Введение в реверс-инжиниринг#
Рассказ о том как, зачем и почему?#
Приложения всегда имеют интересные "фичи", которые на саомм деле явлюятся дырами. Вспомним закон дырявых абстаркций из прошлого семестра.
Tip
Согласно этому закону, любая нетривиальная абстракция в некоторой степени дырявая, то есть может ломаться, иногда немного, иногда значительно.
С одной интересной дыркой познакомился пользователь с хабра. Внезапно, открыв приложение «Ситимобил» он увидел, что один интересный запрос выполняется без какой-либо аутентификации.
Это был запрос на получение информации о ближайших машинах. Выполнив этот запрос несколько раз с разными параметрами он понял, что можно выгружать данные о таксистах практически в реалтайме. Вы только представьте, сколько интересного можно теперь узнать!
Как добросовестный гражданин и программист, автор статьи бросил репорт на горячую линию поддержки, однако получил незамедлительный ответ, что данные не относятся пользователю и следовательно могут быть публичны.
Bug
Репорт был отправлен через платформу bug bounty (hackerone).
Ответ: данные не считаются чувствительными, поэтому защиты не требуют.
Он стал исследовать такие данные и получил следующие карты:

Данная уязвимость, которая таковой не посчиталась компанией, позволялала даже построить траекторию движения водителя по улицам Москвы:
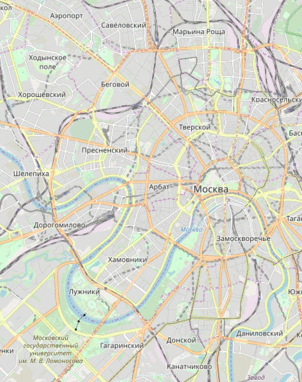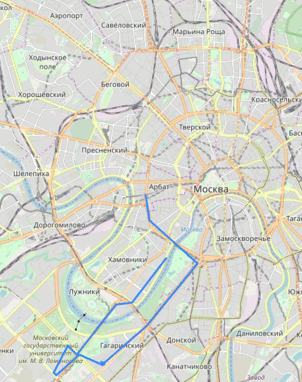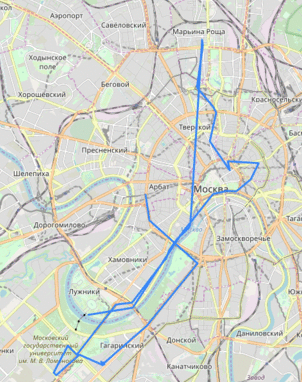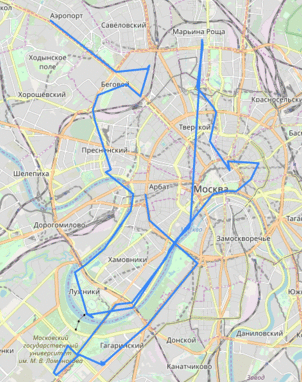
К чему эта история? Я не специалист в области ИБ, поэтому заострю внимание лишь на проблематике: анализируя поведения ПО, можно обнаружить крайне нелогичные вещи или же "поспешные", но так хорошо работающие решения. Поэтому в ходе работы мы бьемся об две проблемы: как читать ассемблер и как понять логику того мощного разума, что руководил золотыми руками, вбивающими код. Теперь после такого интересного предисловия можно перейти к делу.
Тестирование иреверс-инжинирнг#
Современное тестирование программного обеспечения опирается на три ключевых подхода: тестирование как "чёрный ящик", "белый ящик" и "серый ящик". Каждый из них определяет, насколько глубоко тестировщик или аналитик должен понимать внутреннее устройство программы.
- Чёрный ящик — тестировщик не имеет доступа к исходному коду, и тестирование строится только на основе внешнего поведения программы.
- Белый ящик — тестирование проводится с полным знанием исходного кода и внутренней логики работы системы.
- Серый ящик — промежуточный подход: частичное понимание внутренней структуры дополняет внешний анализ.
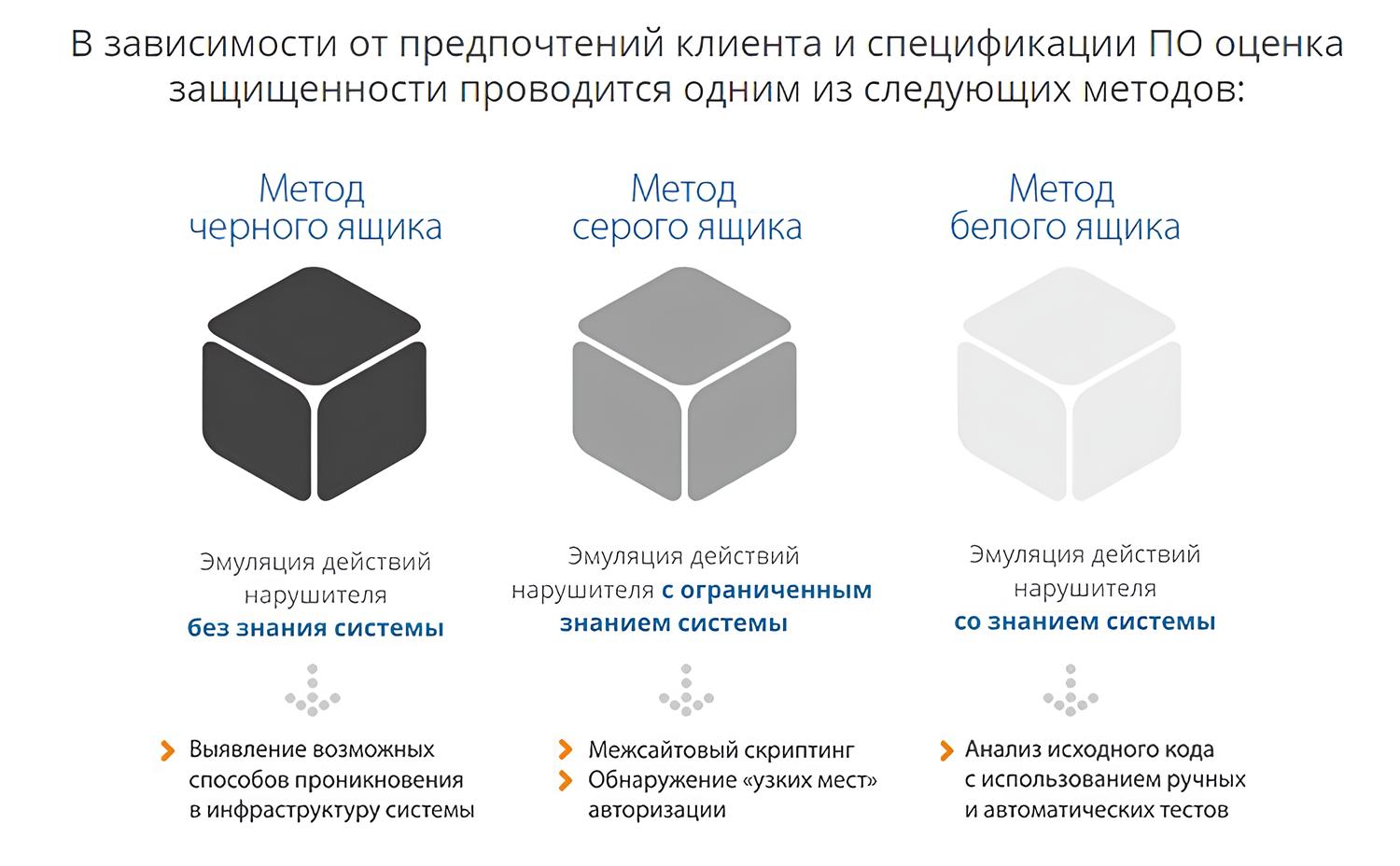
Однако в реальной практике не всегда возможен доступ к исходному коду, документации или даже полной информации о входных и выходных данных. Это создаёт серьёзные проблемы как для тестирования, так и для анализа безопасности, анализа совместимости, миграции ПО и других задач. В таких условиях возникает необходимость использовать реверс-инжиниринг — процесс исследования программного продукта с целью восстановления его архитектуры, логики работы или исходных компонентов.
Реверс-инжиниринг применяется, когда:
- требуется понять, как работает устаревшее программное обеспечение, для которого утрачена документация;
- необходимо выявить уязвимости в бинарном коде;
- производится анализ поведения вредоносных программ;
- осуществляется проверка совместимости нового программного обеспечения со старыми компонентами;
- ведётся исследование патентов и лицензионных соглашений на предмет нарушения интеллектуальной собственности.
Таким образом, реверс-инжиниринг служит не только техническим инструментом, но и важным звеном в обеспечении надёжности, безопасности и поддерживаемости программных систем.
Какие знания нам понадобятся?#
Многим из нас хочется понять, как устроены программы не только снаружи, но и на самом низком уровне — как исполняемые файлы формируются из двоичных данных и возможно ли изменить поведение программы, даже не имея доступа к её исходному коду.
Но на этом пути почти сразу появляется серьёзное препятствие — ассемблер. Именно он отпугивает большинство, кто только начинает интересоваться этой областью.
Поэтому цель этого краткого введения — помочь сделать первые шаги. Мы не будем углубляться в теорию, а сосредоточимся на том, с чем чаще всего сталкиваются новички на практике. Предполагается, что вы умеете находить дополнительную информацию и готовы к экспериментам.
Главное здесь — не выучить всё сразу, а увидеть направление и понять, как можно начать. Возможно, реверс-инжиниринг окажется не таким сложным и далёким, как кажется на первый взгляд.
Примечание: предполагается, что читатель обладает элементарными знаниями о шестнадцатеричной системе счисления, а также о языке программирования С. В качестве примера используется 32-разрядный исполняемый файл Windows — результаты могут отличаться на других ОС/архитектурах.
Компиляция#
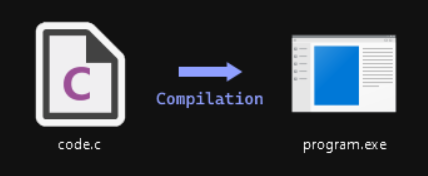
Когда мы пишем программу на компилируемом языке, например на C или C++, результатом работы становится двоичный исполняемый файл — например, .exe.
Этот процесс выполняет компилятор — специальная программа, которая сначала проверяет синтаксис исходного кода, а затем преобразует его в машинный код, понятный процессору.
Двоичный код#
Как мы уже говорили, результирующий выходной файл содержит двоичный код, понятный для CPU. По сути, это последовательность инструкций различной длины, которые должны выполняться по порядку — вот так выглядят некоторые из них:

Преимущественно, это арифметические инструкции. Они манипулируют регистрами/флагами CPU, а также энергозависимой памятью по мере выполнения.
Регистр и память в работе процессора#
Регистры#
Регистры процессора можно представить как быстрые переменные, доступные для чтения и записи. Их немного и каждый из них выполняет важную роль: хранит данные, промежуточные результаты, адреса или счётчики во время выполнения инструкций.
Одним из особенных регистров является FLAGS (в 32-битной архитектуре — EFLAGS). Он содержит флаги — логические индикаторы, отражающие состояние процессора. Например:
- ZF — флаг нуля (устанавливается, если результат равен нулю),
- OF — флаг переполнения,
- PF — флаг чётности,
- SF — флаг знака (определяет, положительный или отрицательный результат).
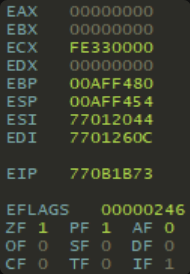
В отладчиках, таких как x64dbg, можно увидеть регистры вроде EAX, ESP (указатель стека), EBP (базовый указатель) и другие.
Работа с памятью: стек и куча#
Когда процессор выполняет код, ему необходим доступ к памяти. Здесь задействуются две ключевые области: стек и куча.
Стек (Stack)#
Это упорядоченная, компактная структура по принципу «последний пришёл — первый ушёл» (LIFO). Используется для хранения:
- локальных переменных,
- аргументов функций,
- адресов возврата (для отслеживания вызовов — именно отсюда берётся термин трассировка стека).
Операции со стеком выполняются быстро благодаря строгому порядку и предсказуемому управлению.
Куча (Heap)#
Куча, в отличие от стека, менее структурирована. Она используется для динамического выделения памяти, особенно когда:
- заранее неизвестен точный размер данных,
- требуется большой объём,
- необходима гибкость в изменении размера данных в процессе выполнения.
Именно здесь размещаются объекты и сложные структуры, создаваемые «на лету».
Основные инструкции x86 Assembly#
Как я упоминал ранее, ассемблерные инструкции имеют разный «размер в байтах» и различное количество операндов.
Операндами могут быть либо непосредственные значения (значение указывается прямо в команде), либо регистры, в зависимости от инструкции:
55 push ebp ; size: 1 byte, argument: register
6A 01 push 1 ; size: 2 bytes, argument: immediate
Давайте быстро пробежимся по очень небольшому набору некоторых из наиболее употребляемых команд — не стесняйтесь самостоятельно изучать для получения более подробной информации:
Стековые операции#
push value— помещает значение в стек (ESP уменьшается на 4).pop register— извлекает значение из стека в регистр (ESP увеличивается на 4).
Передача данных#
mov destination, source— копирует значение из регистра или памяти в регистр.mov destination, [expression]— копирует значение из памяти по адресу, заданному выражением, в регистр.
Управление потоком выполнения#
jmp destination— безусловный переход, изменяет указатель инструкций (EIP).jz destination/je destination— переход, если установлен нулевой флаг (ZF).jnz destination/jne destination— переход, если нулевой флаг не установлен.
Арифметические операции и сравнение#
cmp operand1, operand2— сравнивает операнды, устанавливает ZF, если равны.add operand1, operand2— складывает operand2 с operand1, результат в operand1.sub operand1, operand2— вычитает operand2 из operand1, результат в operand1.
Вызовы и возвраты функций#
call function— вызывает функцию, помещая адрес возврата в стек.retn— возвращается из функции, извлекая адрес возврата из стека.
Примечание: В терминологии x86 инструкции сравнения (
cmp) выполняют вычитание и устанавливают флаг ZF, если операнды равны, поэтому "равно" и "ноль" часто взаимозаменяемы.
Шаблоны в ассемблере#
Теперь, когда у нас есть приблизительное представление об основных элементах, используемых во время выполнения программы, давайте познакомимся с шаблонами инструкций, с которыми можно столкнуться при реверс-инжиниринге обычного 32-битного двоичного файла PE.
Пролог функции#
Пролог функции — это некоторый код, внедренный в начало большинства функций и служащий для установки нового стекового кадра указанной функции.
Обычно он выглядит так (X — число):
55 push ebp ; preserve caller function's base pointer in stack
8B EC mov ebp, esp ; caller function's stack pointer becomes base pointer (new stack frame)
83 EC XX sub esp, X ; adjust the stack pointer by X bytes to reserve space for local variables
Эпилог функции#
Эпилог — это просто противоположность пролога. Он отменяет его шаги для восстановления стека вызывающей функции, прежде чем вернуться к ней:
8B E5 mov esp, ebp ; restore caller function's stack pointer (current base pointer)
5D pop ebp ; restore base pointer from the stack
C3 retn ; return to caller function
Теперь может возникнуть вопрос — как функции взаимодействуют друг с другом? Как именно вы отправляете/обращаетесь к аргументам при вызове функций, и как вы получаете возвращаемое значение? Именно для этого существуют соглашения о вызовах.
Соглашение о вызове#
Соглашение о вызове — это протокол для взаимодействия функций. Существуют разные варианты, но все они используют общий принцип.
Рассмотрим соглашение __cdecl (от C declaration), которое является стандартным при компиляции кода на языке C.
- В 32-битной архитектуре аргументы функции передаются через стек (помещаются в обратном порядке).
- Возвращаемое значение передаётся через регистр EAX (если это не число с плавающей точкой).
Это означает, что при вызове функции func(1, 2, 3) будет сгенерировано следующее:
6A 03 push 3
6A 02 push 2
6A 01 push 1
E8 XX XX XX XX call func
Собираем все вместе#
Предположим, что func() просто складывает аргументы и возвращает результат. Вероятно, это будет выглядеть так:
int __cdecl func(int, int, int):
prologue:
55 push ebp ; save base pointer
8B EC mov ebp, esp ; new stack frame
body:
8B 45 08 mov eax, [ebp+8] ; load first argument to EAX (return value)
03 45 0C add eax, [ebp+0Ch] ; add 2nd argument
03 45 10 add eax, [ebp+10h] ; add 3rd argument
epilogue:
5D pop ebp ; restore base pointer
C3 retn ; return to caller
Теперь, если вы внимательно следили за объяснением, но всё ещё в замешательстве, можете задать себе один из двух вопросов:
Почему мы должны сместить EBP на 8, чтобы получить первый аргумент?
Если проверить определение инструкции call, то станет понятно, что она внутренне помещает значение EIP в стек. Команда push уменьшает значение ESP (которое скопировано в EBP в прологе) на 4 байта. Кроме того, первая инструкция пролога — это тоже push, поэтому получается два уменьшения по 4 байта, то есть 8 байт смещения.
Что случилось с прологом и эпилогом, почему они кажутся «усечёнными»?
Это связано с тем, что во время выполнения функции стек не использовался — ESP не изменялся, значит, нет необходимости восстанавливать стек.
Условный оператор#
Чтобы продемонстрировать ассемблерные инструкции управления потоком выполнения, я бы хотел добавить еще один пример, иллюстрирующий, во что скомпилируется оператор if в ассемблере.
Предположим, у нас есть следующая функция:
void print_equal(int a, int b) {
if (a == b) {
printf("equal");
}
else {
printf("nah");
}
}
После ее компиляции вот дизассемблированный вид:
void __cdecl print_equal(int, int):
10000000 55 push ebp
10000001 8B EC mov ebp, esp
10000003 8B 45 08 mov eax, [ebp+8] ; load 1st argument
10000006 3B 45 0C cmp eax, [ebp+0Ch] ; compare it with 2nd
┌┅ 10000009 75 0F jnz short loc_1000001A ; jump if not equal
┊ 1000000B 68 94 67 00 10 push offset aEqual ; "equal"
┊ 10000010 E8 DB F8 FF FF call _printf
┊ 10000015 83 C4 04 add esp, 4
┌─┊─ 10000018 EB 0D jmp short loc_10000027
│ ┊
│ └ loc_1000001A:
│ 1000001A 68 9C 67 00 10 push offset aNah ; "nah"
│ 1000001F E8 CC F8 FF FF call _printf
│ 10000024 83 C4 04 add esp, 4
│
└── loc_10000027:
10000027 5D pop ebp
10000028 C3 retn
Дайте себе минутку и попытайтесь разобраться в этом дизассемблированном коде (для простоты, я изменил реальные адреса и сделал начало функции с 10000000).
В случае, если вам интересно, зачем нужна команда add esp, 4, то это просто приведение ESP к исходному значению (такой же эффект, что и у pop, только без изменения какого-либо регистра), поскольку у нас есть push строкового аргумента для printf.
Базовые структуры данных#
Давайте двигаться дальше. Поговорим о том, как хранятся данные (особенно целые числа и строки).
Endianness — это порядок байтов, представляющих значение в памяти компьютера.
Есть 2 типа: big-endian и little-endian.
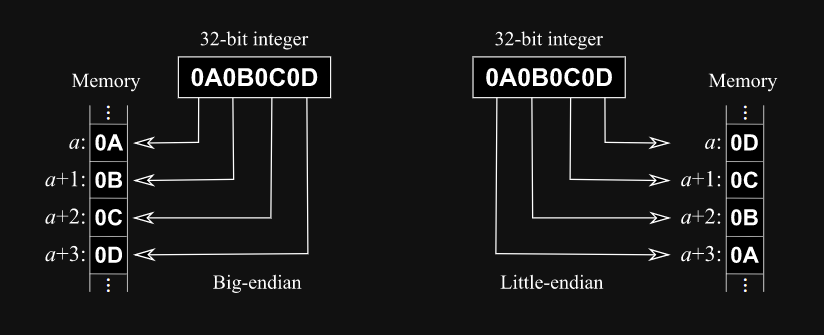
Для справки, процессоры семейства x86 (которые используются практически в любых компьютерах) всегда применяют little-endian.
Чтобы наглядно показать эту концепцию, я скомпилировал консольное приложение на C++ в Visual Studio, где объявил переменную типа int со значением 1337, а затем вывел её адрес с помощью функции printf().
После этого запустил программу в отладчике и проверил шестнадцатеричное представление памяти по этому адресу. Вот результат, который я получил:
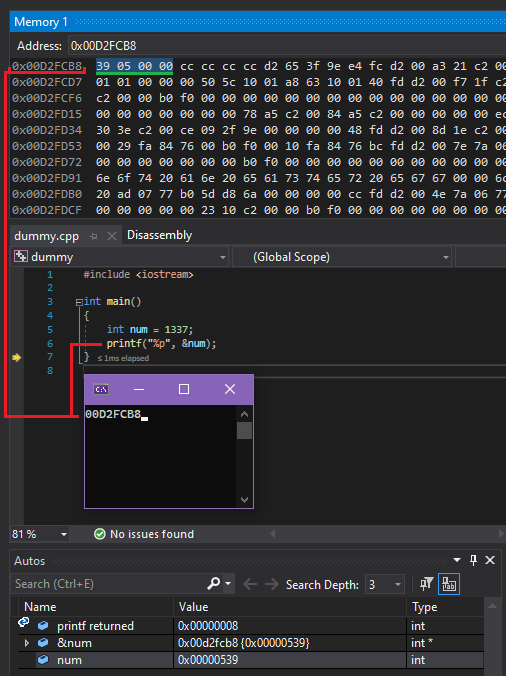
Уточним этот момент — переменная типа int занимает 4 байта (32 бита) (если вы об этом не знали). Это значит, что если переменная начинается с адреса D2FCB8, то заканчивается она перед адресом D2FCBC (то есть +4 байта).
Чтобы перейти от значения, удобочитаемого человеком, к байтам в памяти, сделайте следующее:
- Десятичное: 1337
- В шестнадцатеричном виде: 539
- В памяти (четыре байта): 00 00 05 39
- В формате little-endian (обратный порядок): 39 05 00 00
Строки#
В языке C строки хранятся в виде массивов типа char, поэтому здесь нет ничего особенного, кроме понятия null termination.
Если вы когда-нибудь задумывались, как функция strlen() узнаёт длину строки, то всё очень просто — строки завершаются специальным символом конца строки, называемым нулевым байтом или ‘\0’ (то есть байт со значением 00).
Если вы объявите строковую константу в C и наведёте курсор на неё, например, в Visual Studio, то увидите размер сгенерированного массива. Как видите, он на один элемент больше, чем длина видимой строки — именно из-за завершающего нулевого символа.
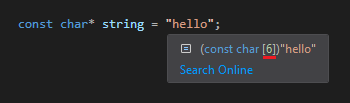
Примечание: концепция порядка байтов не применима к массивам, только к одиночным переменным.
Следовательно, порядок символов в памяти здесь будет нормальным.
Ghidra#
Ghidra — это фреймворк обратного инжиниринга программного обеспечения (SRE), созданный и поддерживаемый исследовательским директоратом Агентства национальной безопасности.
Эта платформа включает в себя набор высококачественных инструментов анализа программного обеспечения высокого класса, которые позволяют пользователям анализировать скомпилированный код на различных платформах, включая Windows, Mac OS и Linux.
Возможности Ghidra включают:
- ассемблирование,
- дизассемблирование,
- декомпиляцию,
- построение графов,
- написание скриптов,
- а также сотни других функций.
Ghidra поддерживает широкий спектр наборов инструкций процессоров и форматов исполняемых файлов и может работать как в интерактивном режиме, так и в автоматическом.
Пользователи могут создавать собственные подключаемые модули и скрипты на Java или Python.
Вскрытие покажет: Решаем лёгкий crackme (легкое)#

Создадим проект с exe файлом.
Сценарий 1
#include <iostream>
#include <string>
int secretFunction(int x) {
int result = (x * 42 + 13) ^ 0x5A;
return result;
}
int main() {
std::string password;
std::cout << "Enter password: ";
std::cin >> password;
if (password == "open_sesame") {
std::cout << "Access granted.\n";
int key = secretFunction(1337);
std::cout << "Secret key is: " << key << "\n";
}
else {
std::cout << "Access denied.\n";
}
return 0;
}
Сценарий 2
#include <iostream>
int main() {
int rows, cols;
std::cout << "Введите количество строк: ";
std::cin >> rows;
std::cout << "Введите количество столбцов: ";
std::cin >> cols;
for (int i = 0; i < rows; ++i) {
for (int j = 0; j < cols; ++j) {
// Вложенные условия с примером
if (i % 2 == 0) {
if (j % 2 == 0) {
std::cout << "[" << i << "," << j << "] — обе координаты чётные\n";
} else {
std::cout << "[" << i << "," << j << "] — i чётное, j нечётное\n";
}
} else {
if (j % 3 == 0) {
std::cout << "[" << i << "," << j << "] — i нечётное, j кратно 3\n";
} else {
std::cout << "[" << i << "," << j << "] — i нечётное, j не кратно 3\n";
}
}
}
}
return 0;
}
Сценарий 3
#include <iostream>
int main() {
int x, y, z;
std::cout << "Введите три целых числа (x, y, z): ";
std::cin >> x >> y >> z;
if (x > 0) {
std::cout << "x положительное\n";
if (y > 0) {
std::cout << "y положительное\n";
if (z > 10) {
std::cout << "z больше 10\n";
if (x + y == z) {
std::cout << "Сумма x и y равна z\n";
if (x - y > 0) {
std::cout << "x минус y положительное\n";
if (z % 2 == 1) {
std::cout << "z нечётное\n";
} else {
std::cout << "z чётное\n";
}
}
}
}
}
} else {
std::cout << "x не положительное\n";
}
return 0;
}
Анализ crack.me (сложное)#
Скачиваем и распаковываем архив; В архиве находим два каталога, соответствующие ОС Linux и Windows. На своей машине я перехожу в каталог Windows и встречаю в нем единственную «экзешку» — level_2.exe. Давайте запустим и посмотрим, чего она хочет:
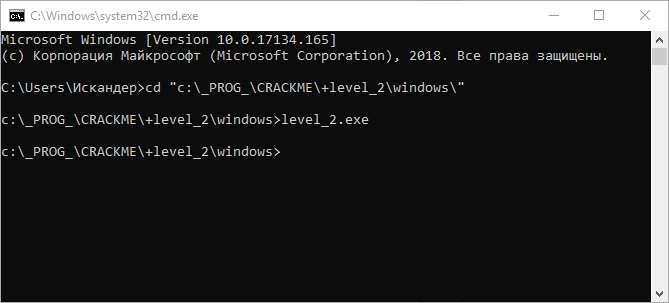
Похоже, облом! При запуске программа ничего не выводит. Пробуем запустить еще раз, передав ей произвольную строку в качестве параметра (вдруг, она ждет ключ?) — и вновь ничего… Но не стоит отчаиваться. Давайте предположим, что и параметры запуска нам тоже предстоит выяснить в качестве задания! Пора расчехлять наш «швейцарский нож» — Гидру.
Создание проекта в Гидре и предварительный анализ#
Запускаем Ghidra и в открывшемся Менеджере проектов создаём новый проект; я дал ему имя crackme3 (т.е. проекты crackme и crackme2 уже у меня созданы).
Проект — это, по сути, каталог файлов, в который можно добавлять любые файлы для изучения (exe, dll и т.д.).
Далее сразу же добавим наш файл level_2.exe через меню File | Import или просто нажав клавишу I.
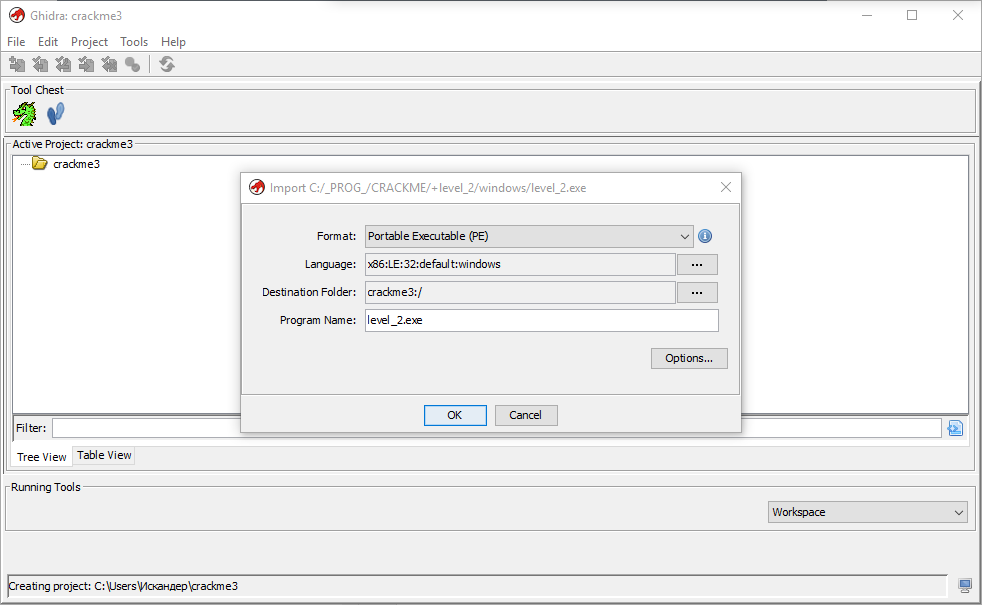
Видим, что уже до импорта Гидра определила нашу подопытную крякми как 32-разрядный PE (portable executable) для ОС Win32 и платформы x86. После импорта наш ждет еще больше информации:
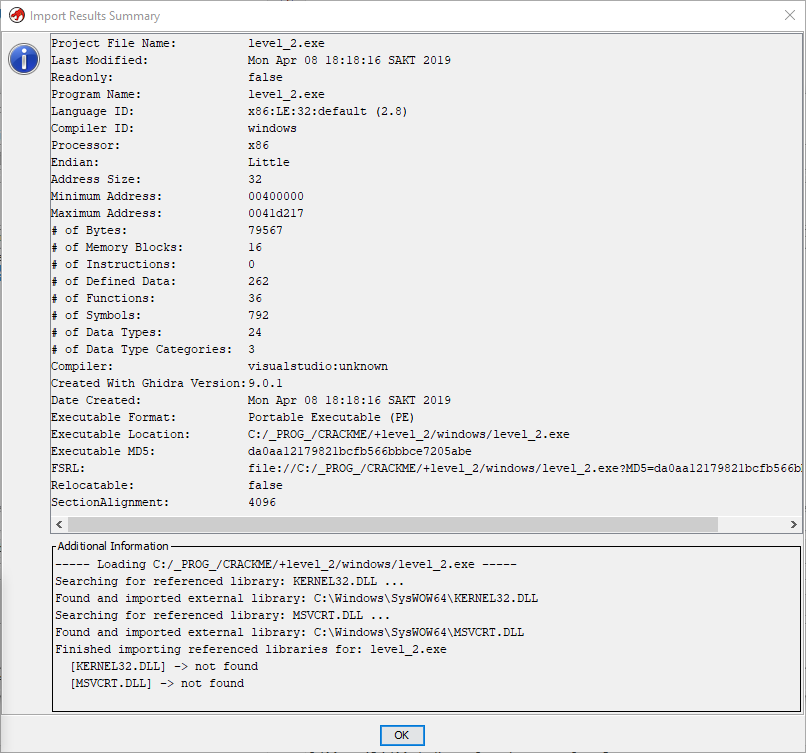
Здесь, кроме вышеуказанной разрядности, нас может еще заинтересовать порядок байтов (endianness), который в нашем случае — Little (от младшего к старшему байту), что и следовало ожидать для «интеловской» 86-й платформы.
С предварительным анализом мы закончили.
Выполнение автоматического анализа#
Время запустить полный автоматический анализ программы в Гидре. Это делается двойным кликом на соответствующем файле (level_2.exe). Имея модульную структуру, Гидра обеспечивает всю свою основную функциональность при помощи системы плагинов, которые можно добавлять / отключать или самостоятельно разрабатывать. Так же и с анализом — каждый плагин отвечает за свой вид анализа. Поэтому сначала перед нами открывается вот такое окошко, в котором можно выбрать интересующие виды анализа:
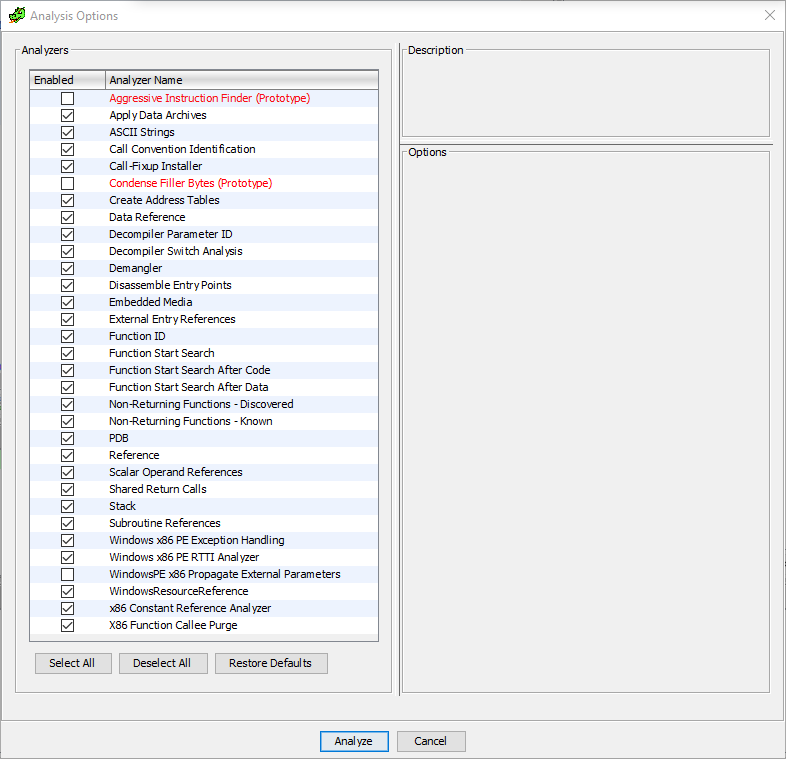
Для наших целей имеет смысл оставить настройки по умолчанию и запустить анализ. Сам анализ выполняется довольно быстро (у меня занял около 7 секунд), хотя пользователи на форумах сетуют на то, что для больших проектов Гидра проигрывает в скорости IDA Pro. Возможно, это и так, но для небольших файлов эта разница несущественна.
Итак, анализ завершен. Его результаты отображены в окне браузера кода (Code Browser):
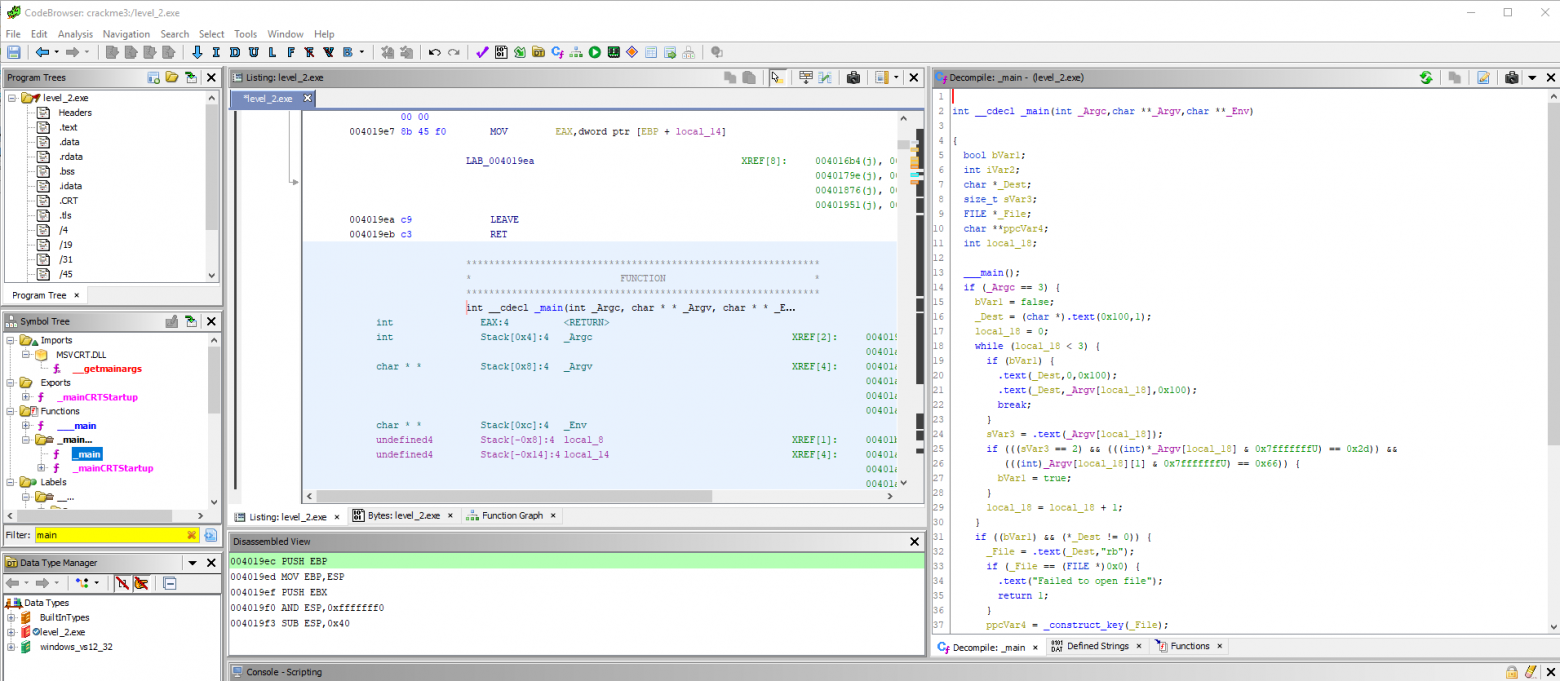
Это окно является основным для работы в Гидре, поэтому следует изучить его более внимательно.
Обзор интерфейса браузера кода#
Настройки интерфейса по умолчанию разбивают окно на три части:
Центральная часть — основное окно, листинг дизассемблера, который визуально напоминает интерфейсы IDA, OllyDbg и других аналогичных инструментов.
По умолчанию, в листинге отображаются следующие столбцы (слева направо):
- Адрес памяти
- Опкод команды
- ASM-команда
- Параметры ASM-команды
- Перекрёстная ссылка (если есть)
Настройка отображения возможна по нажатию на кнопку в виде «кирпичной стены» на тулбаре.
🔧 Гибкость настройки дизассемблера в Ghidra — одна из лучших среди подобных программ.
Левая часть содержит 3 панели:
- Секции программы (можно быстро переходить кликом)
- Дерево символов — импорты, экспорты, функции, заголовки и т.д.
- Дерево типов используемых переменных
⭐ Самая полезная часть — дерево символов, которое позволяет быстро найти нужную функцию и перейти к её адресу.
Правая часть — листинг декомпилированного кода
Представлен на языке C, что облегчает понимание логики работы программы.
Дополнительные окна:
Через меню Window можно добавить множество других панелей. Например:
В центральную часть:
- Bytes — окно просмотра памяти
- Function Graph — граф вызовов и переходов между функциями
В правую часть:
- Strings — строковые переменные
- Functions — таблица всех функций
Окна отображаются в отдельных вкладках, и каждое можно открепить и сделать «плавающим», удобно размещая и масштабируя по своему усмотрению.
🎯 Это делает интерфейс чрезвычайно гибким и удобным для анализа.
Изучение алгоритма программы — функция main()#
Что ж, приступим к непосредственному анализу нашей крякми-программки.
Начать нужно с поиска точки входа программы, то есть функции, которая вызывается при старте.
Поскольку наша программа написана на C/C++, можно ожидать, что основной функцией будет main() или что-то похожее.
Действуем следующим образом:
- В левой панели (в дереве символов) находим фильтр
- Вводим туда main
- Видим среди результатов функцию _main() в разделе Functions
Кликаем по найденной функции, чтобы перейти к её дизассемблированному и декомпилированному виду.
Обзор функции main() и переименование непонятных функций
После перехода к main() в листинге дизассемблера сразу отображается соответствующий участок ассемблерного кода,
а справа — декомпилированный код на C.
Удобная особенность Ghidra — синхронизация выделения:
- Выделяя мышью ASM-команды, одновременно подсвечивается соответствующий участок декомпилированного C-кода.
- Если открыто окно просмотра памяти (Bytes), синхронизация работает и с ним.
Важно понимать специфику Ghidra:
Она делает упор именно на анализ декомпилированного кода,
поэтому создатели уделили большое внимание качеству декомпиляции и удобству навигации:
- Можно перейти к определению переменной или функции двойным кликом по имени.
- Любую функцию, переменную или область памяти можно тут же переименовать (по нажатию клавиши L или через контекстное меню).
Это особенно полезно, поскольку большинство изначальных имён — вроде FUN_401000 — неинформативны и мешают анализу.
Переименование упрощает понимание логики программы.
Далее Ghidra представит нам распознанный код функции main() — начнем разбор.
int __cdecl _main(int _Argc,char **_Argv,char **_Env)
{
bool bVar1;
int iVar2;
char *_Dest;
size_t sVar3;
FILE *_File;
char **ppcVar4;
int local_18;
___main();
if (_Argc == 3) {
bVar1 = false;
_Dest = (char *)_text(0x100,1);
local_18 = 0;
while (local_18 < 3) {
if (bVar1) {
_text(_Dest,0,0x100);
_text(_Dest,_Argv[local_18],0x100);
break;
}
sVar3 = _text(_Argv[local_18]);
if (((sVar3 == 2) && (((int)*_Argv[local_18] & 0x7fffffffU) == 0x2d)) &&
(((int)_Argv[local_18][1] & 0x7fffffffU) == 0x66)) {
bVar1 = true;
}
local_18 = local_18 + 1;
}
if ((bVar1) && (*_Dest != 0)) {
_File = _text(_Dest,"rb");
if (_File == (FILE *)0x0) {
_text("Failed to open file");
return 1;
}
ppcVar4 = _construct_key(_File);
if (ppcVar4 == (char **)0x0) {
_text("Nope.");
_free_key((void **)0x0);
}
else {
_text("%s%s%s%s\n",*ppcVar4 + 0x10d,*ppcVar4 + 0x219,*ppcVar4 + 0x325,*ppcVar4 + 0x431);
_free_key(ppcVar4);
}
_text(_File);
}
_text(_Dest);
iVar2 = 0;
}
else {
iVar2 = 1;
}
return iVar2;
}
На первый взгляд, декомпилированный код main() выглядит вполне обычно:
- есть объявления переменных стандартных C-типов,
- присутствуют условия, циклы, вызовы функций.
Однако при внимательном рассмотрении становится заметно, что
часть вызовов функций отображается как _text()
(в окне декомпилятора отображается как .text()).
🔍 Это означает, что Ghidra не смогла автоматически сопоставить адрес вызова с именем функции.
Вместо этого она ссылается на общую секцию кода .text.
🛠 Что делаем:
Переходим двойным кликом на первый такой вызов —
и Ghidra откроет листинг той функции, на которую указывает вызов.
Теперь мы можем:
- посмотреть дизассемблированный и декомпилированный код этой функции,
- проанализировать её поведение,
- дать осмысленное имя (например, check_password() или decrypt_string()),
- и вернуться обратно в main() — имя уже отобразится в вызове.
Повторим этот процесс для всех непонятных вызовов, чтобы восстановить структуру программы.
_Dest = (char *)_text(0x100,1);
видим, что это — всего лишь функция-обертка вокруг стандартной функции calloc(), служащей для выделения памяти под данные. Поэтому давайте просто переименуем эту функцию в calloc2(). Установив курсор на заголовке функции, вызываем контекстное меню и выбираем Rename function (горячая клавиша — L) и вводим в открывшееся поле новое название:
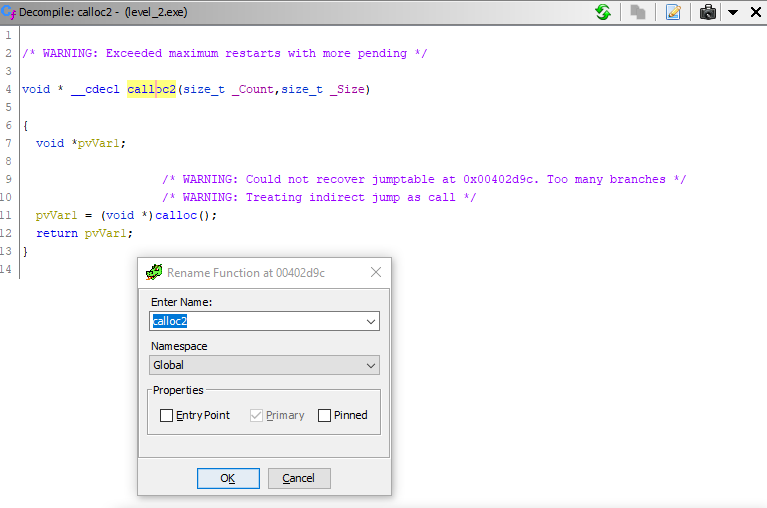
Видим, что функция тут же переименовалась. Возвращаемся назад в тело main() (кнопка Back в тулбаре или Alt + <--) и видим, что здесь вместо загадочного _text() уже стоит calloc2(). Отлично!
То же самое проделываем и со всеми остальными функциями-обертками: поочередно переходим в их определение, смотрим, что они делают, переименовываем (я к стандартным названиям C-функций добавлял индекс 2) и возвращаемся назад в основную функцию.
Постигаем код функции main()#
Ладно, с непонятными функциями разобрались. Начинаем изучать код основной функции. Пропуская объявления переменных, видим, что функция возвращает значение переменной iVar2, которое равно нулю (признак успеха функции) только в случае если выполняется условие, заданное строкой
if (_Argc == 3) { ... }
_Argc — это количество параметров (аргументов) командной строки, передаваемых в main(). То есть, наша программа «кушает» 2 аргумента (первый аргумент, мы помним, — это всегда путь к исполняемому файлу).
ОК, идем дальше. Вот здесь мы создаем C-строку (массив char) из 256 символов:
char *_Dest;
_Dest = (char *)calloc2(0x100,1); // эквивалент new char[256] в C++
Дальше у нас цикл из 3 итераций. В нем сначала проверяем, установлен ли флаг bVar1 и если да — копируем следующий аргумент командной строки (строку) в _Dest:
while (i < 3) {
/* цикл по аргументам ком. строки */
if (bVar1) {
/* инициализировать массив */
memset2(_Dest,0,0x100);
/* скопировать строку в _Dest и прервать цикл */
strncpy2(_Dest,_Argv[i],0x100);
break;
}
...
}
Этот флаг устанавливается при анализе следующего аргумента:
n_strlen = strlen2(_Argv[i]);
if (((n_strlen == 2) && (((int)*_Argv[i] & 0x7fffffffU) == 0x2d)) &&
(((int)_Argv[i][1] & 0x7fffffffU) == 0x66)) {
bVar1 = true;
}
Первая строка вычисляет длину этого аргумента. Далее условие проверяет, что длина аргумента должна равняться 2, предпоследний символ == "-" и последний символ == «f». Обрати внимание, как декомпилятор «перевел» извлечение символов из строки при помощи байтовой маски.
Десятичные значения чисел, а заодно и соответствующие ASCII-символы можно подсмотреть, удерживая курсор над соответствующим шестнадцатеричным литералом. Отображение ASCII не всегда работает (?), поэтому рекомендую глядеть ASCII таблицу в Интернете. Также можно прямо в Гидре конвертировать скаляры из любой системы счисления в любую другую (через контекстное меню --> Convert), в этом случае данное число везде будет отображаться в выбранной системе счисления (в дизассемблере и в декомпиляторе); но лично я предпочитаю в коде оставлять hex'ы для стройности работы, т.к. адреса памяти, смещения и т.д. везде задаются именно hex'ами.
После цикла идет этот код:
if ((bVar1) && (*_Dest != 0)) {
/* если получили аргументы 1) "-f" и 2) строку -
открыть указанный файл для чтения в двоичном формате */
_File = fopen2(_Dest,"rb");
if (_File == (FILE *)0x0) {
/* вернуть 1 при ошибке чтения */
perror2("Failed to open file");
return 1;
}
...
}
Здесь я сразу добавил комментарии. Проверяем правильность аргументов ("-f путь_к_файлу") и открываем соответствующий файл (2-й переданный аргумент, который мы скопировали в _Dest). Файл будет читаться в двоичном формате, на что указывает параметр «rb» функции fopen(). При ошибке чтения (например, файл недоступен) выводится сообщение об ошибке в поток stderror и программа завершается с кодом 1.
Далее — самое интересное:
/* !!! ПРОВЕРКА КЛЮЧА В ФАЙЛЕ !!! */
ppcVar3 = _construct_key(_File);
if (ppcVar3 == (char **)0x0) {
/* если получили пустой массив, вывести "Nope" */
puts2("Nope.");
_free_key((void **)0x0);
}
else {
/* массив не пуст - вывести ключ и освободить память */
printf2("%s%s%s%s\n",*ppcVar3 + 0x10d,*ppcVar3 + 0x219,*ppcVar3 + 0x325,*ppcVar3 + 0x431);
_free_key(ppcVar3);
}
fclose2(_File);
Дескриптор открытого файла (_File) передается в функцию _construct_key(), которая, очевидно, и производит проверку искомого ключа. Эта функция возвращает двумерный массив байтов (char**), который сохраняется в переменную ppcVar3. Если массив оказывается пуст, в консоль выводится лаконичное «Nope» (т.е. по-нашему «Не-а!») и память освобождается. В противном случае (если массив не пуст) — выводится по-видимому верный ключ и память также освобождается. В конце функции закрывается дескриптор файла, освобождается память и возвращается значение iVar2.
Итак, теперь мы поняли, что нам необходимо:
1) создать двоичный файл с верным ключом;
2) передать его путь в крякми после аргумента "-f"
Обзор функции _construct_key()#
Давайте сразу посмотрим на полный листинг этой функции:
char ** __cdecl _construct_key(FILE *param_1)
{
int iVar1;
size_t sVar2;
uint uVar3;
uint local_3c;
byte local_36;
char local_35;
int local_34;
char *local_30 [4];
char *local_20;
undefined4 local_19;
undefined local_15;
char **local_14;
int local_10;
local_14 = (char **)__prepare_key();
if (local_14 == (char **)0x0) {
local_14 = (char **)0x0;
}
else {
local_19 = 0;
local_15 = 0;
_text(&local_19,1,4,param_1);
iVar1 = _text((char *)&local_19,*(char **)local_14[1],4);
if (iVar1 == 0) {
_text(local_14[1] + 4,2,1,param_1);
_text(local_14[1] + 6,2,1,param_1);
if ((*(short *)(local_14[1] + 6) == 4) && (*(short *)(local_14[1] + 4) == 5)) {
local_30[0] = *local_14;
local_30[1] = *local_14 + 0x10c;
local_30[2] = *local_14 + 0x218;
local_30[3] = *local_14 + 0x324;
local_20 = *local_14 + 0x430;
local_10 = 0;
while (local_10 < 5) {
local_35 = 0;
_text(&local_35,1,1,param_1);
if (*local_30[local_10] != local_35) {
_free_key(local_14);
return (char **)0x0;
}
local_36 = 0;
_text(&local_36,1,1,param_1);
if (local_36 == 0) {
_free_key(local_14);
return (char **)0x0;
}
*(uint *)(local_30[local_10] + 0x104) = (uint)local_36;
_text(local_30[local_10] + 1,1,*(size_t *)(local_30[local_10] + 0x104),param_1);
sVar2 = _text(local_30[local_10] + 1);
if (sVar2 != *(size_t *)(local_30[local_10] + 0x104)) {
_free_key(local_14);
return (char **)0x0;
}
local_3c = 0;
_text(&local_3c,1,1,param_1);
local_3c = local_3c + 7;
uVar3 = _text(param_1);
if (local_3c < uVar3) {
_free_key(local_14);
return (char **)0x0;
}
*(uint *)(local_30[local_10] + 0x108) = local_3c;
_text(param_1,local_3c,0);
local_10 = local_10 + 1;
}
local_34 = 0;
_text(&local_34,4,1,param_1);
if (*(int *)(*local_14 + 0x53c) == local_34) {
_text("Markers seem to still exist");
}
else {
_free_key(local_14);
local_14 = (char **)0x0;
}
}
else {
_free_key(local_14);
local_14 = (char **)0x0;
}
}
else {
_free_key(local_14);
local_14 = (char **)0x0;
}
}
return local_14;
}
С этой функцией мы поступим так же, как и ранее с main() — для начала пройдемся по «завуалированным» вызовам функций. Как и ожидалось, все эти функции — из стандартных библиотек C.
Описывать заново процедуру переименования функций не буду — вернись к первой части статьи, если нужно.
В результате переименования «нашлись» следующие стандартные функции:
fread()strncmp()strlen()ftell()fseek()puts()
Соответствующие функции-обертки в нашем коде (те, что декомпилятор нагло прятал за словом _text) мы переименовали в эти, добавив индекс 2 (чтобы не возникало путаницы с оригинальными C-функциями). Почти все эти функции служат для работы с файловыми потоками.
Оно и не удивительно — достаточно беглого взгляда на код, чтобы понять, что здесь производится последовательное чтение данных из файла (дескриптор которого передается в функцию в качестве единственного параметра) и сравнение прочитанных данных с неким двумерным массивом байтов
local_14.
Давайте предположим, что этот массив содержит данные для проверки ключа. Назовем его, скажем, key_array.
Поскольку Гидра позволяет переименовывать не только функции, но и переменные, воспользуемся этим и переименуем непонятный local_14 в более понятный key_array.
Делается это так же, как и для функций: через меню правой клавиши мыши (Rename local) или клавишей L с клавиатуры.
Итак, сразу же за объявлением локальных переменных вызывается некая функция _prepare_key():
key_array = (char **)__prepare_key();
if (key_array == (char **)0x0) {
key_array = (char **)0x0;
}
К _prepare_key() мы еще вернемся — это уже 3-й уровень вложенности в нашей иерархии вызовов:
main() → _construct_key() → _prepare_key().
Пока же примем, что она создает и как-то инициализирует этот «проверочный» двумерный массив.
И только в случае, если этот массив не пуст, функция продолжает свою работу,
о чем свидетельствует блок else сразу же после приведенного условия.
Далее программа читает первые 4 байта из файла и сравнивает с соответствующим участком массива key_array.
(Код ниже — уже после произведенных переименований, в т.ч. переменную local_19 я переименовал в first_4bytes.)
first_4bytes = 0;
/* прочитать первые 4 байта из файла */
fread2(&first_4bytes,1,4,param_1);
/* сравнить с key_array[1][0...3] */
iVar1 = strncmp2((char *)&first_4bytes,*(char **)key_array[1],4);
if (iVar1 == 0) { ... }
Таким образом, дальнейшее выполнение происходит только в случае совпадения первых 4 байтов (запомним это). Дальше читаем 2 2-байтных блока из файла (причем в роли буфера для записи данных используется тот же key_array):
fread2(key_array[1] + 4,2,1,param_1);
fread2(key_array[1] + 6,2,1,param_1);
И вновь — дальше функция работает только в случае истинности очередного условия:
if ((*(short *)(key_array[1] + 6) == 4) && (*(short *)(key_array[1] + 4) == 5)) {
// выполняем дальше ...
}
Нетрудно увидеть, что первый из прочитанных выше 2-байтных блока должно быть числом 5, а второй — числом 4 (тип данных short как раз занимает 2 байта на 32-разрядных платформах).
Дальше — вот это:
local_30[0] = *key_array; // т.е. key_array[0]
local_30[1] = *key_array + 0x10c;
local_30[2] = *key_array + 0x218;
local_30[3] = *key_array + 0x324;
local_20 = *key_array + 0x430;
Здесь мы видим, что в массив local_30 (объявленный как char *local_30[4]) заносятся смещения указателя key_array.
То есть local_30 — это массив строк-маркеров, в который наверняка будут читаться данные из файла.
По этому допущению я переименовал local_30 в markers.
В этом участке кода немного подозрительной кажется только последняя строка, где присвоение последнего смещения (по индексу 0x430, т.е. 1072) выполняется не очередному элементу markers, а отдельной переменной local_20 (char*).
Но с этим мы еще разберемся, а пока — давайте двигаться дальше!
Дальше нас ожидает цикл:
i = 0; // local_10 переименовал в i
while (i < 5) {
// ...
i = i + 1;
}
Т.е. всего 5 итераций от 0 до 4 включительно. В цикле сразу начинается чтение из файла и проверка на соответствие нашему массиву markers:
char c_marker = 0; // переименовал из local_35
/* прочитать след. байт из файла */
fread2(&c_marker, 1, 1, param_1);
if (*markers[i] != c_marker) {
/* здесь и далее - вернуть пустой массив при ошибке */
_free_key(key_array);
return (char **)0x0;
}
То есть читается следующий байт из файла в переменную c_marker (в оригинальном декомпилированном коде — local_35) и проверяется на соответствие первому символу i-го элемента markers. В случае несоответствия массив key_array обнуляется и возвращается пустой двойной указатель. Далее по коду мы видим, что такое проделывается всякий раз при несовпадении прочитанных данных с проверочными.
Но тут, как говорится, «зарыта собака». Давайте внимательнее посмотрим на этот цикл. В нем 5 итераций, как мы выяснили. Это можно при желании проверить, взглянув на ассемблерный код:

Действительно, команда CMP сравнивает значение переменной local_10 (у нас это уже i) с числом 4,
и если значение меньше или равно 4 (команда JLE), производится переход к метке LAB_004017eb,
то есть к началу тела цикла.
Таким образом, условие будет соблюдаться для
i = 0, 1, 2, 3 и 4 — всего 5 итераций!
Все бы хорошо, но markers также индексируется по этой переменной в цикле,
а ведь этот массив у нас объявлен только с 4 элементами:
char *markers [4];
Значит, кто-то кого-то явно обмануть пытается :) Помните, я сказал, что эта строка наводит сомнения?
local_20 = *key_array + 0x430;
Еще как! Просто посмотрите на весь листинг функции и попробуйте отыскать еще хоть одну ссылку на переменную local_20. Ее нет! Отсюда делаем вывод: это смещение должно также сохраняться в массив markers, а сам массив должен содержать 5 элементов. Давайте исправим это. Переходим к объявлению переменной, жмем Ctrl + L (Retype variable) и смело меняем размер массива на 5:
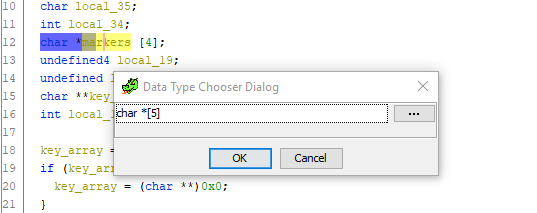
Готово. Скроллим ниже до кода присвоения смещений указателя элементам markers, и — о чудо! — исчезает непонятная лишняя переменная и все становится на свои места:
markers[0] = *key_array;
markers[1] = *key_array + 0x10c;
markers[2] = *key_array + 0x218;
markers[3] = *key_array + 0x324;
markers[4] = *key_array + 0x430; // убежавшее было присвоение... мы поймали тебя!
Возвращаемся к нашему циклу while (в исходном коде это, скорее всего, будет for, но нас это не волнует). Далее опять читается байт из файла и проверяется его значение:
byte n_strlen1 = 0; // переименован из local_36
/* прочитать след. байт из файла */
fread2(&n_strlen1,1,1,param_1);
if (n_strlen1 == 0) {
/* значение не должно быть нулевым */
_free_key(key_array);
return (char **)0x0;
}
ОК, этот n_strlen1 должен быть ненулевым. Почему? Сейчас увидишь, а заодно и поймешь, почему я присвоил этой переменной такое имя:
/* записываем значение n_strlen1) в (markers[i] + 0x104) */
*(uint *)(markers[i] + 0x104) = (uint)n_strlen1;
/* прочитать из файла (n_strlen1) байт (--> некая строка?) */
fread2(markers[i] + 1,1,*(size_t *)(markers[i] + 0x104),param_1);
n_strlen2 = strlen2(markers[i] + 1); // переименован из sVar2
if (n_strlen2 != *(size_t *)(markers[i] + 0x104)) {
/* длина прочитанной строки (n_strlen2) должна == n_strlen1 */
_free_key(key_array);
return (char **)0x0;
}
Я добавил комментарии, по которым должно быть все понятно. Из файла читается n_strlen1 байтов и сохраняется как последовательность символов (т.е. строка) в массив markers[i] — то есть после соответствующего «стоп-символа», которые там уже записаны из key_array. Сохранение значения n_strlen1 в markers[i] по смещению 0x104 (260) здесь не играет никакой роли (см. первую строку в коде выше). По факту этот код можно оптимизировать следующим образом (и наверняка так это и есть в исходном коде):
fread2(markers[i] + 1, 1, (size_t) n_strlen1, param_1);
n_strlen2 = strlen2(markers[i] + 1);
if (n_strlen2 != (size_t) n_strlen1) { ... }
Также проводится проверка того, что длина прочитанной строки равна n_strlen1. Это может показаться излишним, с учетом что данный параметр передавался в функцию fread, но fread читает не более столько-то указанных байтов и может прочитать меньше, чем указано, например, в случае встречи маркера конца файла (EOF). То есть все строго: в файле указывается длина строки (в байтах), затем идет сама строка — и так ровно 5 раз. Но мы забегаем вперед.
Далее вод этот код (который я также сразу прокомментировал):
uint n_pos = 0; // переименован из local_3c
/* прочитать след. байт из файла */
fread2(&n_pos,1,1,param_1);
/* увеличить на 7 */
n_pos = n_pos + 7;
/* получить позицию файлового курсора */
uint n_filepos = ftell2(param_1); // переименован из uVar3
if (n_pos < n_filepos) {
/* n_pos должна быть >= n_filepos */
_free_key(key_array);
return (char **)0x0;
}
Здесь все еще проще: берем следующий байт из файла, прибавляем 7 и полученное значение сравниваем с текущей позицией курсора в файловом потоке, полученным функцией ftell(). Значение n_pos должно быть не меньше позиции курсора (т.е. смещения в байтах от начала файла).
Завершающая строка в цикле:
fseek2(param_1,n_pos,0);
Т.е. переставляем курсор файла (от начала) на позицию, указанную n_pos функцией fseek(). ОК, все эти операции в цикле мы проделываем 5 раз. Завершается же функция _construct_key() следующим кодом:
int i_lastmarker = 0; // переименован из local_34
/* прочитать последние 4 байт из файла (int32) */
fread2(&i_lastmarker,4,1,param_1);
if (*(int *)(*key_array + 0x53c) == i_lastmarker) {
/* это число должно == key_array[0][1340]
...тогда все ОК :) */
puts2("Markers seem to still exist");
}
else {
_free_key(key_array);
key_array = (char **)0x0;
}
Таким образом, последним блоком данных в файле должно быть 4-байтовое целочисленное значение и оно должно равняться значению в key_array[0][1340]. В этом случае нас ждет поздравительное сообщение в консоли. А в противном случае — все так же возвращается пустой массив без всяких похвал
Обзор функции __prepare_key()#
У нас осталась только одна неразобранная функция — __prepare_key().
Мы уже догадались, что именно в ней формируются проверочные данные в виде массива key_array,
который затем используется в функции _construct_key() для проверки данных из файла.
Осталось выяснить, какие именно там данные!
Я не буду подробно разбирать эту функцию и сразу приведу полный листинг с комментариями после всех необходимых переименований переменных:
void ** __prepare_key(void)
{
void **key_array;
void *pvVar1;
/* key_array = new char*[2]; // 2 4-байтных указателя (char*) */
key_array = (void **)calloc2(1,8);
if (key_array == (void **)0x0) {
key_array = (void **)0x0;
}
else {
pvVar1 = calloc2(1,0x540);
/* key_array[0] = new char[1340] */
*key_array = pvVar1;
pvVar1 = calloc2(1,8);
/* key_array[1] = new char[8] */
key_array[1] = pvVar1;
/* "VOID" */
*(undefined4 *)key_array[1] = 0x404024;
/* 5 и 4 (2-байтные слова) */
*(undefined2 *)((int)key_array[1] + 4) = 5;
*(undefined2 *)((int)key_array[1] + 6) = 4;
/* key_array[0][0] = 'b' */
*(undefined *)*key_array = 0x62;
*(undefined4 *)((int)*key_array + 0x104) = 3;
/* 'W' */
*(undefined *)((int)*key_array + 0x218) = 0x57;
/* 'p' */
*(undefined *)((int)*key_array + 0x324) = 0x70;
/* 'l' */
*(undefined *)((int)*key_array + 0x10c) = 0x6c;
/* 152 (не ASCII) */
*(undefined *)((int)*key_array + 0x430) = 0x98;
/* последний маркер = 1122 (int32) */
*(undefined4 *)((int)*key_array + 0x53c) = 0x462;
}
return key_array;
}
Единственное место, достойное рассмотрения, — это вот эта строка:
*(undefined4 *)key_array[1] = 0x404024;
Как я понял, что здесь кроется строка «VOID»? Дело в том, что 0x404024 — это адрес в адресном пространстве программы, ведущий в секцию .rdata. Двойной клик на это значение позволяет нам как на ладони увидеть, что там находится:

Кстати, это же можно понять из ассемблерного кода для этой строки:
004015da c7 00 24 MOV dword ptr [EAX], .rdata = 56h V
40 40 00
Данные, соответствующие строке «VOID», находятся в самом начале секции .rdata (по нулевому смещению от соответствующего адреса).
Итак, на выходе из этой функции должен быть сформирован двумерный массив со следующими данными:
[0] [0]:'b' [268]:'l' [536]:'W' [804]:'p' [1072]:152 [1340]:1122
[1] [0-3]:"VOID" [4-5]:5 [6-7]:4
Готовим двоичный файл для крякми#
Теперь можем приступить к синтезу двоичного файла. Все исходные данные у нас на руках:
1) проверочные данные («стоп-символы») и их позиции в проверочном массиве;
2) последовательность данных в файле
Давайте восстановим структуру искомого файла по алгоритму работы функции _construct_key(). Итак, последовательность данных в файле будет такова:
Структура файла
4 байта == key_array[1][0...3] == «VOID»
2 байта == key_array[1][4] == 5
2 байта == key_array[1][6] == 4
1 байт == key_array[0][0] == 'b' (маркер)
1 байт == (длина следующей строки) == n_strlen1
n_strlen1 байт == (любая строка) == n_strlen1
1 байт == (+7 == следующий маркер) == n_pos
1 байт == key_array[0][0] == 'l' (маркер)
1 байт == (длина следующей строки) == n_strlen1
n_strlen1 байт == (любая строка) == n_strlen1
1 байт == (+7 == следующий маркер) == n_pos
1 байт == key_array[0][0] == 'W' (маркер)
1 байт == (длина следующей строки) == n_strlen1
n_strlen1 байт == (любая строка) == n_strlen1
1 байт == (+7 == следующий маркер) == n_pos
1 байт == key_array[0][0] == 'p' (маркер)
1 байт == (длина следующей строки) == n_strlen1
n_strlen1 байт == (любая строка) == n_strlen1
1 байт == (+7 == следующий маркер) == n_pos
1 байт == key_array[0][0] == 152 (маркер)
1 байт == (длина следующей строки) == n_strlen1
n_strlen1 байт == (любая строка) == n_strlen1
1 байт == (+7 == следующий маркер) == n_pos
4 байта == (key_array[1340]) == 1122
Для наглядности я сделал в Excel такую табличку с данными искомого файла:

Здесь в 7-й строке — сами данные в виде символов и чисел, в 6-й строке — их шестнадцатеричные представления, в 8-й строке — размер каждого элемента (в байтах), в 9-й строке — смещение относительно начала файла. Это представление очень удобно, т.к. позволяет вписывать любые строки в будущий файл (отмечены желтой заливкой), при этом значения длин этих строк, а также смещения позиции следующего стоп-символа вычисляются формулами автоматически, как это требует алгоритм программы. Выше (в строках 1-4) приведена структура проверочного массива key_array.
Генерация двоичного файла и проверка#
Осталось дело за малым — сгенерировать искомый файл в двоичном формате и скормить его нашей крякми. Для генерации файла я написал простенький скрипт на Python:
import sys, os
import struct
import subprocess
out_str = ['!', 'I', ' solved', ' this', ' crackme!']
def write_file(file_path):
try:
with open(file_path, 'wb') as outfile:
outfile.write('VOID'.encode('ascii'))
outfile.write(struct.pack('2h', 5, 4))
outfile.write('b'.encode('ascii'))
outfile.write(struct.pack('B', len(out_str[0])))
outfile.write(out_str[0].encode('ascii'))
pos = 10 + len(out_str[0])
outfile.write(struct.pack('B', pos - 6))
outfile.write('l'.encode('ascii'))
outfile.write(struct.pack('B', len(out_str[1])))
outfile.write(out_str[1].encode('ascii'))
pos += 3 + len(out_str[1])
outfile.write(struct.pack('B', pos - 6))
outfile.write('W'.encode('ascii'))
outfile.write(struct.pack('B', len(out_str[2])))
outfile.write(out_str[2].encode('ascii'))
pos += 3 + len(out_str[2])
outfile.write(struct.pack('B', pos - 6))
outfile.write('p'.encode('ascii'))
outfile.write(struct.pack('B', len(out_str[3])))
outfile.write(out_str[3].encode('ascii'))
pos += 3 + len(out_str[3])
outfile.write(struct.pack('B', pos - 6))
outfile.write(struct.pack('B', 152))
outfile.write(struct.pack('B', len(out_str[4])))
outfile.write(out_str[4].encode('ascii'))
pos += 3 + len(out_str[4])
outfile.write(struct.pack('B', pos - 6))
outfile.write(struct.pack('i', 1122))
except Exception as err:
print(err)
raise
def main():
if len(sys.argv) != 2:
print('USAGE: {this_script.py} path_to_crackme[.exe]')
return
if not os.path.isfile(sys.argv[1]):
print('File "{}" unavailable!'.format(sys.argv[1]))
return
file_path = os.path.splitext(sys.argv[1])[0] + '.dat'
try:
write_file(file_path)
except:
return
try:
outputstr = subprocess.check_output('"{}" -f "{}"'.format(sys.argv[1], file_path), stderr=subprocess.STDOUT)
print(outputstr.decode('utf-8'))
except Exception as err:
print(err)
if __name__ == '__main__':
main()
Скрипт принимает единственным параметром путь к крякми, затем генерирует в этой же директории двоичный файл с ключом и вызывает крякми с соответствующим параметром, транслируя в консоль вывод программы.
Для конвертации текстовых данных в двоичные используется пакет struct. Метод pack() позволяет записывать двоичные данные по формату, в котором указывается тип данных («B» = «byte», «i» = int и т.д.), а также можно указать порядок следования (">" = «Big-endian», "<" = «Little-endian»). По умолчанию применяется порядок Little-endian. Т.к. мы уже определили в первой статье, что это именно наш случай, то указываем только тип.
Весь код в целом воспроизводит найденный нами алгоритм программы. В качестве строки, выводимой в случае успеха, я указал «I solved this crackme!» (можно модифицировать этот скрипт, чтобы возможно было указывать любую строку).
Проверяем вывод:
