Параллелизация на уровне данных#
Первые операционные системы считывали пачки перфокарт и распечатывали результат на принтере. Такая организация вычислений называлась пакетным режимом. Чтобы получить результат, обычно приходилось ждать несколько часов. При таких условиях было трудно развивать программное обеспечение.
В 1960-х годах компания IBM в рамках операционной системы OS/360 реализовала многозадачность, которая заключалась в разбиении памяти на несколько частей, называемых разделами, в каждом из которых выполнялось отдельное задание. Пример памяти многозадачной системы с различными заданиями изображен на рисунке 1. Пока одно задание ожидало завершения работы устройства ввода-вывода, другое могло использовать центральный процессор. Если в оперативной памяти содержалось достаточное количество заданий, центральный процессор мог быть загружен почти на все 100 % времени
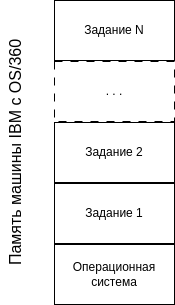
Хотя операционные системы третьего поколения неплохо справлялись с большинством научных вычислений и крупных коммерческих задач по обработке данных, но по своей сути они были все еще разновидностью систем пакетной обработки. В системах третьего поколения промежуток времени между передачей задания и возвращением результатов часто составлял несколько часов, так что единственная поставленная не в том месте запятая могла стать причиной сбоя при компиляции, и получалось, что программист полдня тратил впустую. Желание сократить время ожидания ответа привело к разработке режима разделения времени — варианту многозадачности, при котором у каждого пользователя есть свой диалоговый терминал
Процесс и поток#
Основным понятием в любой операционной системе является процесс: абстракция, описывающая выполняющуюся программу. Процессы — это одна из самых старых и наиболее важных абстракций, присущих операционной системе.
Note
Процесс — это просто экземпляр выполняемой программы, включая текущие значения счетчика команд, регистров и переменных.
Для реализации модели процессов операционная система ведет таблицу процессов (состоящую из массива структур), в которой каждая запись соответствует какому-нибудь процессу.
Ряд авторов называют эти записи блоками управления процессом — Process Control Block (PCB).
Эти записи содержат важную информацию о состоянии процесса, включая:
- Счетчик команд
- Указатель стека
- Распределение памяти
- Состояние открытых файлов
- Учетную и планировочную информацию
- И другие данные, необходимые для восстановления выполнения процесса после его переключения в состояние готовности или блокировки.
При переключении процесса информация сохраняется, чтобы он мог возобновить выполнение так, как будто никогда не останавливался.
В традиционных операционных системах у каждого процесса есть адресное пространство и единственный поток управления. Фактически это почти что определение процесса. Тем не менее нередко возникают ситуации, когда неплохо было бы иметь в одном и том же адресном пространстве несколько потоков управления, выполняемых квазипараллельно, как будто они являются чуть ли не обособленными процессами (за исключением общего адресного пространства).
Таненбаум называет выполнение процессов квазипараллельным в рамках одноядерных однопроцессных систем. Пример квазипараллельного выполнения изображен на рисунке 2.

Переключение контекста — это процесс переключения процессора с выполнения одного процесса на выполнение другого.
Стоит заметить, что время, затраченное на переключение контекста, не используется ОС для полезной работы и является «накладными» расходами, снижающими производительность системы.
В любой многозадачной системе центральный процессор быстро переключается между процессами, предоставляя каждому из них десятки или сотни миллисекунд.
Хотя в каждый конкретный момент времени процессор работает только с одним процессом, за 1 секунду он может успеть обработать несколько процессов, создавая иллюзию параллельной работы.
Такой эффект называют псевдопараллелизмом в отличие от настоящего аппаратного параллелизма в многопроцессорных системах, где используется не менее двух процессоров, работающих с одной физической памятью.
Выполнение задач на многоядерном процессоре обычно считается истинным параллелизмом.
В отличие от псевдопараллелизма, создающего иллюзию параллельной работы на одноядерном процессоре за счёт быстрого переключения между задачами, многоядерные процессоры могут выполнять несколько задач одновременно, используя разные ядра для разных потоков или процессов.
Пример выполнения разных процессов на многопроцессорной системе представлен на рисунке 3.
За распределение процессорного времени отвечает планировщик ОС — компонент ядра, обеспечивающий:
- Максимально эффективное использование процессорных ресурсов
- Справедливое распределение вычислительной мощности
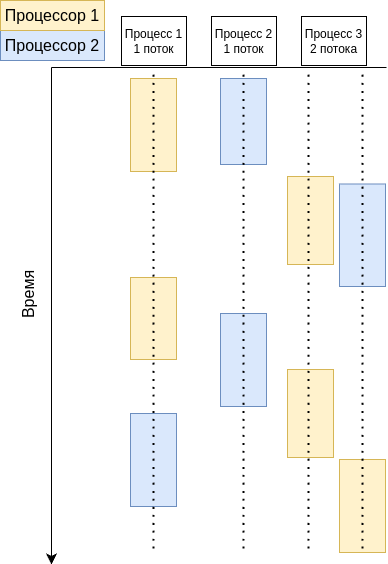
Для простоты на рисунке изображены два «абстрактных» одноядерных процессора (желтый и синий) и три «абстрактных» процесса, один из которых имеет два потока.
На данном рисунке стоит обратить внимание, что один поток может выполняться на разных процессорах (в зависимости от решений планировщика). Можно заметить, что у третьего процесса могут возникать две возможные ситуации:
- Оба потока выполняются параллельно на разных процессорах.
- Оба потока выполняются квазипараллельно на одном процессоре.
Примечание: на рисунке и далее два процессора можно заменить двумя ядрами одного процессора, и на данном уровне абстракции рисунок не поменяется.
Достоинства потоков по сравнению с процессами
Потоки сильно проще создавать и уничтожать по сравнению с более тяжеловесными процессами.
Единое адресное пространство памяти позволяет ускорить обмен данных, избегая межпроцессного общения.
Стандартизация многопоточности#
Институт инженеров электротехники и электроники (IEEE) — Institute of Electrical and Electronics Engineers в 1995 году определил стандарт IEEE standard 1003.1c — Portable Operating System Interface (POSIX), в рамках которого присутствует пакет, касающийся потоков Pthreads.
Данный стандарт поддерживается в большинстве UNIX-систем, включая Linux и Mac OS. Использование pthreads в ОС семейства Windows требует использования библиотеки Pthreads-win32 или компилятора MinGW с флагом -lpthread. Подробно со стандартом можно ознакомиться в источнике [3]. Использование POSIX-threads будет рассмотрено в отдельной заметке.
Стандарт C++11#
Стандарт C++11 ввел в язык C++ стандартизированную поддержку многопоточности, включая:
- Потоки (
threads) - Мьютексы (
mutexes) - Условные переменные (
condition variables) - Атомарные операции
Это значительно упростило разработку многопоточных приложений на C++, делая код более переносимым между различными платформами. Библиотека Boost также содержит модули, описывающие работу с многопоточностью. Boost.Thread — часть библиотеки Boost, предлагает расширенные возможности для многопоточного программирования в C++.
Многопоточность в WinAPI и .NET#
В операционных системах семейства Windows существует набор интерфейсов WinAPI, который включает в себя инструменты для работы с потоками. Многопоточность стала доступна в рамках серверной версии Windows NT в 1993 году. С использованием потоков в WinAPI можно ознакомиться в источнике [4].
В экосистеме .NET (включая C#, F# и VB.NET) многопоточность поддерживается через классы, находящиеся в пространстве имен System.Threading, предоставляя разнообразные возможности для создания и управления потоками, а также для синхронизации работы между ними.
Проблема разделения ресурсов#
Многопоточные приложения, хотя и предлагают значительные преимущества в плане производительности и эффективности использования ресурсов, также связаны с рядом потенциальных проблем и сложностей, связанных с параллельным выполнением кода.
Рассмотрим ситуацию, когда два процесса имеот общие данные и, предположим, результат выполнения зависит от того, какой поток получит доступ первым.
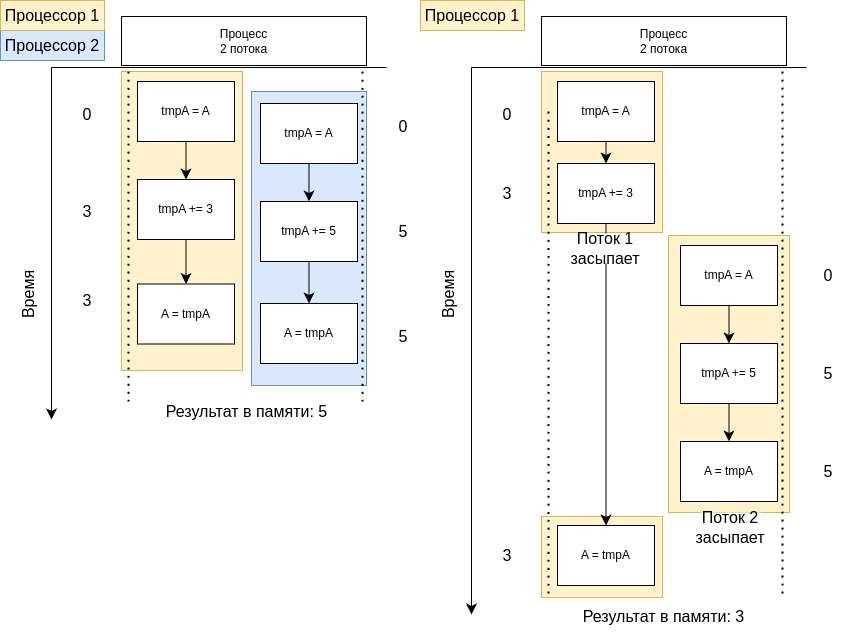
На рисунке выше представлены две ситуации: состояние гонки на двухпроцессорной (слева) и однопроцессорной (справа) системах. Здесь указан простой высокоуровневый пример, но стоит учитывать, что проблема гонки на запись ресурсов может возникать даже с простыми операциями на уровне переноса данных из регистров процессоров: такая ситуация изображена на рисунке ниже.
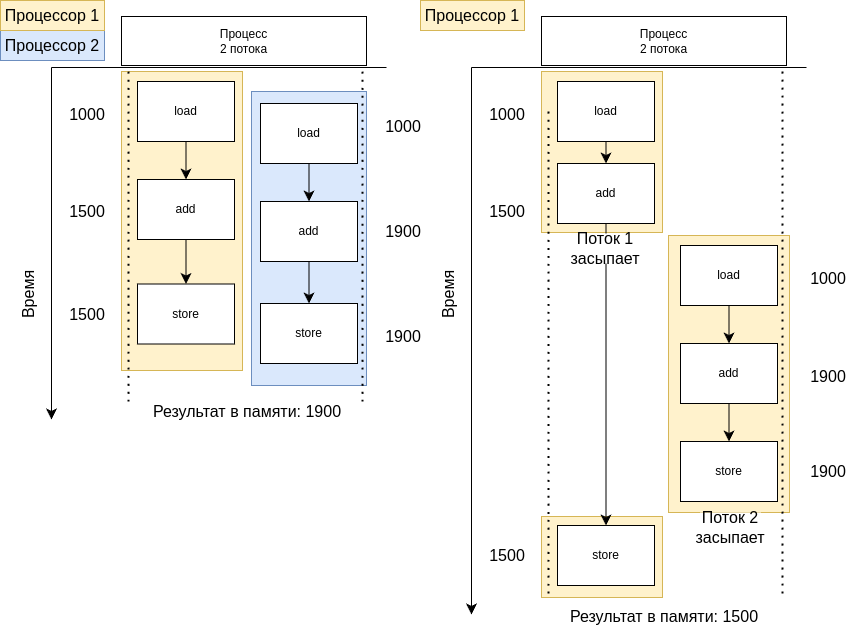
В качестве решения можно использовать механизмы блокировки, такие как мьютексы или семафоры, для обеспечения взаимоисключающего доступа к общим ресурсам, однако к ним вернемся позже.
Задача обедающих философоов#
Задача об обедающих философах — классический пример, используемый в информатике для иллюстрации проблем синхронизации при разработке параллельных алгоритмов и техник решения этих проблем.
Задача была сформулирована в 1965 году Эдсгером Дейкстрой как экзаменационное упражнение для студентов. В качестве примера был взят конкурирующий доступ к ленточному накопителю. Вскоре задача была сформулирована Энтони Хоаром в том виде, в каком она известна сегодня.
Постановка задачи
Пять безмолвных философов сидят вокруг круглого стола, перед каждым философом стоит тарелка спагетти. На столе между каждой парой ближайших философов лежит по одной вилке.
Каждый философ может либо есть, либо размышлять. Приём пищи не ограничен количеством оставшихся спагетти — подразумевается бесконечный запас. Тем не менее, философ может есть только тогда, когда держит две вилки — взятую справа и слева (альтернативная формулировка проблемы подразумевает миски с рисом и палочки для еды вместо тарелок со спагетти и вилок).
Каждый философ может взять ближайшую вилку (если она доступна) или положить — если он уже держит её. Взятие каждой вилки и возвращение её на стол являются раздельными действиями, которые должны выполняться одно за другим.
Вопрос задачи заключается в том, чтобы разработать модель поведения (параллельный алгоритм), при котором ни один из философов не будет голодать, то есть будет вечно чередовать приём пищи и размышления.

Задача сформулирована таким образом, чтобы иллюстрировать проблему избежания взаимной блокировки (англ. deadlock) — состояния системы, при котором прогресс невозможен.
Например, можно посоветовать каждому философу выполнять следующий алгоритм:
- Размышлять, пока не освободится левая вилка. Когда вилка освободится — взять её.
- Размышлять, пока не освободится правая вилка. Когда вилка освободится — взять её.
- Есть
- Положить левую вилку
- Положить правую вилку
- Повторить алгоритм сначала
Это решение задачи некорректно: оно позволяет системе достичь состояния взаимной блокировки, когда каждый философ взял вилку слева и ждёт, когда вилка справа освободится
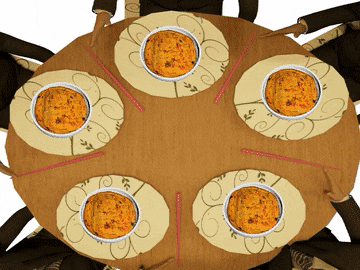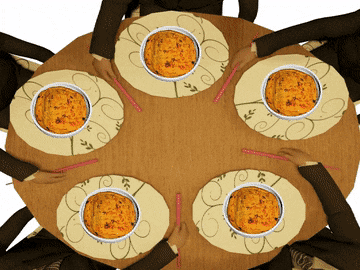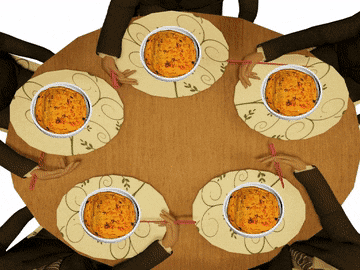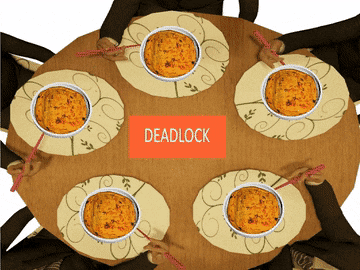
Проблема ресурсного голодания (англ. resource starvation) может возникать независимо от взаимной блокировки, если один из философов не может завладеть левой и правой вилкой из-за проблем синхронизации. Например, может быть предложено правило, согласно которому философы должны класть вилку обратно на стол после пятиминутного ожидания доступности другой вилки, и ждать ещё пять минут перед следующей попыткой завладеть вилками. Эта схема устраняет возможность блокировки (так как система всегда может перейти в другое состояние), но по-прежнему существует возможность «зацикливания» системы (англ. livelock), при котором состояние системы меняется, но она не совершает никакой полезной работы. Например, если все пять философов появятся в столовой одновременно и каждый возьмёт левую вилку в одно и то же время, то философы будут ждать пять минут в надежде завладеть правой вилкой, потом положат левую вилку и будут ждать ещё пять минут прежде, чем попытаться завладеть вилками снова.
Проблемные ситуации#
Ситуация 1. Взаимная блокировка (Deadlock)
Взаимная блокировка возникает, когда два или более потоков ожидают друг друга для освобождения ресурсов, уже занятых ими, в результате чего все ожидающие потоки оказываются заблокированными и не могут продолжить выполнение.
Рассмотрим следующую блок-схему и укажем на уязвимое место.
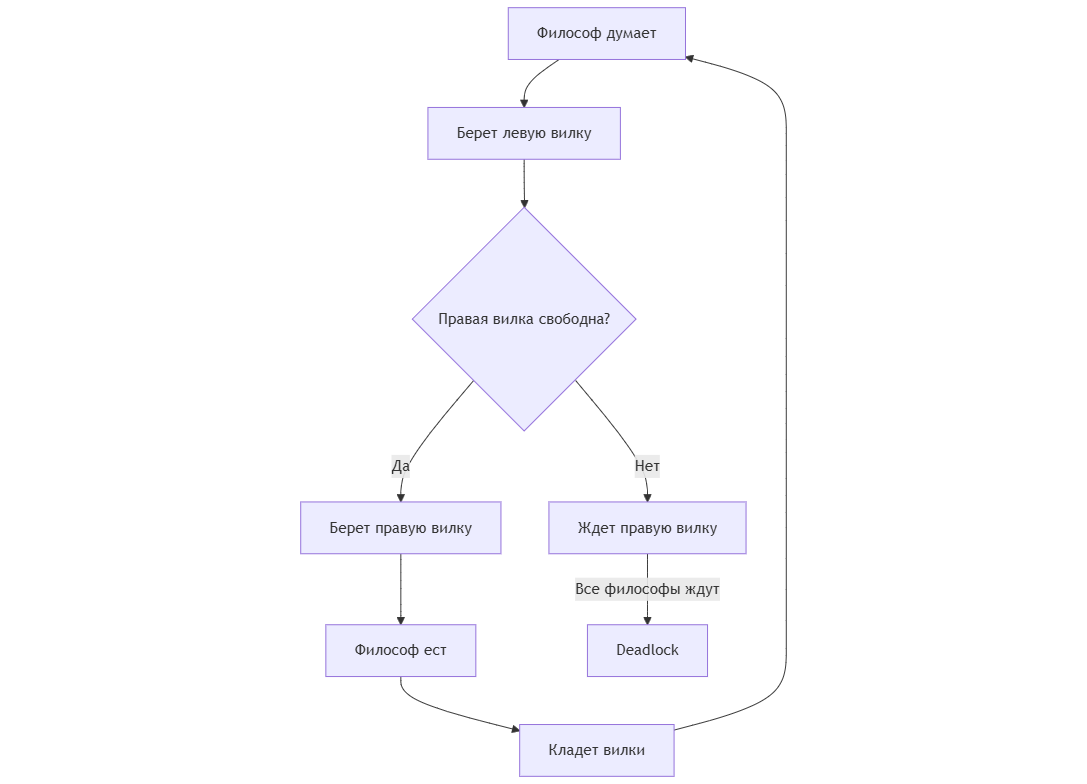
Оказывается в некоторый момент времени может сложиться ситуация, когда каждый четный или нечетный философ завладеет вилкой. Когда это проихойдет, окажется, что все остальные философы начнут голодать, причем бескконечно, поскольку как только основые философы закончят обедать, согласно нашему алгоритму они сразу же вновь возьмут вилки.
На более практическом примере такую схему можно изобразить следующим образом:
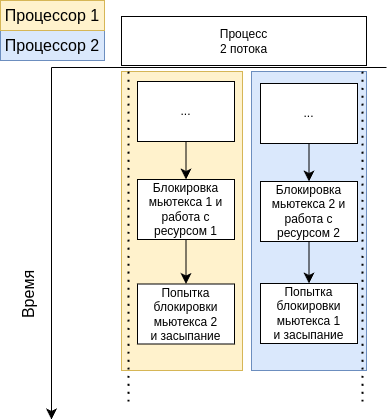
Ситуация 2. Живые блокировки (Livelocks)
Живая блокировка возникает, когда два или более потоков активно реагируют на действия друг друга таким образом, что они продолжают изменять состояние без возможности продвижения вперёд. Причина зачастую кроется в реализации алгоритмов управления доступом к ресурсам или в ошибках в логике состояния приложения. Она может быть вызвана некорректным дизайном системы синхронизации, когда потоки постоянно пытаются избежать взаимной блокировки, активно меняя свои состояния, что приводит к бесконечному циклу.
Допустим, наши философы крайне тактичны и внимательно проверяют, не взял ли кто вилку до них. Если левая вилка не взята, они ее берут при условии, что свободна и правая. Однако как только они правую они проверяют не занята ли левая и в случае если она занята, то кладут правую. Понимаю, что такое объяснение может показаться странным, надеюсь блок-схема поможет вашему пониманию.
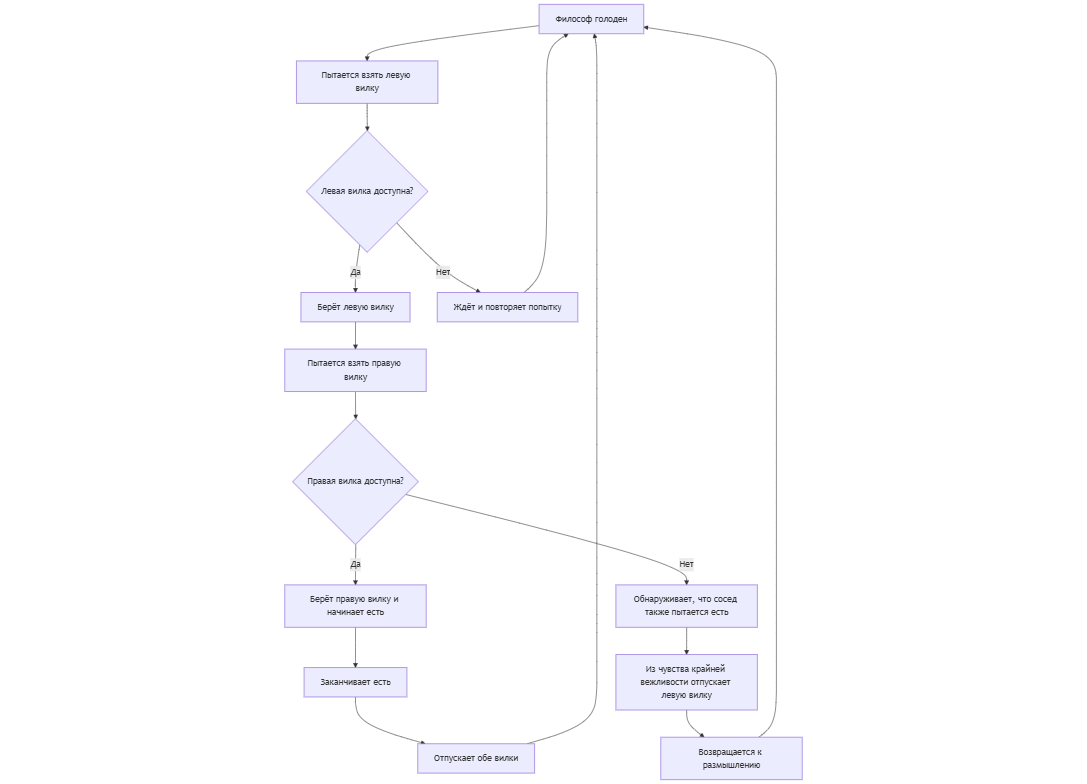
Решение задачи#
Официант#
Описание
В этом решении задача решается с помощью посредника — официанта, который управляет доступом к вилкам. Каждый философ должен сначала запросить у официанта вилки, прежде чем приступить к еде, и вернуть их, когда закончит.
Алгоритм
1. Философы обращаются к официанту за вилками.
2. Официант контролирует, чтобы два философа не могли взять одну и ту же вилку одновременно.
3. Философы могут поесть, если обе вилки доступны.
4. После еды философы возвращают вилки.
Преимущества
- Простота реализации.
- Исключение ситуации взаимных блокировок.
Недостатки
- Потенциальное увеличение задержек при большом числе философов.
Иерархия ресурсов#
Описание
В этом решении философы придерживаются порядка при выборе вилок. Чтобы избежать взаимных блокировок, философы всегда берут вилку с меньшим номером. Это гарантирует, что никто не окажется заблокированным, пытаясь захватить те же вилки.
Алгоритм
1. Философы начинают с вилки с меньшим номером.
2. Если эта вилка занята, философ ждет.
3. После того как философ поел, он возвращает вилки.
Преимущества
- Отсутствие внешнего контроля.
- Минимизация блокировок.
Недостатки
- Возможность блокировки, если все философы начинают одновременно брать вилки в одном порядке.
Решение с использованием мьютексов#
Описание
В этом решении для каждого философа создается объект, который управляет доступом к его вилкам. Используются мьютексы (простые механизмы синхронизации), чтобы гарантировать, что вилки берутся и освобождаются корректно.
Алгоритм
1. Каждый философ перед тем как начать есть, блокирует доступ к обеим вилкам.
2. После того как философ поел, он разблокирует вилки, позволяя другим философам их использовать.
Преимущества
- Простота реализации с использованием базовых механизмов синхронизации.
- Отсутствие взаимных блокировок, если правильно организована синхронизация.
Недостатки
- Необходимость внимательно следить за порядком захвата и освобождения вилок, чтобы избежать блокировок.
Практикоориентрованное объяснение#
Создание потоков#
В языке C++ работа с потоком осуществляется с помощью класса std::thread, который может порождать поток с точкой входа в:
- обычных функциях;
- лямбда-функциях;
- методах классов — требует передачи объекта класса в качестве первого аргумента потока;
- статических методах классов;
- функторах.
Если в конструктор не передать точку входа, то поток создан не будет, а лишь пустой объект, который может быть позднее инициализирован.
Кроме того, данный класс позволяет передавать любое число параметров в точку входа потока, что сильно упрощает взаимодействие с потоком по сравнению с POSIX подходом.
Примечание: для обеспечения безопасной работы с выделяемыми ресурсами следует использовать умные указатели.
Пример создания потока с точкой входа в обычной функции:
#include <thread>
#include <iostream>
void threadFunction1()
{
std::cout << "Поток 1 с обычной функцией без аргументов\n";
}
void threadFunction2(int i, double d)
{
std::cout << "Поток 2 с обычной функцией с аргументами: " << i << ' ' << d << '\n';
}
int main()
{
std::thread myThread1(threadFunction1);
myThread1.join();
std::thread myThread2(threadFunction2, 1, 2.34);
myThread2.join();
return 0;
}
Важное замечание: в данном примере и далее потоки создаются после завершения предыдущих во избежание гонки за поток вывода.
Другие методы
detach() — позволяет отсоединить поток от объекта std::thread, позволяя потоку продолжить выполнение независимо. После вызова этого метода объект std::thread может быть использован для другого потока выполнения.
-
swap(thread& other) — позволяет обменять потоки между двумя объектами
std::thread. Этот метод может быть полезен, например, для алгоритмов сортировки вstd::vector. -
get_id() — возвращает уникальный идентификатор потока выполнения, ассоциированного с объектом, для которого вызывается данный метод.
-
native_handle() — может быть использован для инициализации платформозависимой переменной для работы с потоками (например,
pthread_tв POSIX). -
hardware_concurrency() — статический метод, который возвращает количество потоков выполнения, которые могут быть эффективно запущены параллельно.
Получение значения из потока#
Методы std::promise и std::future предоставляют механизм обмена данными между потоками. Один поток обещает предоставить значение (promise), а другой поток ожидает получения этого значения (future). Для работы с этим механизмом необходимо подключить заголовочный файл <future>.
std::promise позволяет потоку обещать предоставление значения в будущем. Это используется, например, в потоке-производителе для установки результата выполнения операции. Для задания значения используется метод set_value(). Если в процессе выполнения операции возникает исключение, его можно установить с помощью метода set_exception().
Важно: если значение или исключение уже установлено, это приведет к вызову исключения std::future_error.
std::future — это объект, который будет получать значение или исключение из std::promise. Он используется в потоке-потребителе для ожидания результата, который должен быть установлен в соответствующем std::promise.
Для создания std::future из std::promise используется метод get_future().
Методы std::future:
-
get() — блокирует поток до тех пор, пока значение не будет установлено в связанном
std::promiseи возвращает его в точку вызова. -
wait() — блокирует вызывающий поток и ожидает, пока значение будет установлено, но не возвращает его в точку вызова.
-
wait_for(const chrono::duration& relative_time) — ожидает установки значения в течение указанного времени. По истечении времени возвращает:
std::future_status::timeout— если время ожидания истекло,std::future_status::ready— если значение установлено до истечения времени ожидания.
-
wait_until(const chrono::time_point& absolute_time) — аналогично
wait_for, но с абсолютной временной точкой.
Примечание: после вызова метода get() объект std::future становится не связанным. Его связанность следует проверять методом valid() перед вызовами get, wait, wait_for и wait_until.
#include <iostream>
#include <future>
#include <thread>
int threadFunction()
{
// Имитация работы
std::this_thread::sleep_for(std::chrono::seconds(1));
return 42; // Ответ на главный вопрос жизни, вселенной и всего такого
}
int main()
{
// Создание std::promise
std::promise<int> threadPromise;
// Получение std::future из std::promise
std::future<int> threadFuture = threadPromise.get_future();
// Запуск потока, передача std::promise в поток
std::thread myThread([&threadPromise]() {
threadPromise.set_value(threadFunction()); // Установка значения, которое будет получено через std::future
});
// Здесь можно проводить вычисления, пока запущенный поток работает
// Получение результата работы потока (main засыпает)
int result = threadFuture.get();
std::cout << "Результат работы потока: " << result << std::endl;
// Дождемся завершения потока
myThread.join();
return 0;
}
Зачем нужна синхронизация?#
Из-за того, что несколько потоков делят одно адресное пространство и ресурсы, многие операции становятся критичными, и тогда многопоточности требуются примитивы синхронизации. И вот почему:
Память — дом с привидениями
Память никогда больше не будет обычным хранилищем данных — теперь это обитель привидений. Представьте: поток смотрит Netflix, уютно устроившись перед Smart TV, и тут вдруг экран мигает и выключается. В панике поток набирает 112, а в ответ… «Доставка пиццы, спасибо, что позвонили». Что происходит? А то, что в доме полно привидений (где в роли привидений другие потоки): они все в одной комнате и взаимодействуют с одними и теми же объектами (это называется гонка данных), но друг для друга они привидения.
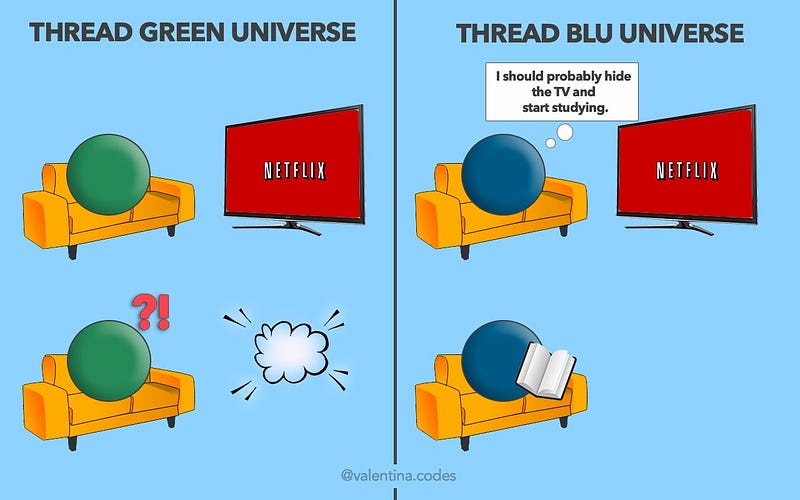
Поток должен объявить, что он использует. А затем, прежде чем трогать этот объект, проверить, не использует ли его кто-то ещё. Зелёный поток смотрит ТВ? Значит, никто не должен трогать ТВ (другие могут рядышком сесть и посмотреть, если что). Это можно сделать с помощью мьютекса.
Нужны атомарные операции!
Большинство операций неатомарные. Если операция неатомарная, можно увидеть её промежуточное состояние, так как она не является неделимой. Например: запись 64 битов, 32 бита за один раз. Во время этой операции другой поток может увидеть 32 старых бита и 32 новых, получая совершенно неверный результат. По этой причине результаты таких операций должны казаться атомарными, даже если они такими не являются.
Примечание: даже инкремент не является атомарной операцией:
int tmp = a; a = tmp + 1;
Самое простое решение здесь — использовать шаблон std::atomic, который разрешает атомарные операции разных типов.
Когерентность кеша и выполнение с изменением очерёдности
Каждое ядро пытается сохранить результаты какой-то работы, помещая недавние значения в локальный кеш. Но несколько потоков выполняются на разных ядрах, и значения, хранящиеся в кеше, больше не могут быть валидными, так что рано или поздно кеш должен обновляться. В то же время изменения не видны другим, пока кеш не очищен. Чтобы распространить изменения и обеспечить корректную видимость памяти, нужны определённые механизмы.
Кроме того, для повышения эффективности процессор и/или компилятор может поменять очерёдность выполнения команд. Это может привести к непредсказуемому поведению в параллельно выполняемой программе, в связи с чем необходимо гарантировать исполнение критически важных команд в первоначальном порядке.
Эта работа выполняется примитивами синхронизации, предполагающими использование барьеров доступа к памяти (строки кода, которые не вычеркнуть какими-то операциями) для обеспечения согласованности и предотвращения изменения очерёдности выполнения (инструкции внутри барьеров памяти нельзя вытащить оттуда).
Обратимся к коду. Теперь вы сами можете проверить это недетерминированное поведение многопоточности.#
#include <thread>
#include <iostream>
#include <string>
void run(std::string threadName) {
for (int i = 0; i < 10; i++) {
std::string out = threadName + std::to_string(i) + "\n";
std::cout << out;
}
}
int main() {
std::thread tA(run, "A");
std::thread tB(run, "\tB");
tA.join();
tB.join();
}
Возможный вывод:
B0
A0
A1
A2
B1
A3
B2
B3
..
В отличие от однопоточной реализации, каждое выполнение даёт разный и непредсказуемый результат (единственное, что можно сказать определённо: строки А и B упорядочены по возрастанию). Это может вызвать проблемы, когда очерёдность команд имеет значение.
#include <thread>
#include <iostream>
#include <string>
void runA(bool& value, int i) {
if(value) {
//значение всегда должно быть равным 1
std::string out = "[ " + std::to_string(i) + " ] value " + std::to_string(value) + "\n";
std::cout << out;
}
}
void runB(bool& value) {
value = false;
}
int main() {
for(int i = 0; i < 20; i++) {
bool value = true; //1
std::thread tA(runA, std::ref(value), i);
std::thread tB(runB, std::ref(value));
tA.join();
tB.join();
}
}
Возможный вывод:
..
[ 12 ] value 0
[ 13 ] value 1
[ 14 ] value 0
[ 15 ] value 0
[ 16 ] value 0
[ 17 ] value 0
[ 18 ] value 1
[ 19 ] value 0
..
Но что здесь происходит? После того как поток А оценивает «значение» как истинное, поток B меняет его. Теперь мы внутри блока if, даже если нарушены ограничения.
Warning
Если два потока имеют доступ к одним и тем же данным (один к записи, другой — к чтению), нельзя сказать наверняка, какая операция будет выполняться первой.
Средства синхронизации и их реализация#
Атомарные переменные#
Атомарные переменные позволяют выполнять операции (чтение, запись, модификация) над переменными (в случае C++ над объектами) без использования традиционных средств синхронизации (например мьютексов) в многопоточных приложениях. Для достижения такого результата используются аппаратные инструкции (lock-free).
В C++ атомарные переменные реализованы через шаблонный класс std::atomic, который поддерживает: базовые типы данных, указатели и пользовательские типы. Со стандарта C++20 поддерживаются std::shared_ptr и std::weak_ptr.
Операции над атомарной переменной могут выполняться без блокировок на аппаратном уровне. Проверить отсутствие блокировок можно с помощью метода is_lock_free. Также есть переменная is_always_lock_free, определяемая на этапе компиляции, но принимает true, если отсутствие блокировок не зависит от аппаратного уровня.
std::atomic<int> a(10); // Инициализация значением 10
int value = a.load(); // Чтение
a.store(20); // Запись без возврата значения
a = 30; // Ещё один способ записи с возвратом копии значения
value = a; // Ещё один способ чтения
Есть три метода для сравнения и обмена:
exchange— атомарный способ значения атомарной переменной новым значением, возвращая предыдущее значение.compare_exchange_weak— атомарно сравнивает значение с ожидаемым и, если они равны, устанавливает новое значение, возвращая флаг успешности замены.compare_exchange_strong— аналогичноcompare_exchange_weak, но с гарантией отсутствия ложных отказов, возвращая флаг успешности замены.
Примечание: compare_exchange_weak может «ложно сбоить», когда ожидаемое значение совпадает со значением в атомарной переменной: при таком подходе «weak» версии могут быть более эффективны на некоторых платформах за счет меньших требований к синхронизации (например в циклах, где операции могут быть повторены без значительных накладных расходов).
Функция exchange принимает следующие аргументы:
- desired — новое значение;
- order — опциональный параметр, определяющий порядок памяти для операции (по умолчанию std::memory_order_seq_cst).
Функции compare_exchange_ принимают следующие аргументы:
- expected — ожидаемое значение в атомарной переменной;
- desired — новое значение;
- order — опциональный параметр, определяющий порядок памяти для операции (по умолчанию std::memory_order_seq_cst).
Порядок памяти для операций exchange может принимать следующие значения:
std::memory_order_relaxed— операции не вводят никаких ограничений на порядок выполнения относительно других операций (самый слабый порядок, который позволяет достигнуть максимальной производительности на мультипроцессорных системах, но не гарантирует порядок видимости изменений между потоками);std::memory_order_acquire— предотвращает все чтения и записи, выполненные в текущем потоке после операции acquire, от перемещения до этой операции (гарантирует, что изменения, выполненные другими потоками до операции release, будут видимы после acquire);std::memory_order_release— предотвращает все чтения и записи, выполненные в текущем потоке до операции release, от перемещения после этой операции (обеспечивает, что операции, выполненные до release, будут видимы в других потоках, выполняющих соответствующую операцию acquire);std::memory_order_acq_rel— сочетает в себе эффектыmemory_order_acquireиmemory_order_release(полезно для операций чтения-модификации-записи, таких какatomic_compare_exchange, где необходимо обеспечить видимость изменений до и после операции);std::memory_order_consume— редко используемая модель памяти, предназначенная для операций, зависящих от данных — ограничивает переупорядочивание операций так, чтобы чтение не могло быть выполнено до завершения операций, от которых оно зависит (часто заменяется наmemory_order_acquireиз-за сложности корректной реализации и поддержки компиляторами);std::memory_order_seq_cst— самый строгий порядок. Операции с этой моделью памяти выполняются с полным упорядочиванием относительно другихseq_cstопераций — все потоки видят операции в одном и том же порядке (обеспечивает наибольшие гарантии порядка, но может быть менее производительным по сравнению с более слабыми порядками).
В зависимости от типа данных, используемого в шаблоне, доступны следующие методы:
- Для целых и указателей (со стандарта C++11), а также вещественных (со стандарта C++20):
fetch_add— атомарная сумма, возвращающая предыдущее значение.fetch_sub— атомарная разность, возвращающая предыдущее значение.operator+=— атомарная сумма, возвращающая результат суммы.-
operator-=— атомарная разность, возвращающая результат разности. -
Для целых и указателей:
operator++— префиксный и суффиксный атомарный инкремент.-
operator--— префиксный и суффиксный атомарный декремент. -
Только для целых:
fetch_and— атомарное побитовое И, возвращающее предыдущее значение.fetch_or— атомарное побитовое ИЛИ, возвращающее предыдущее значение.fetch_xor— атомарное побитовое исключающее ИЛИ, возвращающее предыдущее значение.operator&=— атомарное побитовое И, возвращающее результат операции.operator|=— атомарное побитовое ИЛИ, возвращающее результат операции.operator^=— атомарное побитовое исключающее ИЛИ, возвращающее результат операции.
Мьютексы#
Мьютексы («mutual exclusion» — взаимное исключение) используются для обеспечения взаимного исключения, что позволяет предотвратить одновременный доступ к общим ресурсам в многопоточных приложениях. Они представляют собой блокировку, которая может находиться в одном из двух состояний: заблокированном и разблокированном.
Мьютексы предоставляют механизм блокировки, который позволяет потокам последовательно получать доступ к общему ресурсу. Когда поток захватывает мьютекс, другие потоки не могут получить доступ к защищенному им ресурсу до тех пор, пока первый поток не освободит мьютекс.
Доступны с C++11. Требуется подключить заголовочный файл <mutex>
В C++ есть несколько типов мьютексов:
- std::mutex — самый простой мьютекс, который блокирует доступ к ресурсу и не позволяет одному потоку захватывать его несколько раз.
- std::recursive_mutex — позволяет одному потоку захватывать мьютекс несколько раз, предотвращая возникновение взаимных блокировок.
- std::timed_mutex и std::recursive_timed_mutex — позволяют пытаться захватить мьютекс в течение ограниченного времени, предотвращая бесконечное ожидание блокировки.
Пример использования простого мьютекса:
#include <iostream>
#include <mutex>
#include <thread>
// Глобальная переменная и мьютекс
int shared_data = 0;
std::mutex mtx;
// Функция потока
void thread_function()
{
// Блокировка мьютекса
mtx.lock();
// Критическая секция
shared_data++;
std::cout << "Поток: shared_data = " << shared_data << '\n'; // Тут не будет состояния гонки в вычислении операторов<< для std::cout
// Разблокировка мьютекса
mtx.unlock();
}
int main()
{
std::thread threads[2];
// Создание потоков
for (int i = 0; i < 2; i++)
threads[i] = std::thread(thread_function);
// Ожидание завершения потоков
for (int i = 0; i < 2; i++)
threads[i].join();
return 0;
}
Пример использования мьютекса с блокировкой по времени:
std::timed_mutex tmtx;
// Функция потока
void thread_function()
{
if (tmtx.try_lock_for(std::chrono::seconds(10)))
{
// Блокировка на 10 секунд в течении которых мьютекс стал доступен
// Критическая секция
tmtx.unlock();
}
else
{
// Мьютекс не был захвачен в течение 1 секунды
}
}
Не рекомендуется использовать класс std::mutex напрямую, так как на плечи разработчика ложится задача ручного освобождения мьютекса (в том числе при выдаче исключений). Существует четыре шаблонных класса-обертки над мьютексами, позволяющие оптимизировать работу с ними — мьютекс занят, пока существует объект класса-обертки:
- std::lock_guard — захватывает мьютекс при создании объекта и автоматически освобождает его при уничтожении объекта (не предоставляет явного способа освобождения мьютекса или повторного его захвата);
- std::unique_lock — позволяет не только автоматически захватывать и освобождать мьютекс, но и предоставляет возможность для ручного управления мьютексом (используется условными переменными);
- std::shared_lock (со стандарта C++14) — позволяет множеству потоков безопасно и одновременно читать данные, защищенные мьютексом, при этом гарантируя исключительный доступ для потока, выполняющего запись;
- std::scoped_lock (со стандарта C++17) — предназначен для замены std::lock_guard и std::unique_lock при необходимости одновременного захвата нескольких мьютексов — автоматически и безопасно управляет множеством мьютексов, предотвращая взаимные блокировки и упрощая синхронизацию в сложных многопоточных приложениях.
Рассмотрим данные виды оберток над мьютексами подробнее.
std::lock_guard является одной из наиболее простых и безопасных оберток — захватывает мьютекс, пока существует объект, что может быть удобно как для работы с условными операторами, так и для безопасного освобождения мьютекса при выходе из функции потока.
Пример использования std::lock_guard:
#include <iostream>
#include <thread>
#include <mutex>
#define N_THREADS 10
std::mutex mtx;
void print_id(int id)
{
// Небезопасная секция
// ...
// Блок кода после lock_guard автоматически защищен мьютексом
std::lock_guard<std::mutex> lock(mtx);
std::cout << "Поток " << id << " работает в безопасной секции\n"; // Тут не будет состояния гонки в вычислении операторов<< для std::cout
std::this_thread::sleep_for(std::chrono::seconds(1)); // Задержка во времени
// Мьютекс автоматически освободится при выходе из блока (в данном случае функции)
}
int main()
{
std::thread threads[N_THREADS];
// Создание потоков
for (int i = 0; i < N_THREADS; i++)
threads[i] = std::thread(print_id, i);
// Ожидание завершения потоков
for (int i = 0; i < N_THREADS; i++)
threads[i].join();
return 0;
}
Важное замечание: std::lock_guard занимает мьютекс только после создания объекта, а до этого момента блок кода является не потокобезопасным.
std::unique_lock позволяет использовать методы для явного управления мьютексом. Конструктор класса принимает в качестве аргументов:
- ссылку на мьютекс (если ссылка не указана, то позднее требуется создать новый объект во избежание исключений);
- параметр захвата мьютекса:
- таймаут захвата — при создании объекта происходит попытка блокировки мьютекса в течение заданного времени, если мьютекс не становится доступным в течение данного времени, то поток не блокируется;
- попытка захвата мьютекса — при создании объекта происходит попытка захвата мьютекса, если тот свободен — происходит его захват;
- отложенный захват мьютекса — при создании объекта мьютекс не будет захвачен (до момента вызова методов
lockилиtry_lock).
Проверить захват мьютекса можно с помощью метода owns_lock. Также у класса перегружен operator bool, что позволяет использовать объект в условных конструкциях без вызова метода owns_lock.
Объекты std::unique_lock являются перемещаемыми. Владение мьютексом может передаваться между экземплярами std::unique_lock путем перемещения.
Для перемещения необходимо использовать функцию: std::move
Пример различных конструкторов:
std::unique_lock<std::mutex> ul1; // объект без управления мьютексом - вызовет ошибку в случае вызова ul1.lock();
std::unique_lock<std::mutex> ul2(mutex2); // объект с захватом мьютекса, когда он станет доступен (поток спит до этого момента)
std::unique_lock<std::mutex> ul3(mutex3, std::chrono::milliseconds(300)); // объект пытается захватить мьютекс на протяжении 300мс
if (ul3) // проверка блокировки без вызова метода owns_lock
{ ... }
std::unique_lock<std::mutex> ul4(mutex4, std::try_to_lock); // объект пытается захватить мьютекс, если он занят - продолжает без его блокировки
if (ul4.owns_lock()) // проверка блокировки с вызовом метода owns_lock
{ ... }
std::unique_lock<std::mutex> ul5(mutex5, std::defer_lock); // объект не пытается захватить мьютекс
Пример использования std::unique_lock в потоках:
#include <iostream>
#include <sstream>
#include <mutex>
#include <thread>
#define N_THREADS 10
std::mutex mtx; // Глобальный мьютекс
void perform_task(int id)
{
std::unique_lock<std::mutex> ul(mtx, std::defer_lock); // Создаем объект lock, но не захватываем мьютекс сразу
// Некоторые операции, которые не требуют защиты мьютексом
std::cout << (std::stringstream() << "Поток " << id << " работает без блокировки мьютекса\n").str();
ul.lock(); // Явно захватываем мьютекс
std::cout << (std::stringstream() << "Поток " << id << " захватил мьютекс\n").str();
// Выполнение критической секции, требующей защиты мьютексом
std::this_thread::sleep_for(std::chrono::seconds(1)); // Имитация длительной операции
std::cout << (std::stringstream() << "Поток " << id << " освобождает мьютекс\n").str();
ul.unlock(); // Явное освобождение мьютекса
// Продолжение работы после критической секции без мьютекса
std::cout << (std::stringstream() << "Поток " << id << " заканичивает работу\n").str();
}
int main()
{
std::thread threads[N_THREADS];
// Создание потоков
for (int i = 0; i < N_THREADS; i++)
threads[i] = std::thread(perform_task, i);
// Ожидание завершения потоков
for (int i = 0; i < N_THREADS; i++)
threads[i].join();
return 0;
}
std::shared_lock обычно используется в совокупности с std::shared_mutex (со стандарта C++17), что в свою очередь требует учета стандарта C++17. Данная конструкция необходима для секций чтения критических данных (читать можно нескольким потокам), а для секции записи критических данных (писать можно только одному потоку): std::unique_lock или std::lock_guard.
Пример использования std::shared_lock и std::unique_lock с std::shared_mutex в классе потокобезопасного счетчика:
#include <iostream>
#include <sstream>
#include <mutex>
#include <shared_mutex>
#include <thread>
#define N_THREADS 5
class ThreadSafeCounter
{
public:
// Увеличивает значение счетчика
int increment()
{
std::unique_lock lock(mtx);
return ++value;
}
// Получает текущее значение счетчика
int get() const
{
std::shared_lock lock(mtx);
return value;
}
private:
mutable std::shared_mutex mtx;
int value = 0;
};
void reader(ThreadSafeCounter& counter, int id)
{
int value;
for (int i = 0; i < 5; i++)
{
std::this_thread::sleep_for(std::chrono::milliseconds(100));
value = counter.get();
std::cout << (std::stringstream() << "Текущее значение в потоке " << id << ": " << value << '\n').str();
}
}
void writer(ThreadSafeCounter& counter)
{
int value;
for (int i = 0; i < 5; i++)
{
std::this_thread::sleep_for(std::chrono::milliseconds(100));
value = counter.increment();
std::cout << (std::stringstream() << "Икремент изменил значение на: " << value << '\n').str();
}
}
int main()
{
ThreadSafeCounter counter;
std::thread threads[N_THREADS];
// Запускаем несколько потоков-чтецов
for (int i = 0; i < N_THREADS; i++)
threads[i] = std::thread(reader, std::ref(counter), i);
// Запускаем поток-записыватель
std::thread threadW(writer, std::ref(counter));
// Ждем завершения всех потоков
for (auto& t : threads)
t.join();
threadW.join();
return 0;
}
Важное замечание: для использования мьютексов в методах, квалифицированных как const, требуется добавить ключевое слово mutable, что позволит const-методам блокировать мьютекс.
std::scoped_lock (со стандарта C++17) используется в ситуации, когда требуется одновременный захват нескольких мьютексов, предотвращая взаимные блокировки (deadlock).
ример использования std::scoped_lock для одновременного захвата двух мьютексов:
#include <iostream>
#include <thread>
#include <mutex>
#define N_THREADS 5
std::mutex mtx1;
std::mutex mtx2;
void threadFunction(int id)
{
for (int i = 0; i < 5; i++)
{
{
std::scoped_lock lock(mtx1, mtx2); // Одновременное захватывание нескольких мьютексов
std::cout << "Поток " << id << ": итерация " << i << std::endl;
}
std::this_thread::sleep_for(std::chrono::milliseconds(100));
}
}
int main()
{
std::thread threads[N_THREADS];
for (int i = 0; i < N_THREADS; i++)
threads[i] = std::thread(threadFunction, i);
for (auto& thread : threads)
thread.join();
return 0;
}
Семафоры#
Семафор — примитив синхронизации работы процессов и потоков, в основе которого лежит счётчик, над которым можно производить две атомарные операции: увеличение и уменьшение значения на единицу.
Семафоры были добавлены в стандарте C++20:
- бинарные семафоры (
std::binary_semaphore) — могут пропустить только один поток в критическую секцию; - семафор со счетчиком (
std::counting_semaphore) — позволяют пропускать в критическую секцию N потоков.
Основные методы семафоров:
acquire— захватывает семафор, уменьшая счетчик (если счетчик равен нулю — поток блокируется);release— освобождает семафор, увеличивая счетчик (если есть заблокированный поток — он просыпается);try_acquire— неблокирующая попытка захвата счетчика, возвращает true в случае успешного захвата.
В отличие от мьютексов семафоры не привязаны к потокам выполнения — acquire и release могут быть вызваны в разных потоках.
Начальное значение передается параметром в конструкторе.
Пример использования бинарного семафора:
#include <iostream>
#include <thread>
#include <semaphore>
std::binary_semaphore sem(1); // Создаем бинарный семафор, инициализированный в состояние "открыт"
void worker(int id)
{
sem.acquire(); // Захватываем семафор (блокируем доступ к ресурсу)
std::cout << "Поток " << id << " работает\n";
std::this_thread::sleep_for(std::chrono::milliseconds(4000)); // Симуляция работы
std::cout << "Поток " << id << " закончил\n";
sem.release(); // Освобождаем семафор (разблокируем доступ к ресурсу)
}
int main()
{
std::thread t1(worker, 1);
std::thread t2(worker, 2);
t1.join();
t2.join();
return 0;
}
Пример использования семафора со счетчиком:
#include <iostream>
#include <sstream>
#include <thread>
#include <semaphore>
#define N_THREADS 5
std::counting_semaphore<3> sem(3); // Создаем счетный семафор с максимальным значением 3
void worker(int id)
{
sem.acquire(); // Захватываем семафор (уменьшаем счетчик)
std::cout << (std::stringstream() << "Поток " << id << " работает\n").str();
std::this_thread::sleep_for(std::chrono::milliseconds(4000)); // Симуляция работы
std::cout << (std::stringstream() << "Поток " << id << " закончил\n").str();
sem.release(); // Освобождаем семафор (увеличиваем счетчик)
}
int main()
{
std::thread threads[N_THREADS];
for (int i = 0; i < N_THREADS; i++)
threads[i] = std::thread(worker, i);
for (auto& t : threads)
t.join();
return 0;
}
Условные переменные (Condition variables)#
Условные переменные представляют собой механизм синхронизации, который позволяет потокам приостанавливать выполнение до тех пор, пока не наступит определённое условие. Условные переменные используются в сочетании с мьютексами для координации действий между несколькими потоками, позволяя одним потокам ждать («спать»), пока другие потоки не изменят состояние программы и не сигнализируют об этом.
Условные переменные используются для блокировки потока до тех пор, пока не наступит определенное условие. Они тесно связаны с мьютексами и часто используются для ожидания определенных условий выполнения задач.
std::condition_variable предназначена для использования с std::unique_lock<std::mutex>.
#include <iostream>
#include <mutex>
#include <condition_variable>
#include <thread>
#include <unistd.h>
// Глобальные переменные
std::mutex mtx;
std::condition_variable cv;
bool ready = false; // Условие, на котором основано ожидание
// Функция потока, ожидающего события
void waiting_thread()
{
std::unique_lock<std::mutex> lck(mtx);
while (!ready)
{
std::cout << "Ожидающий поток: ждем сигнала...\n";
cv.wait(lck);
}
std::cout << "Ожидающий поток: получен сигнал.\n";
}
// Функция потока, посылающего сигнал
void signaling_thread()
{
sleep(1); // Имитация работы
std::unique_lock<std::mutex> lck(mtx);
ready = true;
std::cout << "Сигнализирующий поток: выдаем сигнал.\n";
cv.notify_all();
}
int main()
{
std::thread w_thread(waiting_thread);
std::thread s_thread(signaling_thread);
w_thread.join();
s_thread.join();
return 0;
}

Источники в ходе составления#
- Соснин В.В., Балакшин П.В., Шилко Д.С., Пушкарев Д.А., Мишенёв А.В., Кустарев П.В., Тропченко А.А. Введение в параллельные вычисления. – СПб: Университет ИТМО, 2023. – 128 с.
- Введение в многопоточность: теория История и теория по многопоточности в программировании https://rekovalev.site/multithreading-1/
- Введение в многопоточность: C++ Работа с многопоточностью в языке C++ с использованием стандартной библиотеки шаблонов (STL) https://rekovalev.site/multithreading-3-cpp/#threads-create