока и завершения его работы.
#include <iostream>
#include <thread>
#include <atomic>
std::atomic<bool> stop(false);
void run() {
int i = 0;
while (!stop) {
std::cout << "Thread running: " << i << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1));
i++;
}
std::cout << "Thread stopped." << std::endl;
}
int main() {
std::thread t(run);
std::this_thread::sleep_for(std::chrono::seconds(3)); // Даем потоку поработать 3 секунды
stop = true; // Останавливаем поток
t.join(); // Ожидаем завершения потока
}
Также есть принудительное завершение потока
Функция std::terminate() используется для немедленного завершения программы, если возникает необработанное исключение или другая ситуация, требующая немедленного завершения потока.
#include <iostream>
#include <thread>
#include <stdexcept>
void run() {
std::cout << "Thread started" << std::endl;
// Имитируем ошибку, которая вызывает вызов terminate
throw std::runtime_error("Something went wrong!");
std::cout << "This line will never be executed" << std::endl;
}
int main() {
try {
std::thread t(run);
t.join();
} catch (const std::exception& e) {
std::cout << "Exception caught: " << e.what() << std::endl;
// В случае ошибки вызываем terminate
std::terminate();
}
return 0;
}
Недетрменированность выполнения#
Из-за того, что несколько потоков делят одно адресное пространство и ресурсы, многие операции становятся критичными.
Если операция не будет атомарной, то может произойти странное. Прошу запустить следующих код python и c++
import threading
def run(thread_name):
for i in range(10):
print(f"{thread_name}{i}")
# Создание потоков
tA = threading.Thread(target=run, args=("A",))
tB = threading.Thread(target=run, args=("\tB",))
# Запуск потоков
tA.start()
tB.start()
# Ожидание завершения потоков
tA.join()
tB.join()
#include <thread>
#include <iostream>
#include <string>
void run(std::string threadName) {
for (int i = 0; i < 10; i++) {
std::string out = threadName + std::to_string(i) + "\n";
std::cout << out;
}
}
int main() {
std::thread tA(run, "A");
std::thread tB(run, "\tB");
tA.join();
tB.join();
}
Большинство операций неатомарные. Если операция неатомарная, можно увидеть её промежуточное состояние, так как она не является неделимой. Например: запись 64 битов, 32 бита за один раз. Во время этой операции другой поток может увидеть 32 старых бита и 32 новых, получая совершенно неверный результат. По этой причине результаты таких операций должны казаться атомарными, даже если они такими не являются.
Примечание: даже инкремент не является атомарной операцией: int tmp = a; a = tmp + 1;
Самое простое решение здесь — использовать шаблон std::atomic, который разрешает атомарные операции разных типов.
В отличие от однопоточной реализации, каждое выполнение даёт разный и непредсказуемый результат (единственное, что можно сказать определённо: строки А и B упорядочены по возрастанию). Это может вызвать проблемы, когда очерёдность команд имеет значение.
Warning
Если два потока имеют доступ к одним и тем же данным (один к записи, другой — к чтению), нельзя сказать наверняка, какая операция будет выполняться первой!
Параллельный поиск максиума#
Функция find_max(arr, start, end, result, index):
local_max = максимум в подмассиве arr с индексами от start до end
result[index] = local_max
Функция parallel_max(arr, num_threads):
n = длина массива arr
chunk_size = n // num_threads // Размер блока для каждого потока
threads = пустой список для хранения потоков
result = список из None длины num_threads для хранения локальных максимумов
// Создание и запуск потоков
для i от 0 до num_threads - 1:
start = i * chunk_size
если i != num_threads - 1:
end = (i + 1) * chunk_size
иначе:
end = n // Последний поток обрабатывает оставшиеся элементы
создаём новый поток, который вызывает функцию find_max с параметрами arr, start, end, result, i
добавляем поток в список threads
запускаем поток
// Ожидание завершения всех потоков
для каждого потока в списке threads:
ожидаем завершения потока с помощью thread.join()
печатаем локальные результаты result
возвращаем максимальное значение из списка result
Главная программа:
arr = [1, 7, 3, 9, 2, 8, 5, 6, 4, 0]
num_threads = 2 // Количество потоков
maximum_value = parallel_max(arr, num_threads) // Вычисляем максимальное значение
печатаем "Максимум:", maximum_value
Функция find_max(arr, start, end, local_max, mtx):
local_max = максимум в подмассиве arr от start до end
// Поток завершает выполнение, локальный максимум найден
Функция parallel_max(arr, num_threads):
n = длина массива arr
chunk_size = n // num_threads // Размер блока для каждого потока
threads = пустой список для хранения потоков
global_max = минимально возможное значение (например, INT_MIN)
mtx = мьютекс для синхронизации
// Создание и запуск потоков
для i от 0 до num_threads - 1:
start = i * chunk_size
если i == num_threads - 1:
end = n // Последний поток обрабатывает оставшиеся элементы
иначе:
end = (i + 1) * chunk_size
создаём новый поток, который вызывает функцию find_max с параметрами arr, start, end, local_max для потока, mtx
добавляем поток в список threads
запускаем поток
// Ожидание завершения всех потоков
для каждого потока в списке threads:
ожидаем завершения потока с помощью thread.join()
// Найти глобальный максимум среди локальных максимумов
для каждого локального максимума в local_max_values:
синхронизируем доступ к global_max с помощью мьютекса mtx
обновляем global_max, если текущий локальный максимум больше
возвращаем global_max
Главная программа:
arr = [1, 7, 3, 9, 2, 8, 5, 6, 4, 0]
num_threads = 2 // Количество потоков
maximum_value = parallel_max(arr, num_threads) // Вычисляем максимальное значение
печатаем "Максимум:", maximum_value
Принципы оценки параллельных алгоритмов#
При работе с параллельными алгоритмами нас будут интересовать два новых понятия: коэффициент ускорения и стоимость. Подробнее данные понятия будут рассмотрены в лекции 5.
Коэффициент ускорения#
Коэффициент ускорения параллельного алгоритма показывает, насколько он работает быстрее оптимального последовательного алгоритма.
Так, мы видели, что оптимальный алгоритм сортировки требует O(N log N) операций.
У параллельного алгоритма сортировки со сложностью O(N) коэффициент ускорения составил бы O(log N).
Стоимость#
Стоимость параллельного алгоритма определяется как произведение сложности алгоритма на число используемых процессоров.
Если алгоритм параллельной сортировки за O(N) операций требует столько же процессоров, сколько входных записей,
то его стоимость равна O(N²).
Это означает, что параллельная сортировка обходится дороже, поскольку стоимость последовательной сортировки на одном процессоре
совпадает с её сложностью и равна O(N log N).
Расщепляемость задачи#
Близким понятием является расщепляемость задачи.
Если единственная возможность для алгоритма параллельной сортировки — использование числа процессоров, равного числу входных записей,
то такой алгоритм становится бесполезным, как только входные данные становятся слишком большими.
Для нас будут интересны алгоритмы параллельной сортировки, в которых:
- Число процессоров значительно меньше объема входных данных.
- Это число не увеличивается при росте длины входа.
Быстрая сортировка#
Можно сделать сортировку еще быстрее, если менять местами не соседние элементы, а элементы на самом большом расстоянии друг от друга.
QuickSort является существенно улучшенным вариантом алгоритма сортировки с помощью прямого обмена (его варианты известны как «Пузырьковая сортировка» и «Шейкерная сортировка»), известного в том числе своей низкой эффективностью.
Принципиальное отличие QuickSort состоит в том, что сначала выполняются перестановки элементов на наибольшем возможном расстоянии, а затем после каждого прохода массив делится на две независимые группы. Таким образом, улучшение самого неэффективного метода привело к созданию одного из наиболее эффективных алгоритмов сортировки.
Общая идея алгоритма
1. Выбрать опорный элемент из массива. Это может быть любой элемент, но выбор влияет на эффективность алгоритма.
2. Разделить массив на три части:
- элементы меньше опорного,
- элементы, равные опорному,
- элементы больше опорного.
3. Рекурсивно отсортировать подмассивы «меньших» и «больших» значений, если их длина больше единицы.
Псевдокодом реализация будет следующая:
Функция быстраяСортировка(массив, низ, высокий):
если низ < высокий то:
опорныйИндекс ← разделить(массив, низ, высокий)
быстраяСортировка(массив, низ, опорныйИндекс - 1)
быстраяСортировка(массив, опорныйИндекс + 1, высокий)
конец если
Функция разделить(массив, низ, высокий):
опорный ← массив[высокий]
i ← низ - 1
для j от низ до высокий - 1:
если массив[j] <= опорный то:
i ← i + 1
поменять местами(массив[i], массив[j])
поменять местами(массив[i + 1], массив[высокий])
вернуть i + 1
На практике массив обычно делят не на три, а на две части, например: «меньшие опорного» и «равные и большие». Такой подход упрощает алгоритм разделения и делает его более эффективным.
Алгоритм был разработан Тони Хоаром в ходе работы над машинным переводом. В то время словарь хранился на магнитной ленте, и сортировка слов позволяла ускорить процесс перевода, так как переводы можно было находить за один прогон ленты без перемотки назад.
QuickSort был придуман Хоаром в период его пребывания в СССР, где он изучал машинный перевод в МГУ и работал над созданием русско-английского разговорника.
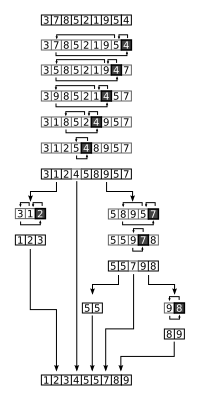
Пример быстрой сортировки. Здесь опорным является последний элемент массива (ячейка чёрного цвета), что в отсортированных массивах может приводить к ухудшению производительности.
Примечание для желающих продолжить
