Введение в параллелизацию#
Рассмотрим следующую программу, в которой считается сумма одномерного целочисленного массива:
#pragma GCC optimize("O3")
// ^ включает самый "агрессивный" уровень оптимизации
// то же самое, что добавить флаг "-O3" при компиляции из консоли
#include <iostream>
using namespace std;
const int n = 1e5;
int a[n], s = 0;
int main() {
for (int t = 0; t < 100000; t++)
for (int i = 0; i < n; i++)
s += a[i];
return 0;
}
Если скомпилировать этот код под GCC без всяких дополнительных настроек и запустить, он отработает за 6.03 секунды.
Добавим теперь следующую магическую директиву в самое начало программы:
#pragma GCC target("avx2")
// ...остальное в точности как было
Скомпилировавшись и запустившись при тех же условиях, программа завершается уже за 0.84 секунды. Это почти в несколько раз быстрее, при том, что сам код и уровень оптимизации мы не меняли.
Чтобы понять, что здесь происходит, нам нужно сначала разъяснить некоторые особенности работы современных компьютеров.
Устройство процессора#
В ходе развития компьютерных технологий были разработаны различные вычислительные системы. Многие из них забыты, а влияние некоторых было весьма значимым. Наметились стратегические тенденции в развитии вычислительной техники и сформировались компьютерные архитектуры. На текущий момент существует несколько основных архитектур и значительное количество процессоров на их основе.
Процессорную архитектуру можно трактовать как комбинацию вычислительной архитектуры и её реализацию в процессоре (в кремнии), то есть рассматривать в аспекте программирования и аппаратно-технических (и технологических) решений. Нужно отметить, что кардинальное отличие архитектур и их несовместимость обнаруживаются именно на уровне машинного кодирования или низкоуровневого программирования (ассемблирования).
С программной точки зрения, процессорная архитектура определяет набор регистров, команд, их структуру и способ выполнения, в результате чего, с одной стороны, программы, собранные для процессоров одной архитектуры, могут выполняться практически на всех процессорах одинаковой (или подобной) архитектуры, а с другой – не смогут работать на процессорах иной архитектуры. Для работы на разных платформах производители программного обеспечения вынуждены выпускать специально скомпилированные (или портированные – перенесённые) для них версии. Примером может служить операционная система Ubuntu Server (ядро Linux), для которой производитель, компания Canonical, кроме основной версии для архитектуры Intel x86 (AMD64), выпустила версии для архитектур ARM, IBM Power и s390x. Также в качестве примера можно привести компанию Microsoft, которая изначально распространяла операционную систему Windows исключительно для архитектуры x86, но с недавнего времени, следуя требованиям рынка и отрасли, объявила о сотрудничестве с компанией Qualcomm и выпустила версию операционной системы Windows 10, работающую на устройствах с процессорами архитектуры ARM (Qualcomm Snapdragon 835). Из российских ОС следует отметить многоплатформенную операционную систему Astra Linux Special Edition компании АО «НПО РусБИТех», которая существует в версиях для архитектур x86-64 (релиз «Смоленск»), ARM (релиз «Новороссийск»), MIPS (релиз «Севастополь»), IBM System Z (релиз «Мурманск»), POWER (релиз «Керчь») и «Эльбрус» (релиз «Ленинград»).
С аппаратной точки зрения, архитектура процессора – это набор составных частей, компонентов и технологий, присущих линейке процессоров. Аппаратная часть постоянно совершенствуется, как по микроархитектуре, так и по технологическому процессу. Выпускаются новые поколения процессоров с целью увеличения производительности и функциональности. Так, на рынке существуют процессоры Intel нескольких поколений: Coffee Lake (восьмое поколение), Kaby Lake (седьмое поколение), Skylake (шестое поколение) и другие. Несмотря на смену микроархитектуры (аппаратной части), они остаются программной архитектурой x86, и на них работает всё ранее написанное для этой архитектуры программное обеспечение, за некоторым исключением, если разработчик ПО использовал недокументированные методы, вызовы и процедуры.
Поэтому, с точки зрения практического применения процессоров, основной является программная архитектура. На текущий момент актуальные и распространённые архитектуры – это CISC, RISC, VLIW.
Логика исторического развития#
Три архитектуры эльфам, семь гномам, девять людям…
Раньше, во времена, когда компьютеры назывались ЭВМ-ами и занимали целую комнату, увеличение производительности происходило в основном за счёт увеличения тактовой частоты. Тактовая частота условно равна количеству инструкций, выполняемому процессором за единицу времени. (На современных процессорах это не так — разные инструкции занимают разное время, которое ещё и может зависеть от разных обстоятельств.)
Помимо жесткого физического ограничения на максимально возможную тактовую частоту, такой подход в какой-то момент просто перестал быть экономически оправданным: прямое увеличение тактовой частоты приводит к более чем линейному потреблению энергии, и, следовательно, выделению тепла, которое к тому же нужно ещё как-то выводить.
Поэтому вендоры, в погоне за более дешёвым флопсом за доллар, пошли по другому пути: стали добавлять более сложные инструкции, которые делают сразу много полезных действий за раз. Но есть и недостаток: микросхема от добавления новых инструкций сильно усложняется, что может стать критичным во многих других применениях. В связи с этим, все архитектуры стали делиться на два типа:
-
RISC (англ. reduced instruction set computer), в которых длина кода (идентификатора) самой инструкции ограничена, а значит ограничено и само количество инструкций. Самые первые компьютеры относились к этому типу и могли не иметь даже отдельных инструкций для умножения и деления. Такие процессоры требуют меньше транзисторов, и как следствие сами меньше, дешевле и потребляют меньше энергии. Самое популярное семейство архитектур называется arm и используется почти на всех современных мобильных устройствах.
-
CISC (англ. complex instruction set computer), к которому относят всё, что не RISC — в них длина команды не фиксирована, что позволяет поддерживать практически произвольное количество инструкций. Самое популярное семейство архитектур называется x86 и используется почти на всех современных десктопах и серверах.
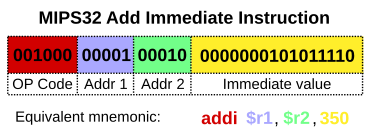
Архитектура CISC (Complex Instruction Set Computer)#
Первоначально почти все производители первых микропроцессоров использовали архитектуру с расширенным набором команд – CISC (Complex Instruction Set Computer). Причина этого заключалась в попытке уменьшить так называемый семантический разрыв между тем, что компьютеры способны делать, и тем, что требуют языки программирования высокого уровня, пытаясь заменить одной инструкцией многочисленные машинные коды.
Также в то время на рынке коммерческих вычислений доминировали мини-компьютеры PDP компании DEC и мейнфреймы компании IBM, которые были основаны на архитектуре CISC. Среди микропроцессоров типичными представителями данной архитектуры стали процессоры компании Intel.
На начальном этапе развития микропроцессоров (семидесятые годы прошлого века) существовали и другие процессоры подобной архитектуры производства компаний Motorola, Zilog, MOS Technology и т.д. Но именно благодаря коммерческой привлекательности микропроцессоров Intel эта архитектура стала самой популярной на текущий момент и практически единственной для персональных компьютеров. Даже компания Apple в своих компьютерах Apple Macintosh в итоге перешла от процессоров PowerPC к процессорам Intel.
Первый процессор Intel, обозначивший начало эпохи микропроцессоров, – микросхема Intel 4004 – появился в 1971 году.

Это был первый коммерческий процессор, реализованный в одной микросхеме. Следует отметить, что сотрудники Intel не догадывались, какое грандиозное открытие они совершили. Эта микросхема вызвала большой интерес и значительный спрос. Компания Intel стала наращивать функциональность, разрядность и повышать частоту микропроцессора.
В 1978 году был представлен 16-битный процессор Intel 8086, положивший начало архитектуре x86, или Intel x86. Популярность микроархитектуры х86 была столь велика, что аналогичные процессоры стали выпускать другие производители.
В 1985 году компания Intel выпустила первый 32-битный процессор Intel 386.

Таким образом сформировалось понятие архитектуры Intel Architecture 32-bit (IA-32), она же Intel x86, или просто x86. В дальнейшем она стала 64-битной и получила название x86-64, или AMD64, так как впервые 64-битное расширение архитектуры x86 представила компания AMD. Нужно отметить, что Intel x86 не следует путать с Intel Architecture 64-bit (IA-64), которая является принципиально другой архитектурой VLIW, о чём будет сказано позже.
Формально все процессоры x86 являются процессорами CISC-архитектуры.
Итак, x86 – это типичный представитель CISC-архитектуры. Таким образом, в современной интерпретации, говоря CISC, подразумеваем x86, и наоборот.
Для архитектуры CISC характерно:
1. Малое количество регистров общего назначения;
2. Большое количество различных машинных команд, каждая из которых выполняется за несколько тактов процессора;
3. Различные форматы команд с разной длиной;
4. Преобладание двухадресной системы команд;
5. Развиты механизмы адресации операндов.
Основными плюсами данной архитектуры можно считать:
- Простоту и эффективность программирования (несколько команд могут быть заменены одной более сложной),
- Большое историческое наследие в виде множества написанных для неё программ.
Данная архитектура на текущий момент является основной для настольных и серверных систем.
Архитектура RISC#
Повышение производительности CISC-микропроцессоров из-за особенностей архитектуры приводило к росту количества транзисторов, в результате чего кристаллы становились всё более сложными и дорогостоящими в производстве. Вопросы закрывались конструктивно-технологическими решениями, но в конечном итоге по экономическим соображениям уже не давали адекватного роста производительности.
CISC-архитектура в первозданном своём виде достигла потолка производительности. Применение конвейера для повышения производительности требовало использования простых и быстрых команд. Необходимость дальнейшего роста производительности привела к использованию архитектуры RISC (Reduced Instruction Set Computer), что означает «компьютер с сокращённым набором команд».
Архитектура была разработана в рамках проекта Berkeley RISC. В 1980 году группа разработчиков приступила к созданию процессора, не ориентированного на интерпретацию, в котором инструкции должны выполняться процессорным ядром без использования микрокода. Исследования работы процессора Motorola 68000 показали, что программы попросту не использовали подавляющее большинство инструкций, заложенных в процессор. Работал принцип 80/20, то есть большее время выполнения типовых программ (80–90%) приходится на относительную малую часть команд процессора (10–20%).
Планировалось создать процессор, который бы содержал лишь самые необходимые инструкции. При этом не только уменьшилось общее количество процессорных инструкций, принципиальное отличие заключается в том, что любая инструкция платформы RISC является простой и выполняется за один такт (по крайней мере, должна выполняться), тогда как на выполнение CISC-инструкции могло уходить несколько десятков тактов. При этом длина команды является фиксированной.
Основные особенности RISC-процессоров:
1. Сокращённый набор команд.
- Первый «настоящий» RISC-процессор имел всего 31 команду. В дальнейшем их количество постепенно росло и достигло 100–200 инструкций в зависимости от реализации процессора. Но это всё равно в несколько раз, а то и на порядок меньше инструкций CISC-процессоров.
- Большинство команд выполняется за один такт.
-
Все команды выполняются непосредственно аппаратным обеспечением, то есть напрямую без интерпретации микрокомандами. Устранение уровня интерпретации повышает скорость выполнения команд. В компьютерах типа CISC более сложные команды разбиваются на несколько шагов, которые потом выполняются как последовательность микрокоманд.
-
Большое количество регистров общего назначения.
-
Доступ к памяти происходит относительно медленно. Если слово было загружено из памяти, оно может храниться в регистрах до тех пор, пока не потребуется. Возвращение слова из регистра в память весьма нежелательно, и лучший способ избежать лишних изменений – это наличие достаточного количества регистров.
-
Наличие жёстких многоступенчатых конвейеров.
-
Компьютер должен запускать как можно большее количество команд в секунду. Важным фактором повышения производительности является параллелизм, поскольку запустить на выполнение большое количество команд за короткий промежуток времени можно только в случае, если есть возможность одновременного выполнения нескольких команд. Параллелизм на уровне команд (одновременный запуск) обеспечивается многоступенчатыми конвейерами.
-
Все команды имеют простой формат, и используются немногие способы адресации.
-
Команды легко декодируются, и к памяти обращаются только команды загрузки и сохранения.
-
Наличие вместительной раздельной кэш-памяти.
-
Это необходимо для уменьшения обращений к памяти и тем самым обеспечения необходимого быстродействия для заполнения регистров и конвейеров.
-
Использование оптимизирующих компиляторов, которые анализируют исходный код и частично меняют порядок следования команд.
- Упрощение набора команд призвано сократить конвейер, что позволяет избежать задержек на операциях условных и безусловных переходов. Однородный набор регистров упрощает работу компилятора при оптимизации исполняемого программного кода.
Кроме того, RISC-процессоры отличаются меньшим энергопотреблением и тепловыделением.
Уже первые микропроцессоры RISC значительно опережали процессоры CISC по производительности. Учитывая это, можно было предположить, что они должны были занять доминирующее положение на рынке. Но этого не произошло, по крайней мере, по двум причинам:
1. Компьютеры RISC несовместимы с архитектурой Intel x86, а многие компании уже вложили значительные средства в программное обеспечение для продукции Intel.
2. Компания Intel сумела воплотить те же идеи в своей архитектуре.
Столкнувшись с ограничениями по повышению производительности, компания Intel в процессоре следующего поколения Intel 486 применила RISC-ядро и добавила другие элементы RISC-архитектуры, такие как кэш-память и конвейеры. Теперь процессорное ядро стало выполнять самые простые (и обычно самые распространённые) команды за один цикл, а по обычной технологии CISC интерпретируются более сложные команды. В результате обычные команды выполняются быстро, а более сложные и редкие – медленно.
Хотя при таком смешанном подходе производительность ниже, чем в архитектуре RISC, новая архитектура CISC имеет ряд преимуществ, поскольку, с одной стороны, появилась возможность повышения производительности, а с другой, можно использовать старое программное обеспечение без изменений.
Реализациями RISC-архитектуры являются процессоры ARM, MIPS, PowerPC, SPARC и R1000 – российский процессор с 64-битной архитектурой SPARC v.9 производства АО «МЦСТ».
Введение к векторым операцияи#
В обычных CPU довольно быстро добавили инструкцию, которая принимает числа и загружает в регистр данные по адресу. Это полезно при индексации массивов — не нужно отдельно индекс считать.
На графических сопроцессорах появилась отдельная инструкция, которую называют «saxpy» (сокращенно от выражения s += a * x + y), которая полезна, например, при перемножении матриц.
В последние GPU от Nvidia добавили «tensor core» — отдельную схему, которая перемножает две матрицы и прибавляет к третьей, как бы производя умножений и сложений за раз, что сильно ускоряет алгоритмы блочного матричного умножения.
В этой лекции мы сфокусируемся на отдельном виде инструкций, которые позволяют выполнять одну и ту же операцию сразу на какой-то последовательности данных. Эта концепция называется SIMD-параллелизмом (single instruction, multiple data).
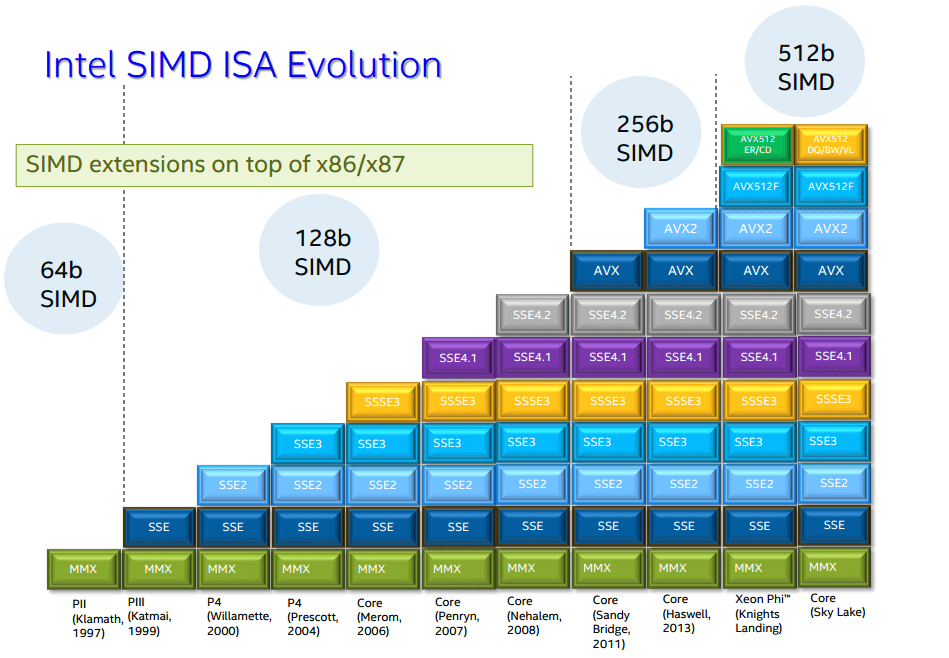
Стоит отметить, что поддержка SIMD-инструкций добавлялись постепенно, сохраняя обратную совместимость. Если третий пентиум в 1999-м году умел работать с регистрами размера 128, то в самых современных i7 есть 512-битные регистры. Автор не является специалистом в проектировании микропроцессоров, но предполагает, что регистры больше 64 байт (512 бит) появятся не скоро, потому что это уже больше размера кэш-линии
Инструкции и регистры#
Векторные вычисления — такие вычисления, когда при выполнении одной инструкции процессора производится одновременно несколько однотипных операций. Этот принцип в настоящее время реализован не только в специализированных процессорах, но и в процессорах архитектуры x86 и ARM в виде векторных расширений. Эти расширения представляют собой специальные векторные регистры с повышенной относительно регистров общего назначения разрядностью. Для работы с этими регистрами имеются специальные векторные инструкции, которые дополняют систему инструкций процессора.
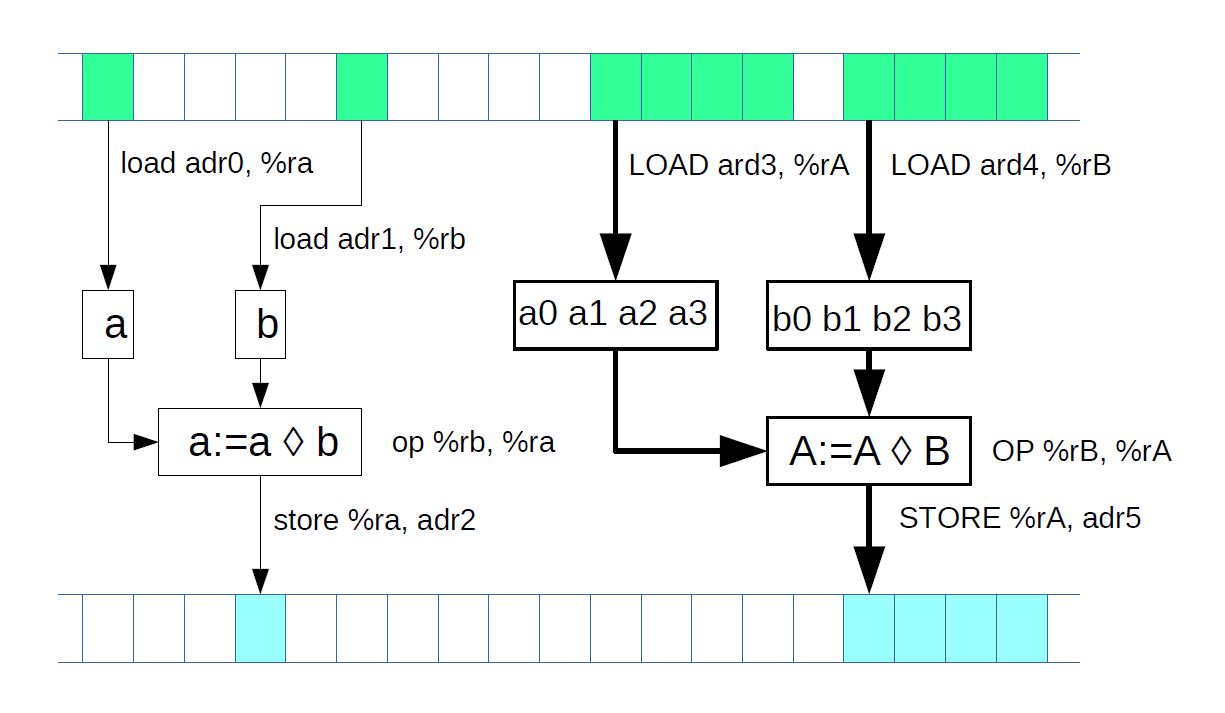
Как правило, векторные инструкции реализуют те же операции, что и скалярные (обычные) инструкции (см. рис), но благодаря большому объёму обрабатываемых данных производительность этих инструкций выше. Если для регистра общего назначения при выполнении некоторой инструкции предполагается, что в нём находится только одна порция данных определённого типа (целое число определённой разрядности, число с плавающей запятой), то в векторном регистре одновременно находится столько независимых порций данных определённого типа, сколько позволяет разместить ёмкость регистра. И такое же количество одновременных независимых операций может быть произведено над этими данными при выполнении векторной инструкции — и во столько же раз повышается производительность вычислений. Повысить производительность процессора, выполняя несколько одинаковых операций одновременно, — основная задача векторных расширений.
В процессорах архитектуры x86 первым векторным расширением был набор инструкций MMX, оперирующих восемью 64-битными регистрами MM0-MM7. MMX сменили более производительные 128-битные инструкции SSE (инструкции для работы с числами с плавающей запятой) и SSE2 (целочисленные инструкции и инструкции для работы с числами с плавающей запятой двойной точности), оперирующие регистрами xmm0-xmm7. Позже появились наборы 128-битных инструкций SSE3, SSSE3, SSE4.1 и SSE4.2, которые дополнили SSE и SSE2 несколькими полезными инструкциями. Большинство инструкций из перечисленных наборов используют два регистра-операнда, результат записывается в один из этих регистров, а его первоначальное содержимое теряется.
Следующий шаг в развитии векторных расширений — ещё более производительные 256-битные инструкции AVX и AVX2, которые оперируют 256-битными регистрами ymm0-ymm15. Кроме того, эти инструкции используют три регистра-операнда: исходные данные содержатся в двух регистрах, результат операции записывается в третий регистр, а содержимое двух других регистров остаётся неизменным. Новейший на сегодняшний день набор векторных инструкций — AVX-512, который оперирует 32 512-битными регистрами zmm0-zmm31. AVX-512 используется в некоторых серверных процессорах для высокопроизводительных вычислений.
С массовым появлением 64-битных процессоров инструкции MMX признаны устаревшими. Инструкции SSE и SSE2 с появлением AVX и AVX2 не вышли из употребления и продолжают активно использоваться. В процессорах x86 сохраняется обратная совместимость: если процессором поддерживается AVX2, то им поддерживаются и SSE/SSE2, а также SSE3, SSSE3, SSE4.1 и SSE4.2. Аналогично, процессор с поддержкой, например, SSSE3, поддерживает и все более ранние наборы инструкций.
Для процессорной архитектуры ARM разработано векторное расширение NEON. Разрядность векторных инструкций — 64 и 128 бит, которые оперируют тридцатью двумя 64-битными регистрами либо шестнадцатью 128-битными (в ARM64 имеется 32 128-битных регистра).
Поскольку векторные инструкции привязаны к конкретной процессорной архитектуре (а нередко — и к конкретному процессору), то программы, использующие их, становятся непереносимыми. Следовательно, для достижения переносимости необходимо делать несколько реализаций одного и того же алгоритма с использованием разных наборов инструкций.
Интринсики#
Как программист может использовать векторные инструкции? Прежде всего, их можно использовать в ассемблерном коде.
Можно получить доступ к векторным инструкциям и в программе на языке высокого уровня (в частности, C/C++) без ассемблерных вставок. Для этого используются так называемые интринсики (intrinsics) — встроенные объекты компилятора. В заголовочном файле объявлен один или несколько типов данных (с точки зрения программиста, это массив фиксированной длины, но без возможности доступа к элементам этого массива), переменной одного из этих типов соответствует векторный регистр. Также в заголовочном файле объявлены функции, которые принимают аргументы, возвращают значения указанных выше типов и производят с точки зрения программиста те же операции над данными, что и соответствующие им векторные инструкции. В действительности же настоящей программной реализации этих функций не существует: компилятор при генерации объектного кода заменяет вызов функции векторной инструкцией. Таким образом, с помощью интринсиков можно написать программу на языке высокого уровня, близкую или равную по производительности программе, написанной на языке ассемблера.
Для доступа к интринсикам достаточно подключить соответствующий заголовочный файл. Интринсики не являются частью стандартов языков C/C++, но поддерживаются основными компиляторами: GCC, Clang, MSVC, Intel.
Интринсики позволяют также упорядочить работу с разнообразными типами обрабатываемых данных. Важно отметить, что процессору (по крайней мере, в архитектуре x86) недоступна информация о типе данных, содержащихся в регистре. При выполнении той или иной векторной инструкции они интерпретируются как данные определённого, связанного с инструкцией типа: числа с плавающей запятой, целые числа некоторой разрядности со знаком или без знака. Контролировать корректность производимых вычислений при этом должен программист, что требует немалого внимания. Тем более, иногда тип данных может изменяться: например, при целочисленном умножении разрядность произведения равна сумме разрядностей множителей. Интринсики позволяют в некоторой степени упростить задачу.
Так, векторным регистрам xmm (SSE) соответствуют три типа данных [1]:
- __m128 — «массив» из четырёх чисел с плавающей запятой с одинарной точностью;
- __m128d — «массив» из двух чисел с плавающей запятой двойной точности;
- __m128i — 128-битный регистр, который можно рассматривать как «массив» 8-, 16-, 32- и 64-битных чисел.
Поскольку конкретная векторная инструкция работает, как правило, с одним из трёх типов данных (число с плавающей запятой одинарной точности, двойной точности, целочисленный), то и аргументы функций-векторных инструкций имеют один из трёх указанных типов. Подобным образом устроена и система типов AVX2: в ней имеются типы __m256 (с плавающей запятой), __m256d (двойной точности) и __m256i (целочисленный).
Интринсики NEON реализуют ещё более развитую систему типов [2]. 128-битному регистру соответствуют типы int32x4_t, int16x8_t, int8x16_t, float32x4_t, float64x2_t. В NEON имеются и типы данных, содержащие несколько регистров, например int8x16x2_t. В подобной системе в любой момент известны конкретный тип и разрядность содержимого регистра, и меньше вероятность допустить ошибку там, где преобразуется тип данных и меняется их разрядность.
Приведём пример простой функции, реализованной с помощью набора инструкций SSE2.
// 1.2.1: Example of SSE2 intrinsics for int32_t
#include <stdint.h>
// for SSE2 intrinsics
#include <emmintrin.h>
void bar(void)
{
int32_t array_a[4] = {0, 2, 1, 2}; // 128 bit
int32_t array_b[4] = {8, 5, 0, 6};
int32_t array_c[4];
__m128i a, b, c;
a = _mm_loadu_si128((__m128i*)array_a); // loading array_a into register a
b = _mm_loadu_si128((__m128i*)array_b);
c = _mm_add_epi32(a, b); // must be { 8, 7, 1, 8 }
_mm_storeu_si128((__m128i*)array_c, c);
}
В этом примере содержимое массива
array_a загружается в один векторный регистр, а массива array_b — в другой. Затем соответствующие 32-битные элементы регистров складываются, и результат записывается в третий регистр, а затем копируется в массив array_c. В этом примере можно отметить ещё одну особенность интринсиков: _mm_add_epi32 принимает два аргумента-регистра и возвращает одно значение-регистр. Но в действительности инструкция paddd, которой соответствует _mm_add_epi32, имеет только два регистра-операнда, в один из которых записывается результат операции с потерей первоначального содержимого регистра. Чтобы сохранить содержимое регистров при компиляции c = _mm_add_epi32(a, b), компилятор добавляет дополнительные операции копирования из регистра в регистр.
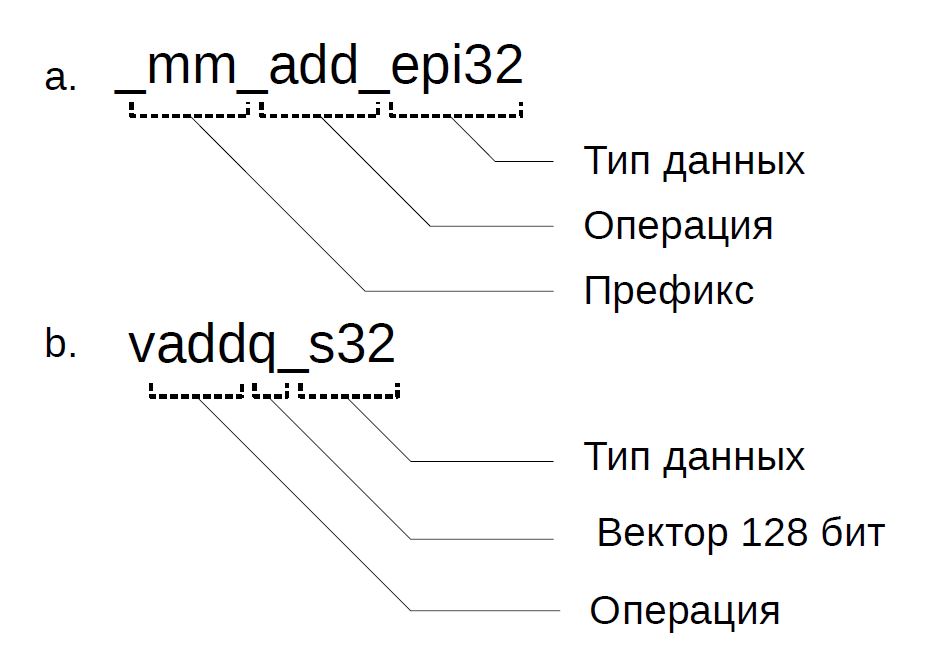
Имена интринсиков выбраны так, чтобы облегчить чтение исходного текста программ. В архитектуре x86 имя состоит из трёх частей: префикса, обозначений операции и типа скалярных данных (рисунок 2, а.). Префикс обозначает разрядность векторного регистра: _mm_ для 128 бит, _mm256_ для 256 бит и _mm512_ для 512 бит соответственно. Обозначения некоторых типов данных приведены в таблице 1. Подобным образом выбраны имена интринсиков и в наборе ARM NEON. Имеется, напомним, два типа векторных регистров (64 и 128-битные), и буква q обозначает, что инструкция специализируется на 128-битных регистрах.
| Обозначение | Описание |
|---|---|
ps |
Число с плавающей запятой одинарной точности |
pd |
Число с плавающей запятой двойной точности |
epi8 |
Целое число, 8 бит, со знаком |
epu8 |
Целое число, 8 бит, без знака |
epi16 |
Целое число, 16 бит, со знаком |
epi32 |
Целое число, 32 бит, со знаком |
epi64 |
Целое число, 64 бит, со знаком |
si128 |
Целое число, 128 бит |
si256 |
Целое число, 256 бит |
Имена типов данных (__m128i и другие) и имена функций-интринсиков фактически стали стандартными в разных компиляторах. Далее в статье векторные инструкции будут именоваться не мнемокодом, а соответствующим им именем интринсика.
Важнейшие векторные инструкции#
В этом разделе рассказывается о важнейших классах инструкций. Приведены примеры часто употребляемых и полезных инструкций в основном из архитектуры x86, но уделено внимание и инструкциям ARM NEON.
Обмен данными с оперативной памятью#
Чтобы процессор произвел какие-либо действия с данными, которые находятся в оперативной памяти, необходимо сначала загрузить эти данные в регистр процессора. А после завершения обработки данные необходимо записать обратно в оперативную память.
Большинство векторных инструкций работает в формате «регистр — регистр», то есть операндами инструкций являются векторные регистры, и в них же записывается результат работы инструкций. Для обмена данными с оперативной памятью есть ряд специализированных инструкций.
- Инструкция
_mm_loadu_si128(__m128i* addr)извлекает из оперативной памяти непрерывный массив целочисленных данных длиной 128 бит с начальным адресомaddrи записывает в выбранный векторный регистр. - Инструкция
_mm_storeu_si128(__m128i* addr, __m128i a)копирует в оперативную память, начиная с адресаaddr, непрерывный массив данных длиной 128 бит, которые содержатся в регистреa. - Инструкции
_mm_load_si128и_mm_store_si128аналогичны приведённым выше, но они требуют, чтобыaddrбыл кратен 16 байтам (выравнен по границе 16 байт), иначе при их выполнении произойдёт аппаратное исключение.
Для загрузки и записи данных с плавающей запятой одинарной и двойной точности (длиной 128 бит) существуют специализированные инструкции:
_mm_loadu_psи_mm_storeu_psдля чисел одинарной точности_mm_loadu_pdи_mm_storeu_pdдля чисел двойной точности
Нередко возникает необходимость загрузить данные в меньшем количестве, чем вмещает векторный регистр. Инструкция _mm_loadl_epi64(__m128i* addr) извлекает из оперативной памяти непрерывный массив данных длиной 64 бит, начиная с адреса addr и записывает их в младшую половину выбранного векторного регистра, биты же старшей половины регистра устанавливает нулевыми. Инструкция _mm_storel_epi64(__m128i* addr, __m128i a), обратная ей, записывает в оперативную память младшие 64 бита регистра a.
Инструкция _mm_cvtsi32_si128(int32_t a) копирует 32 бита целочисленной переменной в младшие 32 бита векторного регистра, остальные биты регистра устанавливаются нулевыми. Напротив, инструкция _mm_cvtsi128_si32(__m128i a) копирует младшие 32 бита регистра в целочисленную переменную.
Логические операции и операции сравнения#
В наборе SSE2 представлены инструкции, выполняющие следующие логические операции:
- «И» —
_mm_and_si128 - «ИЛИ» —
_mm_or_si128 - «исключающее ИЛИ» —
_mm_xor_si128 - «И-НЕ» —
_mm_andnot_si128
Часто используемая инструкция _mm_setzero_si128(), которая устанавливает все биты регистра-приёмника нулевыми, реализована при помощи операции «исключающее ИЛИ», у которой оба операнда — один и тот же регистр.
С логическими инструкциями тесно связаны инструкции сравнения. Эти инструкции сопоставляют друг другу соответствующие элементы двух регистров-источников и проверяют выполнение некоторого условия (равенство либо неравенство). Если условие выполняется, то они устанавливают все биты элемента в регистре-приёмнике равными 1, в противном случае все биты устанавливаются равными 0. Например, инструкция _mm_cmpeq_epi32(__m128i a, __m128i b) проверяет 32-битные элементы регистров a и b на равенство. Результаты проверки нескольких разных условий можно объединить при помощи логических инструкций.
Арифметические операции и сдвиги#
Инструкции, принадлежащие этой группе, несомненно, самые востребованные.
Для вычислений с плавающей точкой и в x86, и в ARM есть инструкции, которые реализуют все четыре арифметические операции и вычисляют квадратный корень для чисел однократной и двойной точности. В x86 для чисел однократной точности эти инструкции следующие:
_mm_add_ps_mm_sub_ps_mm_mul_ps_mm_div_ps_mm_srqt_ps
Приведём простой пример использования арифметических инструкций с плавающей запятой. Здесь, аналогично примеру ранее, суммируются элементы двух массивов src0 и src1, а результат записывается в массив dst. При этом количество элементов, которые необходимо просуммировать, задано параметром len. В том случае, если len не кратно количеству элементов, которые вмещает векторный регистр (в нашем случае это будет четыре и два), часть элементов обрабатывается обычным способом, без векторизации.
// 1.3.1 Sum of elements of two arrays
/* necessary for SSE and SSE2 */
#include <emmintrin.h>
void sum_float( float src0[], float src1[], float dst[], size_t len)
{
__m128 x0, x1; // floating-point, single precision
size_t len4 = len & ~0x03;
for(size_t i = 0; i < len4; i+=4)
{
x0 = _mm_loadu_ps(src0 + i); // loading of four float values
x1 = _mm_loadu_ps(src1 + i);
x0 = _mm_add_ps(x0,x1);
_mm_storeu_ps(dst + i, x0);
}
for(size_t i = len4; i < len; i++)
{
dst[i] = src0[i] + src1[i];
}
}
void sum_double( double src0[], double src1[], double dst[], sizе_t len)
{
__m128d x0, x1; // floating-point, double precision
size_t len2 = len & ~0x01;
for(size_t i = 0; i < len2; i+=2)
{
x0 = _mm_loadu_pd(src0 + i ); //loading of two double values
x1 = _mm_loadu_pd(src1 + i );
x0 = _mm_add_pd(x0,x1);
_mm_storeu_pd(dst + i, x0);
}
if(len2 != len)
{
dst[len2] = src0[len2] + src1[len2];
}
}
Для работы с целочисленными данными некоторой арифметической операции, как правило, есть несколько однотипных инструкций, каждая из которых специализируется на данных определённой разрядности. Например, операции сложения и вычитания. Для 16-битных целых чисел со знаком есть инструкции _mm_add_epi16 и _mm_sub_epi16 (выполняющие сложение и, соответственно, вычитание). Аналогичные им инструкции имеются и для разрядности 8, 32 и 64 бит. То же касается и логического сдвига влево и вправо, который реализован для разрядности 16, 32 и 64 бит (для 16 бит инструкции _mm_slli_epi16 и _mm_srli_epi16 соответственно). Арифметический же сдвиг вправо реализован только для разрядности 16 и 32 бит: это инструкции _mm_srai_epi16 и _mm_srai_epi32.
ARM NEON также предоставляет инструкции для этих операций: для разрядностей 8, 16, 32 и 64 бит как для чисел со знаком, так и без знака.
Инструкции _mm_slli_si128(__m128i a, int imm) и _mm_srli_si128(__m128i a, int imm) интерпретируют содержимое регистра как 128-битное число, которое сдвигают на imm байт (не бит!) влево и, соответственно, вправо.
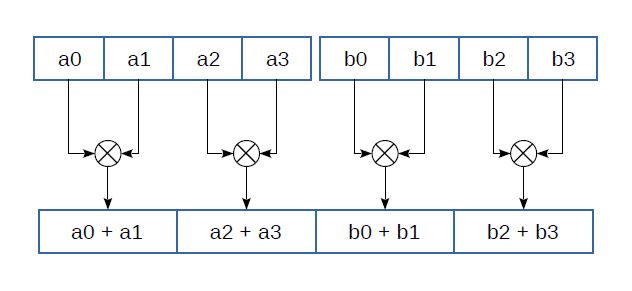
В наборах инструкций SSE3 и SSSE3 появляются инструкции для горизонтального сложения:
_mm_hadd_ps(__m128 a, __m128 b)_mm_hadd_pd(__m128d a, __m128d b)_mm_hadd_epi16(__m128i a, __m128i b)_mm_hadd_epi32(__m128i a, __m128i b)
При горизонтальном сложении складываются соседние элементы одного и того же регистра. Добавлены инструкции и для горизонтального вычитания (_mm_hsub_ps и другие), которые таким же образом производят вычитание. Похожие инструкции, реализующие парное сложение (например, vpaddq_s16(int16x8_t a, int16x8_t b)), есть среди инструкций ARM NEON.
При целочисленном умножении разрядность произведения в общем случае равна сумме разрядностей сомножителей. Тогда, если умножить, например, 16-битные элементы одного регистра на соответствующие элементы другого, то в общем случае результаты произведений получаются 32-битные, и для их размещения потребуется два регистра, а не один.
Инструкция _mm_mullo_epi16(__m128i a, __m128i b) производит умножение 16-битных элементов регистров a и b, и записывает в регистр-приёмник младшие 16 бит 32-битного произведения. Напротив, _mm_mulhi_epi16(__m128i a, __m128i b) записывает в регистр-приёмник старшие 16 бит произведения. Результаты работы этих инструкций можно объединить и получить 32-битные произведения, если воспользоваться инструкциями _mm_unpacklo_epi16 и _mm_unpackhi_epi16, о которых речь пойдёт далее. Разумеется, если сомножители достаточно малы, то достаточно и одной _mm_mullo_epi16.
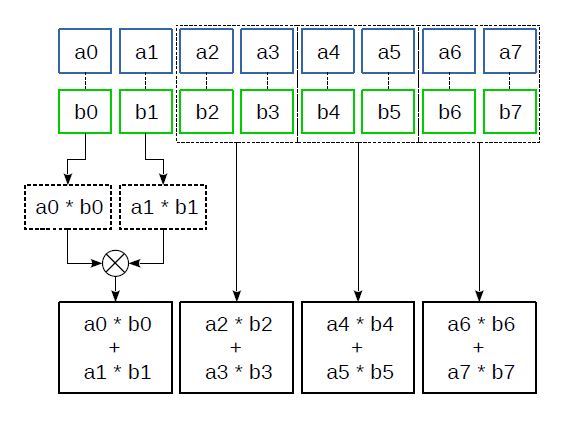
Инструкция _mm_madd_epi16(__m128i a, __m128i b) производит умножение 16-битных элементов регистров a и b, а затем складывает получившиеся соседние 32-битные произведения. Эта инструкция оказывается особенно полезной при реализации всевозможных фильтров, дискретно-косинусных и других преобразований, где требуется много умножений совместно со сложениями: произведения сразу преобразуются в удобный 32-битный формат, а количество необходимых операций сложения сокращается.
Инструкции умножения ARM NEON весьма разнообразны. Имеются инструкции с увеличением разрядности произведения (например, vmull_s16) и без него; инструкции, которые умножают вектор на скаляр (например, vmul_n_f32). Инструкции, подобной _mm_madd_epi16, в наборе NEON нет, зато есть инструкции, выполняющие умножение с накоплением, которое выражается формулой:
C = A * B + C
Подобные инструкции имеются и для архитектуры x86 (набор инструкций FMA), но только для чисел с плавающей запятой.
Что касается векторного целочисленного деления, то оно не реализовано ни в архитектуре x86, ни в ARM.
Перестановка и перемешивание#
Для группы инструкций, о которых далее пойдёт речь, не существует аналогичных скалярных инструкций процессора. При их выполнении не образуются новые значения: либо производится перестановка данных внутри регистра, либо данные, взятые из нескольких регистров-источников, записываются в определённом порядке в регистр-приёмник. На первый взгляд, эти инструкции мало полезны, но в действительности их значение очень велико. Без них многие алгоритмы невозможно реализовать эффективно.
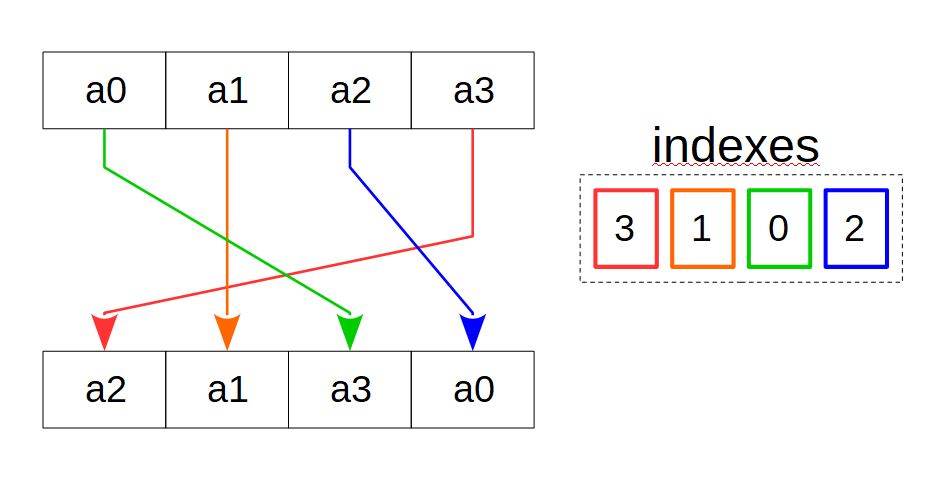
Несколько векторных инструкций в x86 и ARM реализуют копирование по шаблону (рисунок 5). Пусть имеются массив-источник, массив-приёмник, а также массив индексов, количество элементов в котором равно количеству элементов массива-приёмника, и при этом каждый элемент массива индексов соответствует элементу массива-приёмника. Значение элемента массива индексов указывает на тот элемент массива-источника, который нужно скопировать в соответствующий элемент массива-приёмника. Задавая различные индексы, можно осуществить всевозможные перестановки элементов, их дублирование.
В векторных инструкциях в качестве массива-источника и массива приёмника выступают векторные регистры или их группы. В качестве массива индексов может выступать также векторный регистр или же целочисленная константа, группы битов которой соответствуют элементам регистра-приёмника и кодируют элементы источника.
Одна из инструкций, реализующих принцип копирования по шаблону, — инструкция SSE2 _mm_shuffle_epi32(__m128i a, const int im), которая копирует выбранные 32-битные элементы регистра-источника в регистр-приёмник. В качестве массива индексов выступает второй операнд-целочисленная константа, значение которой задаёт шаблон копирования. Инструкция обычно используется совместно со стандартным макросом _MM_SHUFFLE, который делает задание шаблона копирования более наглядным. Например, при выполнении:
a = _mm_shuffle_epi32(b,_MM_SHUFFLE(0,1,2,3));
32-битные элементы b записываются в регистр a в обратном порядке. А при выполнении
a = _mm_shuffle_epi32(b,_MM_SHUFFLE(2,2,2,2));
значения всех элементов регистра a становятся равными одному и тому же значению, а именно значению третьего элемента регистра b.
Инструкции _mm_shufflelo_epi16 и _mm_shufflehi_epi16 работают аналогично, но копируют выбранные 16-битные элементы из младшей и, соответственно, старшей половины регистра, а оставшуюся половину регистра копируют в регистр-приёмник без изменений. Покажем для примера, как с помощью этих инструкций и _mm_shuffle_epi32 можно переставить в обратном порядке 16-битные элементы 128-битного регистра всего за три операции. Вот как это делается:
/ a: a0 a1 a2 a3 a4 a5 a6 a7
a = _mm_shuffle_epi32(a, _MM_SHUFFLE(1,0,3,2)); // a4 a5 a6 a7 a0 a1 a2 a3
a = _mm_shufflelo_epi16(a, _MM_SHUFFLE(0,1,2,3)); // a7 a6 a5 a4 a0 a1 a2 a3
a = _mm_shufflehi_epi16(a, _MM_SHUFFLE(0,1,2,3)); // a7 a6 a5 a4 a3 a2 a1 a0
Сначала меняются местами старшая и младшая половины регистра, а затем 16-битные элементы каждой из половин переставляются в обратном порядке.
Инструкция _mm_shuffle_epi8(__m128i a, __m128i i) из набора SSSE3 тоже осуществляет копирование по шаблону (правда, регистр-источник и регистр-приёмник у этой инструкции совпадают, так что это скорее «перестановка по шаблону»), но работает с байтами. Индексы задаются значениями байтов второго операнда — регистра. Эта инструкция позволяет осуществить гораздо более разнообразные перестановки данных, чем описанные выше инструкции, и благодаря этому во многих случаях возможно упростить и ускорить вычисления.
a = _mm_shuffle_epi8(a, i);
Для этого значения байта i должны быть следующими (начиная с младшего байта): 4,15,12,13,10,11,8,9,6,7,4,5,2,3,0,1
В наборе ARM NEON копирование по шаблону реализуют несколько инструкций, которые работают с одним регистром-источником (например, vtbl1_s8 (int8x8_t a, int8x8_t idx)) либо с группой регистров (например, vtbl4_u8(uint8x8x4_t a, uint8x8_t idx)). Инструкция vqtbl1q_u8(uint8x16_t t, uint8x16_t idx) аналогична _mm_shuffle_epi8.
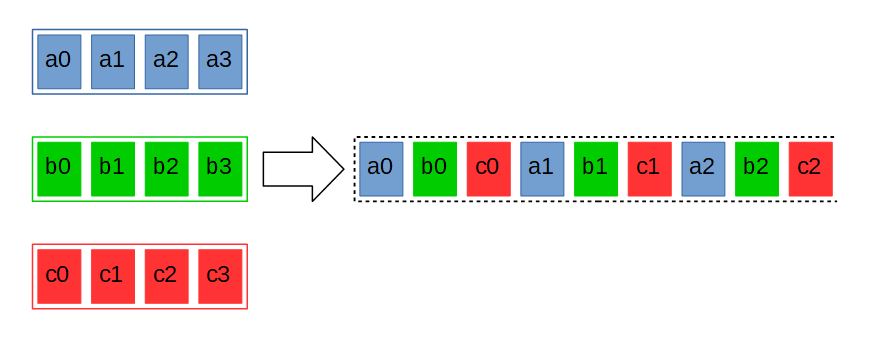
Другая операция, реализуемая векторными инструкциями — перемешивание. Пусть имеется массив с элементами , массив , с элементами , … массив с элементами . При выполнении этой операции элементы этих массивов объединяются в один в следующем порядке : (рисунок 6). В векторных инструкциях и в этом случае в качестве исходных массивов выступают регистры-источники, и притом только два. Очевидно, что при выполнении этой операции объём данных остаётся постоянным, а значит, и регистров-приёмников тоже должно быть два.
В векторных инструкциях x86 регистр-приёмник может быть только один, поэтому инструкции, реализующие перемешивание, обрабатывают только половину входных данных. Так, инструкция _mm_unpacklo_epi16(__m128i a, __m128i b) перемешивает 16-битные элементы младших половин регистров a и b, а дополняющая её инструкция _mm_unpackhi_epi16(__m128i a, __m128i b) — старших. Таким же образом работают инструкции для разрядностей 8, 32 и 64 бита. Инструкции _mm_unpacklo_epi64 и _mm_unpackhi_epi64, по сути, просто объединяют младшие и, соответственно, старшие 64 бита двух регистров. Парные инструкции нередко используются совместно.
Аналогичные инструкции есть и среди инструкций ARM NEON (семейство инструкций vzip). Некоторые из инструкций используют не один, а два регистра-приёмника и, таким образом, обрабатывают входные данные полностью. Имеются и такие инструкции, которые производят обратную операцию (vuzp), и для которых нет аналогов среди инструкций x86.
Инструкция _mm_alignr_epi8(__m128i a, __m128i b, int imm) копирует в регистр-приёмник байты регистра-источника b, начиная с выбранного байта imm, а оставшиеся байты копирует из регистра a, начиная с младшего байта. Пусть байты регистра a имеют значения a0..a15, а байты регистра b — значения b0..b15. Тогда при выполнении:
a = _mm_alignr_epi8(a, b, 5);
в регистр a будут записаны следующие байты: b5, b6, b7, b8, b9, b10, b11, b12, b13, b14, b15, a0, a1, a2, a3, a4. Подобные инструкции, которые работают не с байтами, а с элементами определённой разрядности, предоставляет ARM NEON.
Инструкции AVX и AXV2#
Дальнейшее развитие векторных инструкций архитектуры x86 связано с появлением 256-битных инструкций AVX и AVX2. Что эти инструкции предоставляют разработчикам?
Прежде всего, вместо 8 (16) 128-битных регистров XMM имеется 16 256-битных регистров YMM0 – YMM15, младшие 128 бит которых являются векторными регистрами XMM. Инструкции, в отличие от SSE, принимают не два, а три регистра-операнда: два регистра-источника и один регистр-приёмник. При этом после выполнения инструкции первоначальное содержимое регистров-источников не теряется.
Почти все операции, реализованные в более ранних наборах инструкций SSE-SSE4.2, есть и в AVX/AVX2, прежде всего — арифметические. Для инструкций вроде _mm_add_epi32, _mm_madd_epi16, _mm_sub_ps, _mm_slli_epi16 и многих других имеются полностью аналогичные инструкции, но которые вдвое их производительнее.
Точных аналогов инструкций _mm_loadl_epi64 и _mm_cvtsi32_si128 (и соответствующих инструкций для вывода) в AVX/AVX2 нет. Взамен появились инструкции _mm256_maskload_epi32 и _mm256_maskload_epi64, которые загружают нужное количество 32- и 64-битных значений из памяти с использованием битовой маски.
Появились и новые инструкции _mm256_gather_epi32, _mm256_gather_epi64 (и аналогичные для чисел с плавающей запятой), которые загружают не непрерывный массив данных, а порции данных с использованием начального адреса и заданных смещений для каждой порции. Инструкции особенно полезны в случае, когда нужные данные расположены в памяти не последовательно, и требуется много операций, чтобы их извлечь и объединить.
В наборе AVX2 есть инструкции для перемешивания и перестановки данных, например _mm256_shuffle_epi32 и _mm256_alignr_epi8. Есть одна особенность, которая отличает их от других инструкций AVX/AVX2. Например, арифметические инструкции рассматривают регистр YMM как массив из 256 бит. Но указанные инструкции рассматривают YMM как два 128-битных регистра, и производят над ними операции точно таким же образом, каким их производит соответствующая инструкция SSE.
Например, регистр содержит следующие 32-битные элементы: A0, A1, A2, A3, A4, A5, A6, A7. Тогда, после выполнения
a = _mm256_shuffle_epi32(a, _M_SHUFFLE(0,1,2,3));
его содержимое станет: A3, A2, A1, A0, A7, A6, A5, A4.
Таким же образом работают и другие инструкции: _mm256_unpacklo_epi16, _mm256_shuffle_epi8, _mm256_alignr_epi8.
В AVX2 появились и новые инструкции для перестановки и перемешивания. Например, _mm256_permute4x64_epi64(__m256i, int imm) переставляет 64-битные элементы регистра таким же образом, каким mm_shuffle_epi32 переставляет 32-битные элементы.
Некоторые практические применения кода#
Чтобы показать реализации под VS я собрался некоторые праткические примеры использования. Также отдельно рассмотрим пример использования в алгоритмизации.
Примечание: поскольку мой ноутбук не поддерживает AVX512, я буду работать на AVX2.
Проверка доступности#
#include <iostream>
#include <intrin.h>
bool checkCpuFeature(int featureBit) {
int cpuInfo[4];
__cpuid(cpuInfo, 1);
return (cpuInfo[3] & featureBit) != 0;
}
int main() {
const int SSE_BIT = 1 << 25;
const int SSE2_BIT = 1 << 26;
const int AVX_BIT = 1 << 28;
const int AVX2_BIT = (1 << 5);
const int AVX512F_BIT = (1 << 16);
//SSE, SSE2, AVX
std::cout << "SSE: " << checkCpuFeature(SSE_BIT) << std::endl;
std::cout << "SSE2: " << checkCpuFeature(SSE2_BIT) << std::endl;
std::cout << "AVX: " << checkCpuFeature(AVX_BIT) << std::endl;
//AVX2 and AVX512F
int cpuInfo[4];
__cpuid(cpuInfo, 7);
std::cout << "AVX2: " << ((cpuInfo[1] & AVX2_BIT) != 0) << std::endl;
__cpuidex(cpuInfo, 7, 0);
std::cout << "AVX512F: " << ((cpuInfo[1] & AVX512F_BIT) != 0) << std::endl;
return 0;
}
- Проверка CPU-функций с использованием CPUID
ФункцияcheckCpuFeature(int featureBit)использует инструкцию__cpuid, которая позволяет получить информацию о возможностях процессора. Эта инструкция заполняет массивcpuInfo, где каждая позиция содержит информацию о различных возможностях процессора.
В __cpuid(cpuInfo, 1) выполняется запрос с аргументом 1, который соответствует стандартному запросу для получения базовых данных о процессоре. В результате выполнения в массиве cpuInfo будут записаны значения, которые содержат флаги поддержки различных инструкций, например, SSE, SSE2, AVX и других.
Функция checkCpuFeature проверяет конкретный бит в ответе процессора. В ней передается параметр featureBit — это битовая маска для определенной инструкции (например, для SSE или AVX). Проверяется, поддерживает ли процессор данную инструкцию, путем побитового И с cpuInfo[3].
- Получение информации о поддержке AVX2 и AVX512
Для AVX2 и AVX512 используется__cpuidс аргументом7, который соответствует расширенному запросу, возвращающему информацию о дополнительных инструкциях, таких как AVX2 и AVX512. Результат записывается вcpuInfo[1], и затем проверяется, поддерживает ли процессор эти расширения.
AVX2 проверяется с использованием побитовой операции И с маской AVX2_BIT. Если результат не равен нулю, значит процессор поддерживает AVX2.
Для AVX512F используется __cpuidex(cpuInfo, 7, 0), что позволяет сделать запрос с дополнительным параметром, указывающим на специфические расширения, такие как AVX512F.
Векторное сложение#
#include <iostream>
#include <immintrin.h> // Заголовок для SIMD инструкций
#include <locale>
void vectorAddition(float* a, float* b, float* c, int size) {
for (int i = 0; i < size; i += 4) {
// Загружаем данные в SIMD регистры
__m128 vecA = _mm_loadu_ps(&a[i]);
__m128 vecB = _mm_loadu_ps(&b[i]);
// Выполняем сложение
__m128 vecC = _mm_add_ps(vecA, vecB);
// Сохраняем результат
_mm_storeu_ps(&c[i], vecC);
}
}
int main() {
setlocale(LC_ALL, "ru_RU.UTF-8");
const int size = 8;
float a[size] = { 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0 };
float b[size] = { 9.0, 10.0, 11.0, 12.0, 13.0, 14.0, 15.0, 16.0 };
float c[size];
vectorAddition(a, b, c, size);
std::cout << "Результат сложения векторов: ";
for (int i = 0; i < size; ++i) {
std::cout << c[i] << " ";
}
std::cout << std::endl;
return 0;
}
Векторное умножение#
#include <iostream>
#include <immintrin.h> // Заголовок для SIMD инструкций
#include <locale>
void vectorMultiplication(float* a, float* b, float* c, int size) {
for (int i = 0; i < size; i += 4) {
__m128 vecA = _mm_loadu_ps(&a[i]);
__m128 vecB = _mm_loadu_ps(&b[i]);
__m128 vecC = _mm_mul_ps(vecA, vecB);
_mm_storeu_ps(&c[i], vecC);
}
}
int main() {
setlocale(LC_ALL, "ru_RU.UTF-8");
const int size = 8;
float a[size] = { 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0 };
float b[size] = { 9.0, 10.0, 11.0, 12.0, 13.0, 14.0, 15.0, 16.0 };
float c[size];
vectorMultiplication(a, b, c, size);
std::cout << "Результат умножения векторов: ";
for (int i = 0; i < size; ++i) {
std::cout << c[i] << " ";
}
std::cout << std::endl;
return 0;
}
Метод трапеций с использованием векторных инструкций#
Из Практической работы 2 рассмотрим код реализации метода прямоугольников.
double rectangle_method(double (*f)(double), double a, double b, int n) {
// Вычисляем шаг
double delta_x = (b - a) / n;
// Суммируем значения функции в узловых точках
double integral = 0;
for (int i = 0; i < n; i++) {
double x_i = a + i * delta_x; // Левая точка интервала
integral += f(x_i);
}
// Умножаем на шаг
integral *= delta_x;
return integral;
}
Напращивается очевидная простейшая реализация, при котором за 1 итерацию цикла будет складываться n чисел нашего вектора.
Каждый поток может вычислять частичную сумму, соответствующую части площади под кривой. После вычисления всех частичных сумм, результаты суммируются, используя свойство аддитивности интеграла. Это свойство позволяет делить вычисление на несколько потоков, каждый из которых будет вычислять интеграл на части интервала, а затем результаты будут сложены.
Существует несколько вариантов распределения итераций между потоками:
1) Разбиение на p смежных непрерывных частей

2) Циклическое распределение итераций по потокам

Поскольку разбиение на p смежных частей мне кажется более интутивным, то рассмотрим его.
Пример для компилятора GCC#
Шаги оптимизации:
1. Загрузка значений функции в SIMD-регистр
Вместо обычного вычисления значений функции для каждой точки на интервале, мы загружаем значения функции для двух точек (например, x_i и x_{i+1} ) одновременно в SIMD-регистр.
-
Сложение значений с использованием SIMD-инструкции
Операции сложения значений функции выполняются с использованием SIMD-инструкции. Это позволяет одновременно сложить два значения за одну инструкцию. -
Сохранение и суммирование результатов
После того как все суммы были вычислены с использованием SIMD, мы сохраняем результат в массив и суммируем его для получения финального значения интеграла.
SIMD-инструкции, такие как AVX2, позволяют работать с векторными типами данных, такими как __m128d, который представляет собой регистр, содержащий два значения типа double.
#pragma GCC optimize("O3")
#pragma GCC target("avx2")
#include <iostream>
#include <immintrin.h>
#include <cmath>
#include <chrono>
double rectangle_method(double (*f)(double), double a, double b, int n) {
double delta_x = (b - a) / n;
double integral = 0.0;
for (int i = 0; i < n; ++i) {
double x_i = a + i * delta_x;
integral += f(x_i);
}
integral *= delta_x;
return integral;
}
double rectangle_method_simd(double (*f)(double), double a, double b, int n) {
double delta_x = (b - a) / n;
double integral = 0.0;
__m128d sum = _mm_setzero_pd();
for (int i = 0; i < n; i += 2) {
double x1 = a + i * delta_x;
double x2 = a + (i + 1) * delta_x;
__m128d values = _mm_set_pd(f(x2), f(x1));
sum = _mm_add_pd(sum, values);
}
double temp[2];
_mm_storeu_pd(temp, sum);
integral = temp[0] + temp[1];
integral *= delta_x;
return integral;
}
double example_function(double x) {
return std::sin(x);
}
int main() {
double a = 0.0;
double b = M_PI;
int n = 2000000;
auto start = std::chrono::high_resolution_clock::now();
double result_normal = rectangle_method(example_function, a, b, n);
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> duration_normal = end - start;
start = std::chrono::high_resolution_clock::now();
double result_simd = rectangle_method_simd(example_function, a, b, n);
end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> duration_simd = end - start;
std::cout << "Результат интегрирования (обычная функция): " << result_normal << std::endl;
std::cout << "Время выполнения (обычная функция): " << duration_normal.count() << " секунд" << std::endl;
std::cout << "Результат интегрирования (SIMD): " << result_simd << std::endl;
std::cout << "Время выполнения (SIMD): " << duration_simd.count() << " секунд" << std::endl;
return 0;
}
Пример для компилятора MSVC#
float rectangle_method_simd(float (*f)(float), float a, float b, int n) {
float delta_x = (b - a) / n;
__m256 integral_vec = _mm256_setzero_ps();
int simd_width = 8;
int simd_end = n - (n % simd_width);
for (int i = 0; i < simd_end; i += simd_width) {
__m256 indices = _mm256_set_ps(i + 7, i + 6, i + 5, i + 4, i + 3, i + 2, i + 1, i);
__m256 x_vals = _mm256_add_ps(_mm256_mul_ps(indices, _mm256_set1_ps(delta_x)), _mm256_set1_ps(a));
float x_vals_arr[8];
_mm256_storeu_ps(x_vals_arr, x_vals);
__m256 f_vals = _mm256_set_ps(f(x_vals_arr[7]), f(x_vals_arr[6]), f(x_vals_arr[5]), f(x_vals_arr[4]),
f(x_vals_arr[3]), f(x_vals_arr[2]), f(x_vals_arr[1]), f(x_vals_arr[0]));
integral_vec = _mm256_add_ps(integral_vec, f_vals);
}
float integral_arr[8];
_mm256_storeu_ps(integral_arr, integral_vec);
float integral = 0;
for (int i = 0; i < 8; ++i) {
integral += integral_arr[i];
}
for (int i = simd_end; i < n; ++i) {
integral += f(a + i * delta_x);
}
return integral * delta_x;
}
Метод трапеций с использованием OpenMP#
Для тех, кто заинтересуется всерьез я предлагаю ознакомиться с OpenMP.
OpenMP – механизм написания параллельных программ для систем с общей памятью.
double parallel_rectangle_method(double (*f)(double), double a, double b, int n) {
double delta_x = (b - a) / n; // Вычисляем шаг
double integral = 0;
#pragma omp parallel
{
double local_integral = 0;
// Параллельный расчёт
#pragma omp for
for (int i = 0; i < n; i++) {
double x_i = a + i * delta_x; // Левая точка интервала
local_integral += f(x_i);
}
// Суммируем результаты в общей переменной
#pragma omp atomic
integral += local_integral;
}
// Умножаем на шаг
integral *= delta_x;
return integral;
}
Обращаю внимание, что вы можете рабоать с темой Гравитационная задача N тел для индвидуальной работы. Вам будут выданы материалы, чтобы вы поподробнее ознакомились с методами векторизации.